x表将資料寫入a,這時候a的id是自增長的 a再将自己的自增長的id(發号器),寫入到 b, 注意是指定id寫入。insert into b(id) values(xx); 同時也将資料寫入到c
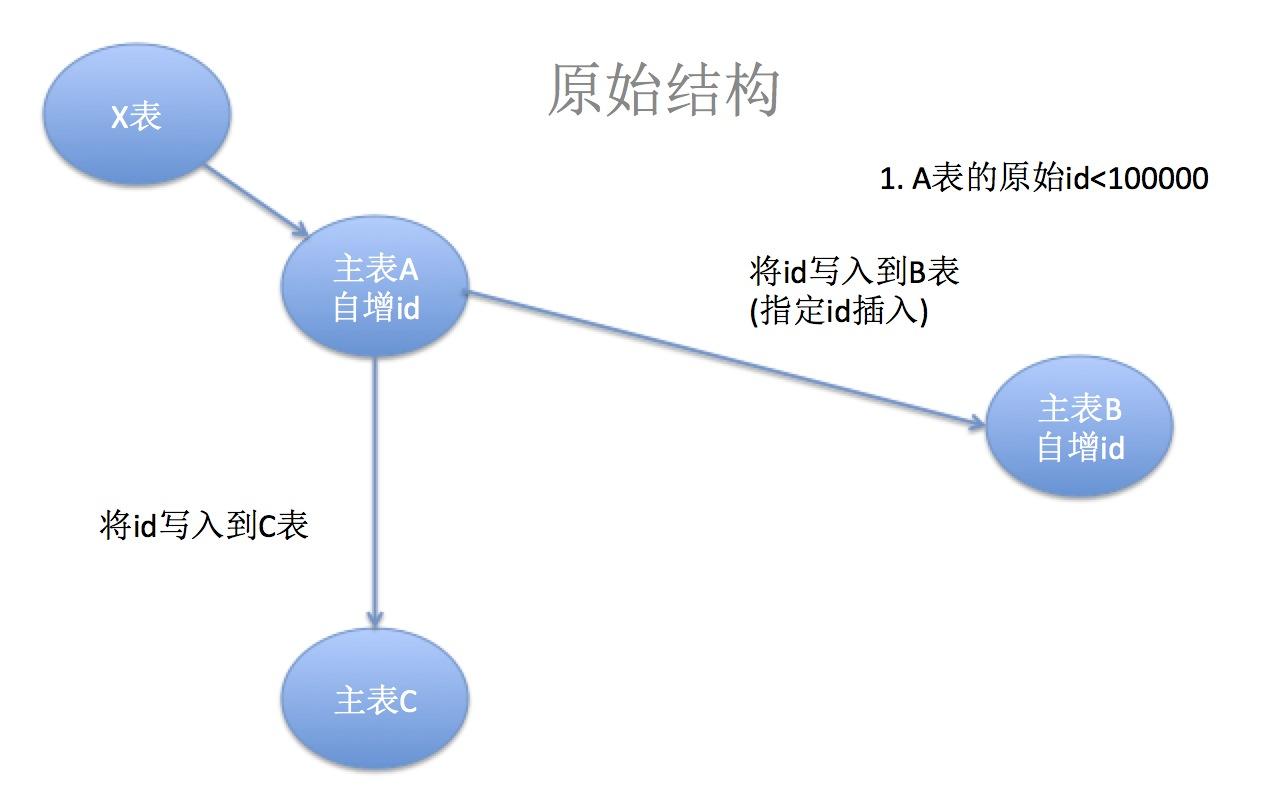
主表a将發号器id寫入c (id 在一個小區間增長: 1 ~ 100000) 主表b将發号器id也寫入c (id 在一個大區間增長: 10000000 ~ ? ) 很多人疑惑的是:為什麼一開始id不區分開來呢? 因為一開始業務沒有拆分,需要保證a,b一緻。直到某個階段,才将b設定alter table b auto_increment = 10000000 這個時候,由于指定id寫入的原因,a,b的id還是一緻的,直到x表分發資料到不同表。如:xx寫入a,yy寫入b,這個時候由于a,b的auto_increment不一樣,是以id就會有所區分(a的id自增長在小的區間,b的id自增長在大的區間)。

那麼問題就來了,如果這時候b的auto_incrememt再次變回到小區間1 ~ 100000,會導緻什麼問題呢? 問題嚴重啦: 這時候由于a,b 都往c表寫同一個區間的資料,會導緻很多髒資料,結果就悲劇了咯。。。 真實場景重制如下
問題的關鍵處在auto_increment變小
alter table xx auto_increment = yy; truncate table restart mysql
手動插入一條資料到b,讓其最大值在10000000+1, 這樣就不會出問題。
一張剛建立的innodb表,目前自增是1. 插入3條記錄後,auto_increment=4. 然後再删除掉這三條記錄,auto_increment=4 沒變 關閉mysql,當mysql再次起來的時候,會發現auto_increment值從4,變成1
業務不要依賴auto_increment值,它并不是總是遞增