本節書摘來自華章出版社《多核與gpu程式設計:工具、方法及實踐》一書中的第1章,第1.3節, 作 者 multicore and gpu programming: an integrated approach[阿聯酋]傑拉西莫斯·巴拉斯(gerassimos barlas) 著,張雲泉 賈海鵬 李士剛 袁良 等譯, 更多章節内容可以通路雲栖社群“華章計算機”公衆号檢視。
現代計算機模糊了flynn分類的界限。為了擷取更高性能,根據其測試的層次,現代計算機既是mimd也是simd。
通過小型化和改進半導體材料增加半導體數目,現代計算機目前主要有兩種趨勢。
增加片上核心數目,結合專門的simd指令集(例如,sse以及mmx、aesni等),并擴大緩存。intel x86 cpu以及intel xeon phi協處理器是最好的例子。
采用異構架構,通常是cpu+gpu,并分别處理不同任務。amd的apu(accelerated processing unit,apu)是最好的例子。intel為其cpu和內建的gpu也提供了基于opencl的計算。
然而,為什麼将cpu和gpu內建到同一塊晶片上有重要意義?在回答這個問題之前,我們先讨論gpu究竟為我們帶來了什麼。
gpu(graphics processing unit,圖形處理器),也稱為圖形加速卡,是一種快速處理大規模圖形資料(在這些資料放入顯示緩沖區之前)的專用處理器。gpu晶片的設計和傳統cpu有很大的不同。cpu将晶片的大部分用于緩存(有時是多級緩存),隻有小部分用于複雜算術和邏輯處理單元(arithmetic and logical processing unit,alu)。其中,複雜的指令解碼和預測硬體設計避免在通路記憶體資料時的挂起。
相反,gpu設計者選擇了不同的道路:少量片上緩存,大量能夠并行執行的簡單alu。之是以采用這種設計,是因為圖形處理程式比較簡單,且資料重用率低。為了能夠充分利用多個計算核心,gpu配備了高性能的記憶體總線用于通路gpu主存。
圖1-3顯示了兩者設計的不同。盡管圖1-3并沒有顯示出各部分所占晶片的真實比例,但卻非常清晰地顯示出:在cpu上緩存占絕大部分,gpu上計算邏輯單元占絕大部分。
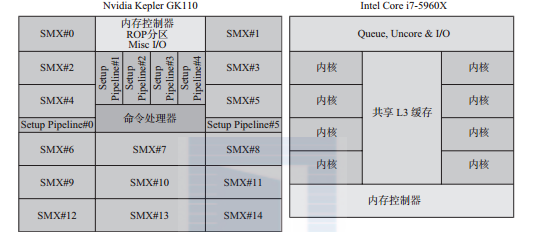
圖1-3 nvidia titan gpu和intel i7-5960x八核cpu在矽晶片上的設計框圖。該框圖并沒有顯示各部分在晶片上的真正比例,隻是顯示了計算邏輯所占的相對比例。每個smx simd塊包含64kb的緩存/共享記憶體。每個i7計算核心包含32kb的資料緩存(l1)、32kb的指令緩存(l1)、256kb的l2緩存,以及20mb的 共享l3緩存
已經證明gpu可以提供前所未有的強大計算能力。然而,cpu和gpu通常使用性能非常低的總線(如pcie)進行通信,這大大降低了異構計算系統的有效性。這主要是因為隻有将資料從cpu記憶體傳遞到gpu記憶體後,gpu才能夠處理它們。這導緻了資料規模門檻值的産生,當資料規模小于這個門檻值時,使用gpu并不是一個合适的方法。8.5.2節的案例研究對這個問題進行了詳細說明(見圖8-16中cpu和gpu平台上的執行時間與資料規模)。
現在,将cpu和gpu內建到同一個晶片上的重要意義就非常明顯了。理論上,這種設計可以更好地整合計算資源,并獲得更高的性能。但這需要等待時間的檢驗。
本章下面的内容将回顧在現代多核計算機領域中一些頗具影響力的處理器設計。雖然它們不能領先很長時間,但是它們為以後處理器的設計提供了方向。
cell be(寬帶引擎)處理器(著名的有索尼ps3的專用處理器)由索尼、東芝和ibm于2007年合作推出。cell的設計超越時代:采用主/從、異構、mimd架構。配備給ps3的cell晶片具備如下特征。
主處理器(master)是一個64位的powerpc計算核心(稱為ppe(power processing element,power處理單元)),可以運作兩個線程。主要負責運作作業系統并管理從處理器。
從處理器(worker)是8個128位的向量處理器(spe(synergistic processing element,協同處理單元))。每個spe都有256kb的片上本地記憶體(不是緩存),稱為本地存儲(local store),用于存儲資料和代碼。
