在實際的生産環境中, 當資料庫越來越多, 越來越大.
備份可能會成為比較大的問題, 傳統的邏輯備份對于大的資料庫不适用(因為備份和還原可能是比較耗時的, 而且也不能回到任意時間點, 還會造成資料庫膨脹(長時間repeatable read隔離級别), 好處是可以跨平台恢複, 可選恢複表等).
而基于xlog的增量備份, 雖然備份可以線上進行,同時支援恢複到任意時間點,但是恢複需要apply從基礎備份到恢複目标之間所有産生的xlog,如果基礎備份做得不頻繁,那麼恢複時可能需要apply的xlog檔案數很多,導緻恢複時間長。
如果頻繁的執行全量基礎備份可以解決恢複時間長的問題,又會帶來一系列問題,占用跟多的空間、占用更多的備份帶寬、消耗資料庫讀資源、備份時間長等問題。
這些問題随着資料庫變大而放大。
有什麼好的解決方案麼?
為了解決增量備份的問題,我們可能馬上會想到類似oracle的增量備份,隻需要上次備份以來的變更或新增的資料塊。
postgresql目前也支援這種備份方式,我會在下一篇文檔中介紹。
除了資料庫本身支援的塊級别增量備份,我們還可以使用檔案系統的快照來支援塊級增量備份,例如zfs或者btrfs。
zfs在這裡主要用到它的壓縮, 去重和snapshot功能.
使用zfs可以減少存儲空間, 加快恢複速度.
可以放在crontab定時執行, 例如2小時1次.
最近在寫一個集中式的postgresql基于塊的增量備份的case,剛好完美的解決了大執行個體的備份難題.
集中備份主機環境
歸檔主機配置(本例歸檔主機和備機主機使用同一台主機)
配置zfs, 開啟壓縮, 同時注意寫性能至少要和網卡帶寬相當, 否則容易造成瓶頸.
一旦造成瓶頸, 可能導緻主庫xlog堵塞膨脹(因為歸檔完成的xlog才可以重用或被删除).
考慮到寫居多, 是以考慮加一個性能好的ilog裝置. l2arc沒必要加.
zpool使用raidz1+ilog+spare的模式.
raidz1盤的數量9=2^3+1, 實際上本例使用的盤數11(當然你可以多vdev strip的模式例如12塊盤分4組vdev raidz1 3+3+3+3, 可用容量為8塊盤).
1個ilog因為這個裝置底層使用了raid1 的模式, 是以沒有再次mirror. 如果底層是jbod模式的話, 建議用mirror防止ilog資料損壞. 1塊hot spare.
扇區大小選擇4kb.
配置zpool 根 zfs預設選項, 後面建立的zfs可以繼承這些選項.
建立歸檔目錄, 日志目錄, pghome目錄等.
配置postgresql歸檔, 例如rsync服務端, nfs, ftp 等, 如果使用nfs注意固定一下nfs端口.
本文以nfs為例介紹歸檔配置.
配置nfs端口固定
配置nfs目錄, 每個pg叢集一個目錄, 存放該叢集的歸檔檔案.
開啟nfs服務, or service nfs reload.
( (注意如果主節點有流複制的ha的話, 主備都需要配置) )
配置nfs挂載, 資料庫啟動使用者的權限, 如果有必要的話, 可以配置nfs逾時.
推薦以下配置
另一種是配置在啟動腳本裡面
主節點叢集配置歸檔指令(如果以前沒有開啟歸檔的話, 需要重新開機資料庫開啟歸檔) (注意如果主節點有流複制的ha的話, 主備都需要配置)
首先要配置sudo, 因為nfs挂載過來權限後面需要調整, 是以最好使用sudo以免歸檔和還原失敗.
配置歸檔和還原指令 :
主備同時配歸檔沒有問題(因為原版的postgresql備節點不會觸發歸檔), 除非你像這樣改了pg代碼.
