實際項目中,經常會碰見所需資料不能從本地資料庫或硬碟中擷取而需要通過internet獲得的情況。此時,可以要求公司的it部門或資料工程師按照下圖所示的流程将原有的資料倉庫擴充,從網絡擷取處理所需要的資料再倒入公司自己的資料庫:
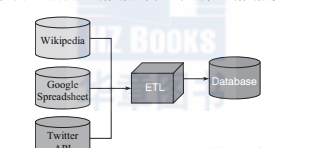
如果公司還沒有建立etl系統(抽取、轉換裝載資料),或者我們等不及it部門用幾個星期那麼長的時間來完成任務,我們也可以選擇自己動手,這樣的工作對資料科學家來說是很常見的任務,因為大多數時候我們都在開發一些原型系統然後再由軟體工程師們将其轉化為實際産品。是以,在日常工作中,我們必須要掌握一些基本技能:
用程式從網絡上下載下傳資料
處理xml和json格式的資料
從原始的html源
與api實作互動
資料篩選和資料清洗是資料分析中最乏味的部分,但卻是整個資料分析工作中最重要的步驟之一。也可以說,80%的資料分析工作其實都是在做資料清洗,在這一部分也不需要對這些垃圾資料用最先進的機器學習算法處理,是以,讀者應該確定将時間用于從資料源取得有用和幹淨的資料。
可以分兩步完成從web擷取資料集并将其導入到r會話的任務:
(1)将資料集儲存到磁盤。
(2)使用類似read.table這類标準函數完成資料讀取,例如:foreign::read.spss可以導入sav格式的檔案。

在本例中,我們在read.table指令中将f?ile參數的值設定為一個超連結,可以在處理之前下載下傳相應的文本檔案。read.table函數在背景會使用url函數,該函數支援http和ftp協定,也能處理代理伺服器,但還是存在一定的局限性。例如,除了windows系統的一些特殊情況,它一般不支援超文本安全傳輸協定(hypertext transfer protocol secure,https),而該協定卻是實作敏感資料web服務通常必須要遵守的協定。
當把這些csv檔案下載下傳下來直接導入r後,讓我們先看一下有關産品類别的回報意見:
從中可以發現大多數意見都是針對債權問題,這裡工作的重點是介紹使用curl包從某個https url下載下傳csv檔案,然後通過read.csv函數(也可以使用其他後述章節将讨論的其他函數)讀取檔案内容的過程。
curl功能已經非常強大,但對于那些沒有一定it背景的使用者來說,它的文法和衆多選項讓人難以适應。相比而言,httr包是對rcurl的一個簡化,既封裝了常見的操作和日常應用功能,同時配置要求也相對簡單。
例如,httr包對連接配接同一網站的不同請求的cookies基本上都是自動采用統一的連接配接方式,對錯誤的處理方法也進行了優化,降低了使用者的調試難度,提供了更多的輔助函數,包括頭檔案配置、代理使用方法以及get、post、put、delete等方法的使用等。另外,httr包對授權請求的處理也更人性化,提供了oauth支援。
但如果遇到了資料不能以csv檔案格式下載下傳的情況該怎麼辦呢?