spe計算核心和ppe并不相容:二者都有自己專門的simd指令集。ppe負責進行初始化并排程任務開始執行。spe間通過一條稱為eib(element interconnect bus,單元互聯總線)的高速環形互聯總線進行通信,如圖1-4所示。spe不能直接通路主存,但它可以在主存和本地存儲間進行dma傳輸。

該硬體設計的目标是最大化計算效率,但降低了易程式設計性。
cell是臭名遠揚的程式設計最困難的平台之一。
cell推出時,是市場上最強大的處理器,雙精度峰值性能可以達到102.4gflops。cell很快成為建構基于ps3叢集的“預算超級計算機”的重要元件。運作在上面的應用包括天體實體模拟、衛星成像和生物醫學應用。這裡需要注意的是,ibm建造的roadrunner超級計算機(2008~2009年世界最快的計算機),配備了12 240個powerxcell 8i處理器和6562個amd皓龍處理器。powerxcell 8i是原cell處理器的增強版本:提高了雙精度浮點運算性能。
可能是因為其程式設計難度以及gpu的發展,cell處理器已經逐漸退出曆史舞台。
kepler是nvidia專門為計算應用設計的第三代gpu架構。同之前架構相比,新架構采用了全新設計。當程式員針對這個架構編寫程式時,與傳統smp的差别非常明顯。本節将讨論使gpu具有強大計算能力的架構特征。
kepler gpu 的計算核心(cuda core)按組組織,稱為流多處理器(kepler架構稱為smx,之前架構中稱為sm,下一代maxwell架構中稱為smm)。每個kepler smx包含了可在simd模式下執行的192個計算核心。這些核心可以運作相同的指令序列但處理不同的資料。
然而,每個smx可運作屬于自己的程式。smx的總數量是差別同一系列中不同晶片的主要标志。kepler系列中性能最高的gpu是gtx titan,包含15個smx。其中,為提高産品效益,一個smx被禁用。是以gtx titan gpu總共包含14 × 192 = 2688個計算核心。這個smx在雙gpu晶片(gtx titan z)上啟用,使得該gpu的計算核心達到了驚人的5760個。amd的雙gpu晶片:r9 295x2也包含了5632個計算核心,最大限度滿足高性能發燒友的需求。
gtx titan gpu上的2688個計算核心可以提供高達4.5tflops的單精浮點運算性能和1.5tflops的雙精浮點運算性能。每個smx隻有64個雙精度計算單元(單精計算單元的三分之一)。圖1-5顯示了kepler架構的框圖。
第5章詳細讨論如何在這個架構上進行程式設計。簡單講,gpu用做協處理器,由cpu配置設定工作任務。cpu稱為主機(host)。為2688個計算核心的每一個都生成一個單獨的線程顯然是不合适的。相反,gpu程式設計環境允許調用稱為kernel的特殊函數,這些kernel運作時會有不同的内在/内置變量。事實上,每個kernel的調用可生成上萬個甚至百萬個線程,每個線程将會運作在gpu的一個計算核心上。
主機的執行順序可總結為:a)将資料發送到gpu上;b)調用kernel;c)等待接收gpu的執行結果。
為實作線程的快速執行,設計gpu片上記憶體以保持資料盡可能“接近”計算核心(每個計算核心可使用255個32位的寄存器)。為降低訪存延遲,kepler架構增加了l2緩存。然而,相對于傳統cpu的每個計算核心,l1緩存/共享記憶體還是太小。傳統cpu每個計算核心的l1緩存已經達到兆位元組數量級。共享記憶體是可尋址記憶體,對應用程式來說是不透明的,可以認為是可程式設計緩存。
這些新的架構特點表明gpu将會采用傳統cpu的設計特點。較早的gpu是沒有緩存的,每個sm的共享記憶體也限定在16kb。
另外一個新的架構特性是引入了動态并行概念。動态并行允許kernel生成額外的計算任務。為簡單起見,你可以認為這允許遞歸。但是動态并行顯然要深刻得多,因為它增加了gpu程式的複雜性。
nvidia宣稱與之前架構相比,kepler架構可提供超過3倍gflop/w的性能,但這僅僅是“蛋糕上的糖衣”。kepler架構gpu是一款采用cpu設計特點、具有非常高性能的處理器,它通過使用更多、更好的計算核心大大提高了整體計算性能。
表1-1顯示了kepler架構的功耗和能效。最高效的計算機(測量機關是tflop/kw)是piz daint,一個配備了nvidia k20x(gk110架構)gpu的計算機。