<a href="http://blog.163.com/digoal@126/blog/static/163877040201452004721783/">http://blog.163.com/digoal@126/blog/static/163877040201452004721783/</a>
配置zfs(同歸檔存儲節點的配置)
考慮到寫居多, 是以需要加一個ilog裝置. l2arc沒必要加.
zpool使用raidz1+ilog+spare的模式, 盤的數量11+1+1, 1個ilog因為這個裝置底層使用了raid1 的模式, 是以沒有再次mirror.如果底層是jbod模式的話, 建議用mirror防止ilog資料損壞.
設定zpool預設zfs的屬性, 以便建立後面的zfs繼承這些屬性(同上). 主要修改壓縮和檔案通路時間.
因為是集中式的流複制場景, 是以存儲的io可能會比較大, 前面我們考慮了使用ilog來提高寫性能, 同時我們還需要考慮資料壓縮, 節約存儲空間, 我們這裡選擇lz4壓縮算法, 速度和壓縮比比較均衡.
去重(dedup)暫時不開, 因為需要消耗大量的記憶體, 具體耗多少記憶體, 可以使用zdb -s zp1來評估.
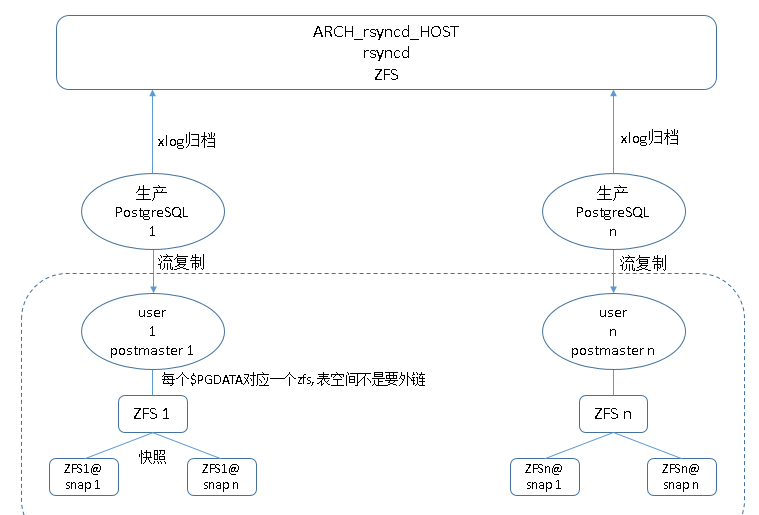
建立資料庫叢集對應的zfs, 一個資料庫叢集對應一個zfs, 友善我們做zfs snapshot.
命名的話, 最好結合ip和資料庫的業務名稱.
配置網卡綁定(可選), 當帶寬不夠時可選.
參考
<a href="http://blog.163.com/digoal@126/blog/static/163877040201451823232145/">http://blog.163.com/digoal@126/blog/static/163877040201451823232145/</a>
如果所有主資料庫節點産生xlog的速率超過了網卡速率, 那麼建議多網卡綁定來解決網絡帶寬的問題.
(這樣的話所有的主節點pg_hba.conf的配置都指向這個虛拟ip, 以後遷移的話, 虛拟ip遷移走, 主節點的pg_hba.conf可以不用修改, (當然如果有dns的話, 也可以配置為主機名, 就沒有這麼麻煩了))
主節點配置pg_hba.conf允許虛拟ip過來的流複制協定連接配接.
一個使用者對應一個主節點, 每個使用者編譯各自的pg軟體(因為不同的執行個體,pg軟體編譯參數可能不一樣).
編譯與主節點一緻的postgresql軟體以及插件.
編譯項見主節點的pg_config輸出或檢視源編譯檔案的config.log.
例如 :
或
自定義的插件檢視, 可以檢視$pghome/lib目錄或, 最好是拿到資料庫檔案, 翻閱編譯過的插件, 新增的動态連結庫等.
例如
配置環境如下
在備份機, 所有的表空間都不使用軟連結, 直接使用$pgdata/pg_tblspc/oid目錄.
recovery.conf, postgresql.conf, (注意監聽端口的修改, 因為一台主機開啟多個standby, 避免端口沖突., 注意pg_log位置的修改. )
配置.pgpass ,設定流複制秘鑰
配置主節點pg_hba.conf, 允許備機的虛拟ip通路. (如果是流複制叢集的話, 主備兩邊都需要配置.)
