一、誕生原因
緩存是一種提供資料讀取性能的技術,在硬體設計、軟體開發中有廣泛的應用,比如常見的 CPU 緩存,DB 緩存和浏覽器緩存等。但是緩存的大小是有限的,需要一定的機制判斷哪些資料需要淘汰,即:移出緩存,進而保證緩存中的資料始終是常用的。常用的機制裡面包括 LRU 緩存淘汰算法。
二、設計原則
全稱:Least Recently Used
如果一個資料在最近一段時間沒有被通路到,那麼在将來它被通路的可能性也很小。是以淘汰的資料應該是許久沒有通路到的資料。
三、所用的資料結構
- 雙向連結清單:用于串聯緩存資料。
- 紅黑樹(散清單):用于索引緩存資料。
四、執行過程
假設 data 中包含 key 和 value。
節點為 node(指針)。
1、增加緩存資料時,
若緩存已滿,double list 尾部資料 delete 掉,将新 data 壓入雙向連結清單頭部;
将新 data 壓入到紅黑樹中,key 值為 data 中的 key,value 為 node。
2、擷取緩存資料時,
先從紅黑樹中根據 key 找到 node,将 node 放到雙向連結清單的頭部,最後傳回 node 中 data。
五、代碼栗子
github
六、優化
節選:https://www.cnblogs.com/goodAndyxublog/p/11757134.html
以下方案來源與 MySQL InnoDB LRU 改進算法
将連結清單拆分成兩部分,分為熱資料區,與冷資料區,如圖所示。
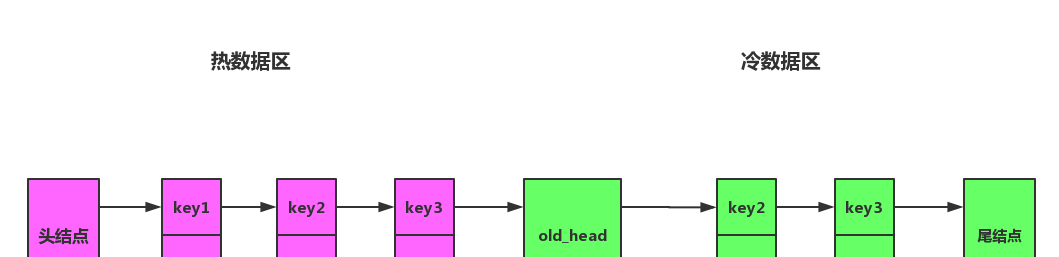
改進之後算法流程将會變成下面一樣:
- 通路資料如果位于熱資料區,與之前 LRU 算法一樣,移動到熱資料區的頭結點。
- 插入資料時,若緩存已滿,淘汰尾結點的資料。然後将資料插入冷資料區的頭結點。
- 處于冷資料區的資料每次被通路需要做如下判斷:
- 若該資料已在緩存中超過指定時間,比如說 1 s,則移動到熱資料區的頭結點。
- 若該資料存在在時間小于指定的時間,則位置保持不變。
對于偶發的批量查詢,資料僅僅隻會落入冷資料區,然後很快就會被淘汰出去。熱門資料區的資料将不會受到影響,這樣就解決了 LRU 算法緩存命中率下降的問題。
參考:極客時間《資料結構與算法之美》王争
這門課真心推薦,内容很經典、栗子很形象,裡面還包含了很多面試題目。真是居家旅行必備良藥。
(SAW:Game Over!)
![goalng nil interface淺析持續學習[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)