本文偏向與實操層面的為大家介紹,如何基于阿裡雲數加streamcompute、datav快速建構網站日志實時分析。
【什麼場景适合用流計算】
流計算提供了針對流式資料實時分析的一站式工具鍊,對于大量流式資料存在實時分析、計算、處理的邏輯可以考慮通過流計算該任務。舉例如下:
1. 針對實時營銷活動,需要實時擷取活動流量資料分析以了解活動的營銷情況,此時可以上流計算。
2. 針對物聯網裝置監控,需要實時擷取裝置資料進行實時災難監控,此時可以上流計算。
3. 對于手機app資料實時分析,需要實時了解手機裝置的各類名額情況,此時可以上流計算
【使用前須知】
為保障本教程的順利的進行,須知曉如下使用前提:
具備阿裡雲賬号(淘寶及1688帳号可直接使用會員名登入);
下載下傳并安裝logstash的datahub output插件。
【實作的業務場景】
資料來源于某網站上的http通路日志資料,基于這份網站日志來實作如下分析需求:
實時統計并展現網站的pv和uv,并能夠按照使用者的終端類型(如android、ipad、iphone、pc等)分别統計。
實時統計并展現網站的流量來源。
從ip中解析出region或者經緯度在地圖上進行展示。
【說明】浏覽次數(pv)和獨立訪客(uv)是衡量網站流量的兩項最基本名額。使用者每打開一個網站頁面,記錄一個pv,多次打開同一頁面pv 累計多次。獨立訪客是指一天内,通路網站的不重複使用者數,一天内同一訪客多次通路網站隻計算1 次。referer 可以分析網站通路來源,它是網站廣告投放評估的重要名額,還可以用于分析使用者偏好等。
【操作流程概述】
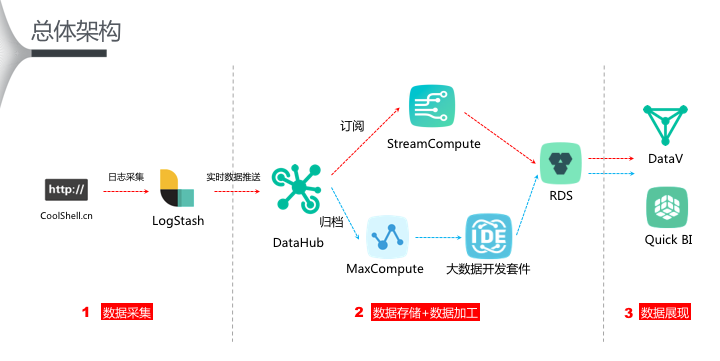
如上圖所示,紅色箭線部分為流式資料處理部分,主要拆解如下:
l 配置logstash,将網站産生的日志實時采集至datahub。
l 申請開通datahub,建立項目project及topic(datahub服務訂閱和釋出的最小機關)。
l 開通streamcompute,建立項目project及注冊資料輸入源(datahub)和輸出源(rds),并建立流任務(stream sql任務)。
l 上一步驟中關于輸出源rds的配置,需要事先購買rds for mysql資源。
l 申請開通datav,建立rds資料源并建立datav項目進入大屏制作。
【資料結構設計】

datahub topic: 分别建立topic為:coolshell_log_tracker、coolshell_log_detail、coolshell_log_fact。
rds:分别建立table為:
adm_refer_info、
adm_user_measures、
flyingline_coordinates ã
【網站日志實時解析】
配置前須知
阿裡雲流計算為了友善使用者将更多資料采集進入datahub,提供了針對logstash的datahub output插件。
logstash安裝要求jre 7版本及以上,否則部分工具無法使用。
操作步驟
步驟2 通過如下指令解壓即可使用:
$ tar -xzvf logstash-2.4.1.tar.gz
$ cd logstash-2.4.1
<code>$ {log_stash_home}/bin/plugin install --local logstash-output-datahub-1.0.0.gem</code>
步驟4 下載下傳geoip解析ip資料庫到本地。
wget http://geolite.maxmind.com/download/geoip/database/geolitecity.dat.gz
步驟5 解壓到目前路徑并移動到logstash具體路徑下。
步驟6 配置logstash任務.conf,示例如下:
配置檔案為coolshell_log.conf。具體datahub topic資訊可詳見 資料存儲 章節。
步驟7 啟動任務示例如下:
【資料表建立】
附rds建立表ddl:
【流式資料處理】
注冊資料存儲包括datahub和rds:
按照資料鍊路圖中來編寫處理邏輯(附核心代碼):
【處理邏輯1】
【處理邏輯2】
【處理邏輯3、4、5、6】
【上線stream sql】
上線任務後需要對任務進行啟動:
【建立大屏】
現在datav中建立rds資料源:
然後根據如下拖拽如元件配置簡單的sql:
本文主要講述了實時場景的鍊路,後續也會将日志歸檔到maxcompute然後通過quick bi進行報表分析。敬請期待!