2016雲栖大會·北京峰會于8月9号在國家會議中心拉開帷幕,在雲栖社群開發者技術專場中,來自阿裡雲技術專家曹龍(封神)為在場的聽衆帶來《deep dive into spark》精彩分享。
關于分享者
演講内容架構
資料處理技術介紹
spark 介紹
spark plus
spark 應用場景
spark 在雲上
spark 常見的問題
e-mapreduce大資料平台
演講主要内容
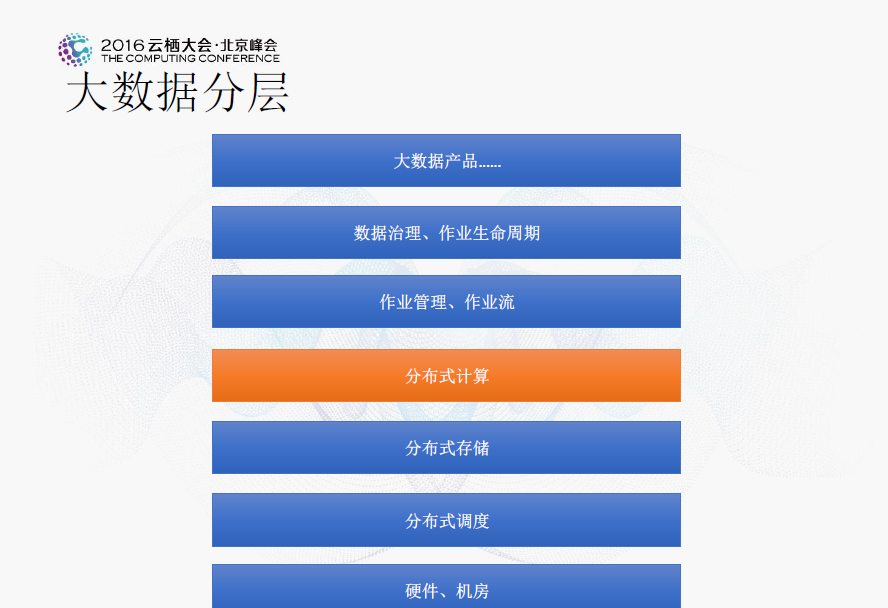
大資料通常自上而下分為大資料産品、資料治理/作業生命周期、作業管理/作業流、分布式計算、分布式存儲、分布式排程、硬體/機房七層。本次演講的重點在于分布式計算層。
在以時間、資料量的坐标抽上列出目前引擎大緻擅長處理資料的坐标,應該還需要加上資料複雜度、成本等次元,才能更好的展現側重點,這裡不列出。沒有哪個軟體能解決所有的問題,能解決問題也是在一個範圍内,即使是spark、flink等。目前存在有意思的事情是:greenplum類似的mpp引擎想處理大資料的需求,hadoop等被定位為大資料的引擎也想解決小資料的問題(列式存儲、或者也加入一些索引)。圖中右上角的想往左邊靠,減少延遲,圖中左下角的想往上面靠,增大能處理的資料量。

db/mpp跟hadoop引擎相對比,兩者有很大的不同,具體差異參見下圖。從硬體、容錯、排程模型及衡量标準方面各自都側重一方面,對于事務性、index等,hadoop引擎目前是不支援的。另外mpp其實也在跟hadoop在融合,比如mpp on hdfs,spark on db也在實作。
hadoop生态計算引擎目前包括:hadoop mapreduce、spark/spark 2.0、tez、flink等,這裡從計算模型,各自的特點分為了1g、2g、3g、3.8g、4g,分别代表其理論先程序度。spark理論上并不是最先進的,但是目前來講應該是最适合的。
spark 介紹
下圖展示的是spark的趨勢,可以清楚地看到,在2012年至2013年間,spark有了一個很大的轉折,在那時候,阿裡也在逐漸使用spark,到今天,spark和hadoop逐漸持平發展。
spark 提供 sql、機器學習庫 mllib、流計算 streaming 和圖計算 graphx,同時也支援 scala、java、python 和 r 語言開發的基于 api 的應用程式。下圖顯示的是spark 1.0的基礎架構。
下圖是spark 2.0的基礎架構,對比于1.0,spark 2.0主要聚焦于兩個方面:(1)對标準的sql支援。(2)統一的dataframe和dataset(邏輯執行計劃)api。特别的以後一些的api都是基于catalyst的。
完整的spark鍊路如下圖所示,主要包括sql、rdd、task、thread。
常見的spark puls有:spark部署模式、spark彈性伸縮、spark+aliuxio(加速)、與業務系統融合(解耦,業務系統與大資料系統)、spark+資料庫服務、spark+存儲格式。
其中彈性伸縮讓spark上大叢集成為了可能;在spark+存儲格式中:1 tb資料的存儲相對比文本節省了将近 75%;性能按照不同的query提高從幾倍到數十倍不等。
常見的spark應用場景包括:etl、機器學習、流式計算、即時查詢。
其中,在etl場景中,通過spark sql 、spark api、dataset實作圖檔、語音、視訊等資訊的線上/離線資料抽取、轉化為結構化資料,便于後續分析處理。
spark 在雲上
spark在雲上的最佳實踐是将存儲與計算分離,下圖展現了自建ecs和emp+oss的存儲計算分離成本估算對比情況。
下圖展示的是自建ecs和emp+oss的terasort時間對比,這裡自建ecs配置參數是1 master 4cpu 16g和8 slave 4cpu 16g;emr+oss的參數是1 master 4cpu 16g和8 slave 4cpu 16g。
下圖展現了自建ecs和emp+oss的存儲計算分離性能對照圖,左邊是ecs自建,右邊是emp+oss。
spark常見的問題包括卡住、記憶體溢出、gc頻繁。
随着spark 2.0的釋出,spark逐漸趨于成熟,未來spark的發展方向:
支援ansi sql
性能接近mpp資料倉庫
一切基于優化(catalyst)
新硬體的支援,比如:大記憶體、gpu
更加友好的支援雲
e-mapreduce 是運作在阿裡雲平台上的開源大資料處理系統解決方案。它能夠讓使用者将apache hadoop和apache spark等開源引擎運作在阿裡雲的雲平台上,提供給使用者在雲上的分析和處理大資料的平台。我們提供管控系統、運維系統及後續的專家系統幫使用者解決自動化的問題,并提供專家服務幫助客戶解決疑難雜症。
e-mapreduce産品的架構如下圖所示:
從上圖可以看出,spark生态是e-mapreduce引擎的一部分,我們還有支援了其它非常多的引擎,如在離線處理、線上流式、線上存儲及互動式查詢等各個方面。基于我們過去許多年在阿裡内部的沉澱,在易用性、成本、性能、運維等各方面具有阿裡開源大資料的技術能力,歡迎大家使用。