在考慮了任務生成和共享後,gpu和cpu就是“平等”的嗎?下面的讨論将會回答這個問題。
本章介紹的第三個處理器主要面向遊戲機市場:索尼的ps4。amd的apu處理器将cpu和gpu內建到同一個晶片上。盡管這不是什麼大新聞,但是最引人注目的是cpu和gpu具有統一的記憶體空間。這也就意味着cpu将任務發送到gpu,并從gpu擷取任務結果時時沒有通信開銷。同時,它還消除了gpu程式設計中的主要困擾之一:顯式(或者隐式,基于中間件)資料傳輸。
amd apu晶片實作了異構系統架構(heterogeneous system architecture ,hsa)。hsa由has基金會(hsa foundation,hsaf)開發,并作為一個開放行業标準收到amd、arm、 imagination technologies、mediatek、texas instruments、samsung electronics和qualcomm等企業支援。
hsa架構定義了兩種類型的計算核心[31]。
面向延遲的處理單元(latency compute unit,lcu),cpu的一般形式。lcu既支援cpu原有的指令集,也支援hsa中間語言(hsa intermediate language ,hsail)指令集。
面向吞吐量的處理單元(throughput compute unit,tcu),gpu的一般形式。tcu隻支援hasil指令集。tcu的目标是實作高效并行執行。
使用hsail編寫的代碼在執行之前會首先轉化為目标計算單元的原有指令集。正是由于這種相容性,cpu計算核心可以執行gpu代碼,并且hsa應用程式可以運作在任意計算平台上(不用考慮該計算平台是由lcu構成還是由tcu構成)。hsa還滿足如下特點。
共享虛拟記憶體。lcu和tcu共享頁表,簡化了作業系統的記憶體管理,并允許tcu使用虛拟記憶體。現代gpu并不支援虛拟記憶體,并受到實體記憶體大小的限制。tcu可能會産生頁表錯誤。
一緻性記憶體。記憶體堆預設實作了完全一緻性。這可以使開發者在lcu和tcu上使用軟體開發模式,如生産者–消費者模式。
使用者層次的作業隊列。每個應用程式都有一個作業排程隊列,用來存儲來自使用者空間的作業請求。這個過程作業系統kernel不需要幹預。更重要的是,lcu和tcu不但可以将作業請求存儲到自己的隊列中,而且可以存儲到對方的隊列中。cpu和gpu完全是平等的。
硬體排程。tcu引擎硬體可以在不同應用程式的任務隊列中自動切換。這個過程不需要作業系統的幹預,實作了tcu使用率的最大化。
同時,測試表明cpu計算核心和gpu計算核心的內建能提高計算的能效比。無論是對嵌入式領域還是對伺服器領域這都是非常重要的。
圖1-6顯示了amd kaveri晶片的架構框圖。hsa可以說是未來的一個發展方向,它可以将任務配置設定給最合适的計算節點,而不用忍受性能非常低的外圍總線。串行任務更适合運作在lcu/cpu計算核心上,同時并行任務更适合運作在高帶寬、高計算吞吐量的tcu/gpu計算核心上。
amd kaveri家族的a10 7850 apu可以提供856 gflops的峰值計算性能。然而,在本書寫作的時候,傳統軟體并沒有針對該硬體進行優化,進而不同充分發揮它的計算潛能。
十年來,gpu一直擁有數百個簡單計算核心,卻能夠高效完成圖像處理等特殊任務。對于一個能夠執行作業系統任務和應用軟體的通用cpu來說,要實作同樣的效果卻不容易。在過去的十年裡,已經出現了由結合這兩種不同設計優勢的晶片并且通過良好的網絡配置建構的并行計算機。這是一個成功小型化的例子。
2007年8月釋出的tilera eile74協處理器是cpu衆核模式的第一次嘗試。tile64由二維網格形式的64個計算核心組成。同時,tilera又推出了包含9、36和72個計算核心的不同版本。圖1-7顯示了包含72個計算核心的tile-gx8072。二維網格中,各個計算核心的通信信道稱為imesh。imesh由5條互相獨立的網狀網絡組成,可提供超過110tbit/s的帶寬。計算核心可進行非阻塞通信,每個時鐘周期切換一次。每個計算核心有32kb的指令l1緩存、32kb的資料l1緩存、256kb的l2緩存。所有計算核心共享18mb的一緻性l3緩存。所有計算核心通過4個ddr3控制器通路主ram。
