ICML 2017 仍然在悉尼火熱進行中,Facebook 研究院今天也發文介紹了自己的 ICML 論文。Facebook有9篇論文被 ICML 2017接收,這些論文的主題包括語言模組化、優化和圖像的無監督學習;另外 Facebook 還會共同參與組織 Video Games and Machine Learning Workshop。
曾掀起研究熱潮的 Wasserstein GAN
在9篇接收論文中,Facebook 自己最喜歡的是「Wasserstein Generative Adversarial Networks」(WGAN)這一篇,它也确實對整個機器學習界有巨大的影響力,今年也掀起過一陣 WGAN 的熱潮。
Ian Goodfellow 提出的原始的 GAN 大家都非常熟悉了,利用對抗性的訓練過程給生成式問題提供了很棒的解決方案,應用空間也非常廣泛,從此之後基于 GAN 架構做應用的論文層出不窮,但是 GAN 的訓練困難、訓練程序難以判斷、生成樣本缺乏多樣性(mode collapse)等問題一直沒有得到完善解決。 這篇 Facebook 和紐約大學庫朗數學科學研究所的研究員們合作完成的 WGAN 論文就是衆多嘗試改進 GAN、解決它的問題的論文中具有裡程碑意義的一篇。
WGAN 的作者們其實花了整整兩篇論文才完全表達了自己的想法。在第一篇「Towards Principled Methods for Training Generative Adversarial Networks」裡面推了一堆公式定理,從理論上分析了原始GAN的問題所在,進而針對性地給出了改進要點;在這第二篇「Wasserstein Generative Adversarial Networks」裡面,又再從這個改進點出發推了一堆公式定理,最終給出了改進的算法實作流程。
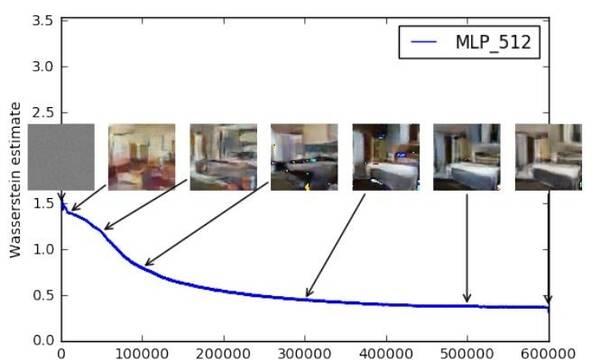
WGAN 成功地做到了以下爆炸性的幾點:
徹底解決GAN訓練不穩定的問題,不再需要小心平衡生成器和判别器的訓練程度
基本解決了collapse mode的問題,確定了生成樣本的多樣性
訓練過程中終于有一個像交叉熵、準确率這樣的數值來訓示訓練的程序,這個數值越小代表GAN訓練得越好,代表生成器産生的圖像品質越高(如題圖所示)
以上一切好處不需要精心設計的網絡架構,最簡單的多層全連接配接網絡就可以做到
而改進後相比原始GAN的算法實作流程卻隻改了四點:
判别器最後一層去掉sigmoid
生成器和判别器的loss不取log
每次更新判别器的參數之後把它們的絕對值截斷到不超過一個固定常數c
不要用基于動量的優化算法(包括momentum和Adam),推薦RMSProp,SGD也行
是以數學學得好真的很重要,正是靠着對 GAN 的原理和問題的深入分析,才能夠找到針對性的方法改進問題,而且最終的呈現也這麼簡單。( WGAN詳解參見雷鋒網 AI 科技評論文章 令人拍案叫絕的Wasserstein GAN)
WGAN 論文今年1月公布後馬上引起了轟動,Ian Goodfellow 也在 reddit 上和網友們展開了熱烈的讨論。不過在讨論中,還是有人反映 WGAN 存在訓練困難、收斂速度慢等問題,WGAN 論文一作 Martin Arjovsky 也在 reddit 上表示自己意識到了,然後對 WGAN 做了進一步的改進。
改進後的論文為「Improved Training of Wasserstein GANs」。原來的 WGAN 中采用的 Lipschitz 限制的實作方法需要把判别器參數的絕對值截斷到不超過固定常數 c,問題也就來自這裡,作者的本意是避免判别器給出的分值差別太大,用較小的梯度配合生成器的學習;但是判别器還是會追求盡量大的分值差別,最後就導緻參數的取值總是最大值或者最小值,浪費了網絡優秀的拟合能力。改進後的 WGAN-GP 中更換為了梯度懲罰 gradient penalty,判别器參數就能夠學到合理的參數取值,進而顯著提高訓練速度,解決了原始WGAN收斂緩慢的問題,在實驗中還第一次成功做到了“純粹的”的文本GAN訓練。(WGAN-GP詳解參見雷鋒網 AI 科技評論文章 掀起熱潮的Wasserstein GAN,在近段時間又有哪些研究進展?)
![【GANs學習筆記】(八)WGAN[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)