開啟standby進行恢複, (随便使用open模式hot_standby = on 或 recovery模式hot_standby = off)
recovery.conf中添加 :
確定當主備網絡中斷時可以從歸檔繼續恢複
1. nfs 監控
2. nfs 端口監控
3. pitr上所有資料庫叢集的端口監控
4. pitr上所有資料庫叢集的stream wal receiver程序監控
5. 流複制延遲監控
6. 歸檔檔案時間戳監控, 發現歸檔失敗.
7. 恢複監控, 10分鐘内如果沒有建立的xlog檔案則告警.
vi /usr/local/nagios/libexec/mon_pitr.sh
因為pgdata是700的權限, 是以find這些目錄會受到權限限制, nagios監控使用者會報錯, 是以可以把這個指令加入sudo
1. 如果歸檔失敗, 主節點的pg_xlog目錄會暴增, 不能rotate. 是以pg_xlog目錄盡量配置大一些, 同時加上監控.
當然更靠譜的方法是使用多個歸檔路徑, 一個失敗就歸檔到下一個路徑. 但是需要注意調小一點逾時. 否則每次歸檔都要等待逾時也會造成擁堵.
2. 對nfs主機需要添加監控, 以防有問題.
3. 對于主節點有流複制ha的情況, nfs挂載, 歸檔都需要在主備節點同時配置. nfs的exports也需要配置允許主備節點的ip rw.
4. 因為是集中的歸檔和流複制是以務必注意網絡帶寬是否夠用. 不夠用的話, 可以考慮多網卡綁定增加帶寬.
5. nfs端口固定後, 可以防止nfs伺服器重新開機後或服務重新開機後, nfs client需要重新mount的問題. 或者防火牆精确控制的問題.
8. 關于zfs的寫入優化. 參見末尾
9. 關于zfs的壓縮優化. 參見末尾
10. 多資料庫叢集的路徑沖突問題. 不使用pg_tblspc/link, 直接一個叢集一個zfs dataset來解決.
11. 開啟歸檔後, standby節點參數修改, 如wal keep 改小, listen port 修改避免沖突, log_directory目錄位置修改.等
12. zpool建立時, 務必裝置名建議by-id, 放在因為裝置别名變更後導緻無法使用.
例如把zil和spare裝置換成uuid.
13. slog的大小4g 上下就足夠了.
14. 作業系統核心參數稍作調整.
15. 不建議使用linux, 因為zfs在linux下有一定的性能問題, 可以考慮freebsd. 參見
<a href="http://blog.163.com/digoal@126/blog/static/16387704020145253599111/">http://blog.163.com/digoal@126/blog/static/16387704020145253599111/</a>
<a href="http://blog.163.com/digoal@126/blog/static/1638770402014526992910/">http://blog.163.com/digoal@126/blog/static/1638770402014526992910/</a>
<a href="http://blog.163.com/digoal@126/blog/static/16387704020145264116819/">http://blog.163.com/digoal@126/blog/static/16387704020145264116819/</a>
16. 集中式的配置standby節點可能導緻資源不夠用, 例如shared_buffer, 要調小的話同時還需要調小connection_max 等關聯參數, 而這些參數在postgresql.conf - hot_standby=on 的情況下, 需要檢測是否大于等于上遊節點的參數, 是以建議standby節點的hot_standby=off, 然後就不需要檢測了, 然後就可以調小shared_buffer, connection_max等了.
如果要打開hot_standby=on, 那麼再調會connection_max 等檢測項即可.
17. 原來如果主節點已是流複制的ha節點, 可以把recovery.conf或recovery.done修改一下.
因為預設情況下standby節點不會産生archive, 是以不必擔心重複的archive檔案.
是以雙方挂載對方的pgarch目錄到pgrestore即可.
如果想讓standby也産生archive, 參考我前面寫的blog, 修改一些源代碼.
重新開機流複制備庫生效.
9. man nfs 逾時
![【MySQL資料庫】資料庫索引事務1.索引2.事務[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)