x表将数据写入a,这时候a的id是自增长的 a再将自己的自增长的id(发号器),写入到 b, 注意是指定id写入。insert into b(id) values(xx); 同时也将数据写入到c
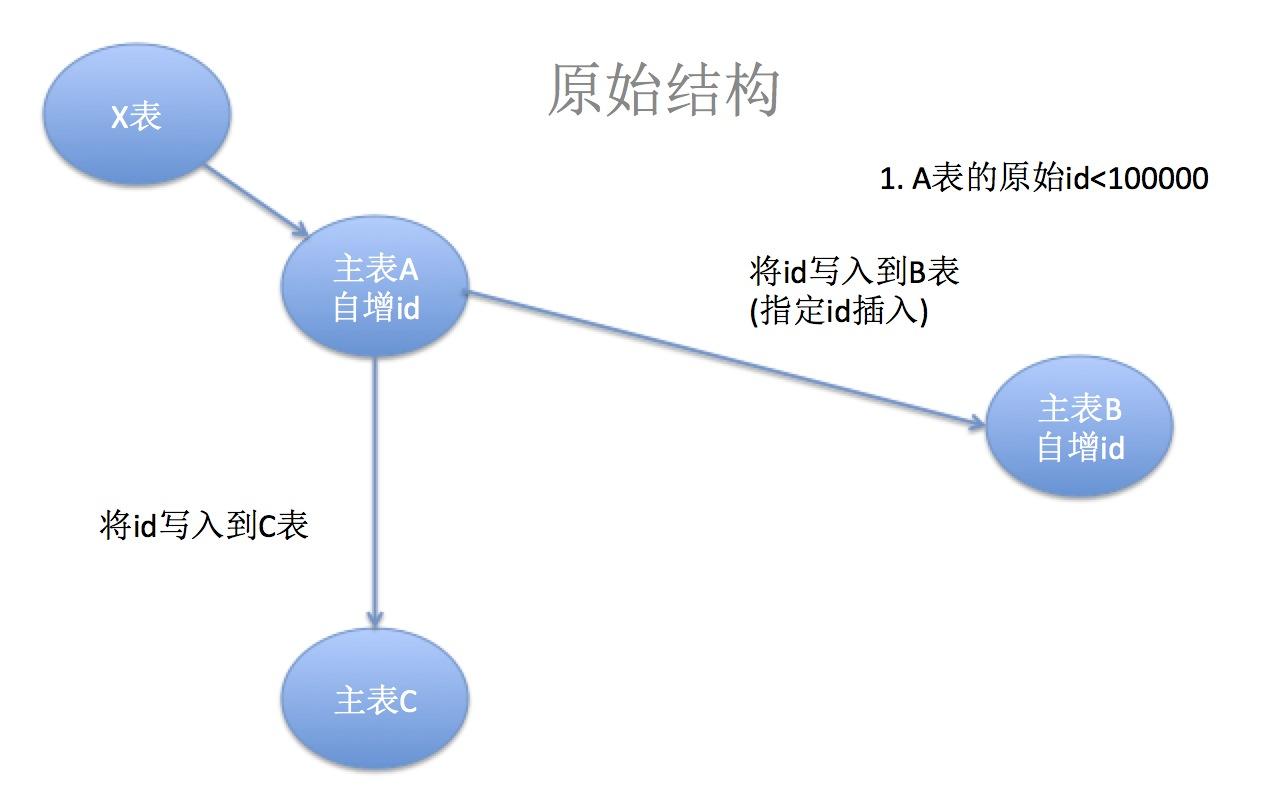
主表a将发号器id写入c (id 在一个小区间增长: 1 ~ 100000) 主表b将发号器id也写入c (id 在一个大区间增长: 10000000 ~ ? ) 很多人疑惑的是:为什么一开始id不区分开来呢? 因为一开始业务没有拆分,需要保证a,b一致。直到某个阶段,才将b设置alter table b auto_increment = 10000000 这个时候,由于指定id写入的原因,a,b的id还是一致的,直到x表分发数据到不同表。如:xx写入a,yy写入b,这个时候由于a,b的auto_increment不一样,所以id就会有所区分(a的id自增长在小的区间,b的id自增长在大的区间)。

那么问题就来了,如果这时候b的auto_incrememt再次变回到小区间1 ~ 100000,会导致什么问题呢? 问题严重啦: 这时候由于a,b 都往c表写同一个区间的数据,会导致很多脏数据,结果就悲剧了咯。。。 真实场景重现如下
问题的关键处在auto_increment变小
alter table xx auto_increment = yy; truncate table restart mysql
手动插入一条数据到b,让其最大值在10000000+1, 这样就不会出问题。
一张刚创建的innodb表,目前自增是1. 插入3条记录后,auto_increment=4. 然后再删除掉这三条记录,auto_increment=4 没变 关闭mysql,当mysql再次起来的时候,会发现auto_increment值从4,变成1
业务不要依赖auto_increment值,它并不是总是递增