本節書摘來自華章出版社《編譯與反編譯技術實戰 》一書中的第2章,第2.2節,龐建民 主編 ,劉曉楠 陶紅偉 嶽 峰 戴超 編著,更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
目前常用的程式設計語言都已經有很多優秀的編譯器,比如c語言有gcc和icc、c++有g++和i++、java有javac和gcj。然而,即使這些常用的程式設計語言,其本身也一直在改變,即不斷地完善。因而,實作這些程式設計語言的編譯器也需要做出相應的改動。對于程式設計語言自身的改變,有的是為了彌補自身的一些缺陷,如java語言從設計至今,其體積已經增大了好幾倍;有的是為了适應新的軟體開發需求,比如為了更容易地開發大型軟體等而進行的改善。
除了那些成熟語言的改動會帶來編譯器軟體程式設計的需要外,新語言的誕生也需要程式員來完成新語言的編譯器實作工作。比如,現在不斷湧現的各種腳本語言都需要編譯器程式員來編寫這些語言的編譯器或解釋器。對于新語言的發明,有的是為了适應特殊領域的程式設計需要,比如sql(structured query language)是為關系資料庫管理系統專門設計的專用語言;有的是為了更好地利用各種系統資源(尤其是硬體資源),比如opencl(open computing language)是為了更好地開發異構平台的計算能力。作為進階語言到目标代碼的翻譯軟體(或者不同語言間的翻譯軟體)的編譯器,對它的程式設計需求一直都存在。也就是說,總有實作新的編譯器或者改動現有編譯器的需求存在。
不同的編譯器雖然實作方式各異,但編譯器的結構卻非常相似,通常是按照編譯過程的各個階段來實作相關的程式子產品。編譯過程中每個階段工作的邏輯關系如圖2-1所示,圖中的每個階段的工作由相關程式子產品承擔,但其中的符号表管理程式和錯誤處理程式則貫穿編譯過程的各個階段。這些程式子產品構成了編譯器的基本結構。
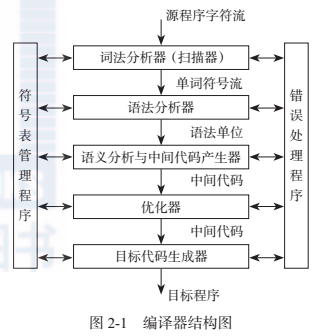
通常,編譯的階段又被分成前端和後端兩部分。前端是由隻依賴于源語言的那些階段或階段的一部分組成,往往包含詞法分析、文法分析、語義分析和中間代碼生成等階段,當然還包括與這些階段同時完成的錯誤處理和獨立于目标機器的優化。後端是指編譯器中依賴于目标機器的部分,往往隻與中間語言有關而獨立于源語言。後端包括與目标機器相關的代碼優化、代碼生成和與這些階段相伴的錯誤處理和符号表操作。這種前後端的劃分使得編譯器的設計更加清晰、合理與高效。
基于同一個前端,重寫其後端就可以産生同一種源語言在另一種機器上的編譯器,這是為不同類型機器編寫編譯器的常用做法。反過來,把幾種不同的語言編譯成同一種中間語言,使得不同的前端都使用同一個後端,進而得到一類機器上的幾個編譯器,卻隻取得了有限的成功,其原因在于不同源程式語言的差別較大,使得包容它們的中間語言龐大臃腫,難以得到高效率。但是,在反編譯的過程中,設計一種中間語言,将不同體系結構的目标代碼先翻譯成這種中間語言代碼,再由這種中間代碼反編譯為c代碼,則是一種較為有效的途徑。
![碼農隻是一碗青春飯,準程式員該怎麼規劃自己的職業生涯。[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)