redis支援migrate key的指令,支援從源redis節點遷移key到目标節點上,目标節點再執行restore指令,将資料加載進記憶體中。以800mb,資料類型為zset(skiplist) 的 key為例,測試環境為本地開發機上兩台redis,忽略網絡的影響。原生的redis 在restore時執行需要163s,優化後的redis執行需要27s。
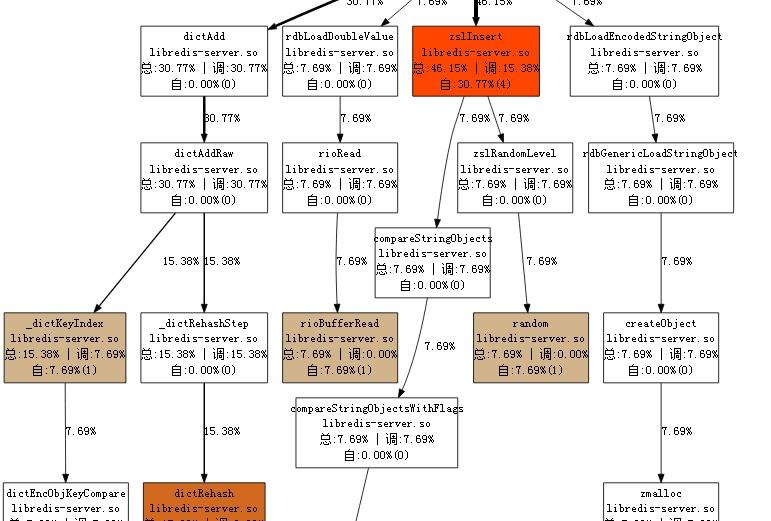
通過扁鵲工具分析,可以看到cpu的運作情況如下:
檢視源碼可知,migrate 周遊出來的zset 中的hashtable值和score,序列化之後打包給目标節點。
目标節點在反序列後重新構造了zset的結構,包括zslinsert, dictadd 等操作。當資料量越大時,重構的代價也就越大。
已知瓶頸在重構資料模型,是以優化的思路就是将源節點的資料模型也一并序列化打包給目标節點。目标節點解析後預構造出記憶體,再按解析後的member填鴨進去即可。
zset 可以說是redis中最為複雜的資料結構,以zset為例,闡述如何優化。
zset 由兩個資料結構組成,一個是hashtable 結構的dict,存儲的是每個member的值及對應的score,另一個是skiplist的zsl,按序排列每個member。如圖所示:

redis中,zset的dict 和 zsl 中member 和score的記憶體是共享的,兩種結構,一份記憶體。如果在序列化中描述一份資料兩種索引成本反而更高。
再細看cpu的性能消耗,hashtable部分更多消耗在計算index, rehash(即預配置設定的hash table的size不滿足時,需要使用一個更大size的hashtable,将舊的table挪到新的table中),compare key(在連結清單中周遊判斷key是否已經存在)。
基于此,在序列化時帶上最大的hashtable的size,restore時指定生成size大小的dict table,去掉rehash。
restore zsl 結構,反序列化出member,score,重新計算member的index,插入指定index的table中,因為周遊出來的zsl不會有出現key沖突的情況,省去compare key,直接将相同index的member接入到連結清單中。
zsl 有多層結構
描述的難點在于每一層上的zskiplistnode總共的level層不知道,并且需要描述每一層的前後節點關系,同時需要考慮相容性。
綜合以上考慮,決定從整個zsl最高的level層次周遊,序列化的格式是:
level | header span | level_len | [ span ( | member | score ... ) ]
level : 第幾層的資料
header span : header 節點在該層上的span值
level_len : 該層上總的節點數
span : 節點在該層上的span值
member | socre :因為在0層以上的level 有備援的節點,通過span值相加可以判斷是否是備援節點,備援節點則不序列化member | score, 非備援節點帶上member | score。反序列時的算法亦然。
如此zset的資料模型描述完成。對restore的性能更快,但是同時會消耗更多的帶寬,多出來的帶寬是描述節點的字段。800mb的資料,優化後比優化前多出20mb資料。