無論是工業界還是學術界,都已經廣泛使用進階叢集程式設計模型來處理日益增長的資料,如mapreduce。這些系統将分布式程式設計簡化為自動提供位置感覺(locality-aware)排程、容錯以及負載均衡,使得大量使用者能夠在商用叢集上分析龐大的資料集。
大多數現有的叢集計算系統都是基于非循環資料流模型(acyclic data f?low model),從穩定的實體存儲(如分布式檔案系統)中加載記錄,一組确定性操作構成一個有向無環圖(directed acyclic graph,dag),記錄被傳入這個dag,然後寫回穩定存儲。通過這個dag資料流圖,運作時自動完成排程工作及故障恢複。
盡管非循環資料流是一種很強大的抽象方法,但有些應用仍然無法使用這種方式描述,包括:①機器學習和圖應用中常用的疊代算法(每一步對資料執行相似的函數);②互動式資料挖掘工具(使用者反複查詢一個資料子集)。此外基于資料流的架構也不明确支援這種處理,是以需要将資料輸出到磁盤,然後在每次查詢時重新加載,進而帶來較大的開銷。
目前大資料分析處理系統的發展趨勢主要有兩個方向:一種是以hadoop和mapreduce為代表的批處理(batch processing)系統,另一種是為各種特定應用開發的流處理(stream processing)系統,批處理是先存儲後處理(store-then-process),而流處理則是直接處理(straight-through processing)。
google公司于2004年提出的mapreduce程式設計模型是最具代表性的批處理模式。一個完整的mapreduce過程如圖1-2所示。
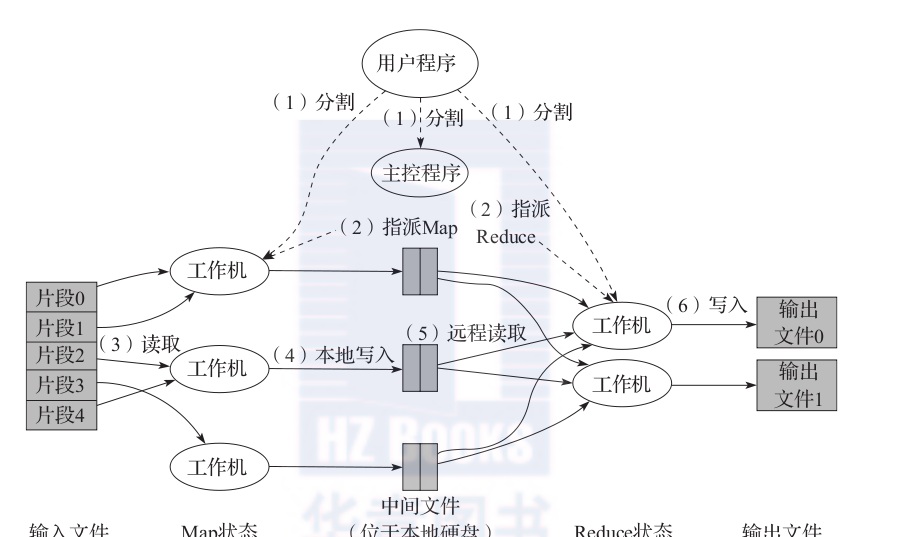
mapreduce模型首先将使用者的原始資料源進行分塊,然後分别交給不同的map任務去處理。map任務從輸入中解析出鍵/值對集合,然後對這些集合執行使用者自行定義的map函數得到中間結果,并将該結果寫入本地硬碟。reduce任務從硬碟上讀取資料之後,會根據key值進行排序,将具有相同key值的資料組織在一起。最後使用者自定義的reduce函數會作用于這些排好序的結果并輸出最終結果。
從mapreduce的處理過程我們可以看出,mapreduce的核心設計思想在于:①将問題分而治之;②把計算推至資料而不是把資料推至計算,有效避免資料傳輸過程中産生的大量通信開銷。mapreduce模型簡單,且現實中很多問題都可用mapreduce模型來表示。是以該模型公開後立刻受到極大的關注,并在生物資訊學、文本挖掘等領域得到廣泛應用。
無論是批處理還是流處理,都是大資料處理的可行思路。大資料的應用類型很多,在實際的大資料進行中,常常并不是簡單地隻使用其中的某一種,而是将二者結合起來。網際網路是大資料最重要的來源之一,很多網際網路公司根據處理時間的要求将自己的業務劃分為線上(online)、近線(nearline)和離線(off?line),比如著名的職業社交網站linkedin。這種劃分方式是按處理所耗時間來劃分的。其中線上的處理時間一般為秒級,甚至是毫秒級,是以通常采用上面所說的流處理;離線的處理時間可以以天為基本機關,基本采用批處理方式,這種方式可以最大限度地利用系統
i/o;近線的處理時間一般為分鐘級或者是小時級,對處理模型并沒有特别的要求,可以根據需求靈活選擇,但在實際中多采用批處理模式。
流處理的基本理念是資料的價值會随着時間的流逝而不斷減少,是以盡可能快地對最新的資料作出分析并給出結果是所有流資料處理模式的共同目标。需要采用流資料處理的大資料應用場景主要有網頁點選數的實時統計、傳感器網絡和金融中的高頻交易等。

流處理的處理模式将資料視為流,源源不斷的資料組成了資料流。當新的資料到來時就立刻處理并傳回所需的結果。圖1-3是流進行中基本的資料流模型。
資料的實時處理是一個極具挑戰性的工作,資料流本身具有持續達到、速度快且規模巨大等特點。為了確定分布式資料流的實時處理,需要對資料流的傳輸和模型進行說明。①資料流傳輸。為保證明時、完整且穩定地将資料流傳輸到處理系統,一般可通過消息隊列和網絡socket傳輸等方法完成,以保證将資料發送至每個實體節點,為資料處理提供保障。利用消息隊列的方式進行資料采集和傳輸是較為常用的一種方法,常見的消息隊列産品有facebook的scribe、linkedin的kafka和cloudera的flume等。
②資料流模型。在查詢處理過程中,由于資料流的來源不同,需要針對不同的資料源制訂不同的資料樣式。一般來講,通用的資料流管理系統支援關系型資料模型,資料定義語言是基于關系型的原子類型,便于以屬性和元組的形式劃分和發送資料;針對特殊領域的資料流管理系統,可根據領域資料的特點設計基于對象類型的複合資料類型。