tile-gx8072 cpu主要面向網絡(如濾波、限速)、多媒體(例如,轉碼)和雲應用市場。其中重點是網絡市場,其晶片設計包含32個1gbit/s的端口、8個10gbit/s的xaui 端口以及兩個專用壓縮加密與加速引擎(mica),證明了這一點。
在gpu模式下,tilera晶片可以作為協處理器從主cpu/主機端減少(offload)繁重的計算任務。4個pcie接口可用來加速協處理器和主機端的通信。同時,tilera晶片可以運作linux核心,是以可以作為獨立的計算平台。tilera為這個晶片提供了一個軟體開發平台:多核開發環境(multicore development environment ,mde)。mde基于開源軟體工具建構,如gnu c/c++編譯器、elicpse ide、boost、tbb(thread building block)以及其他庫。是以,它可以使用已有的工具進行多核開發,并保持對大量程式設計語言、編譯器和庫的相容性。第3章和第4章讨論的工具和技術對于針對tilera 晶片開發軟體是非常合适的。
intel踏入衆核領域的時間比較晚(2012年),但依然令人矚目。如2014年世界超級計算機top 500排行榜的前十名,就有兩台是用intel xeon phi協處理器建構的。其中,中國天河二号超級計算機位列第一。
intel xeon phi協處理器擁有61個x86計算核心,這些計算核心都是高度定制的pentium核心。這些定制包括:為了隐藏流水線停滞或者訪存延遲,每個核心可同時運作4個線程;512位寬;在simd模式下每個時鐘周期可處理16個單精度浮點數和8個雙精度浮點數的向量處理單元(vector processing unit,vpu)。同時,vpu還有一個擴充數學單元(extended math unit,emu),可用于處理複雜函數,如:倒數、平方根以及指數操作。每個計算核心有32kb的指令l1緩存、32kb的資料l1緩存、512kb的一緻性l2緩存。
計算核心間的通信采用了一個知名的通信架構,這個架構曾經應用于cell be晶片上,稱為環狀架構(如圖1-8所示)。
這個環狀架構是雙向的,由6個獨立的環構成,每個方向上各有3個。這3個環分别是一個64位元組寬的資料環和兩個窄環——一個位址環(address ring ,ad)和一個确認環(acknowledgment ring,ak)。ad環負責傳輸讀寫指令和記憶體位址,ak環用于確定l2 緩存的一緻性。
l2緩存的一緻性由分布式标記目錄(tag directory,td)管理。td含有晶片上所有l2緩存行的資訊。
當一個計算核心發生l2緩存缺失時,通過ad環發送一個位址請求到td。如果請求的資料塊在其他計算核心的l2緩存(假如為core1)中,該計算核心通過ad環将一個轉發請求發送給core1,随後,所請求的資料塊通過資料環轉發。如果所請求的資料塊沒有在片上,td将發送記憶體位址到記憶體控制器。
每種類型的環都有兩個,主要是為了保證可擴充性。測試表明:當隻使用ak環和ad環中的一個時,隻能維持30~35個計算核心的通信。
gddr5記憶體控制器存在于計算核心之間,并通過這些環進行通路。記憶體位址在這些控制器間均勻配置設定,以確定所有控制器都不會成為性能瓶頸。
硬體設計令人印象深刻。然而,如何對這61個計算核心進行程式設計呢?intel xeon phi協處理器可作為一個pcie卡,并能夠運作linux作業系統。一個專門的裝置驅動程式可使pcie總線成為一種網絡接口。這就意味着,如同和主機通過網絡互聯的其他主機一樣,協處理器也可以作為一個主機。使用者可通過ssh登入intel xeon phi協處理器。
應用程式既可以運作在主機上,也可以将它們的一部分計算任務配置設定到intel xeon phi協處理器上運作,甚至完全運作在協處理器上(這稱為native模式)。intel xeon phi協處理器可用利用所有的已有共享記憶體或者分布式記憶體工具架構。程式員可以使用多線程、openmp、intel tbb、mpi或者其他類似的工具建構程式。這同gpu相比是一個非常大的優勢,因為gpu’需要程式員掌握新的工具和技術。
最後,值得注意的是,所有衆核處理器架構都具有一個顯著的硬體特性:相對較低的時鐘頻率。如gpu(0.8~1.5 ghz),tile-gx8072(1.2 ghz),intel xeon phi(1.2~1.3 ghz)。這是将數十億個半導體內建到同一個晶片上所必須付出的代價,因為信号傳播延遲會增加。