- EMNLP2019: A Boundary-aware Neural Model for Nested Named Entity Recognition
- 論文連結: https://www.aclweb.org/anthology/D19-1034.pdf
- 論文代碼: https://github.com/thecharm/boundary-aware-nested-ner
簡介
Motivation
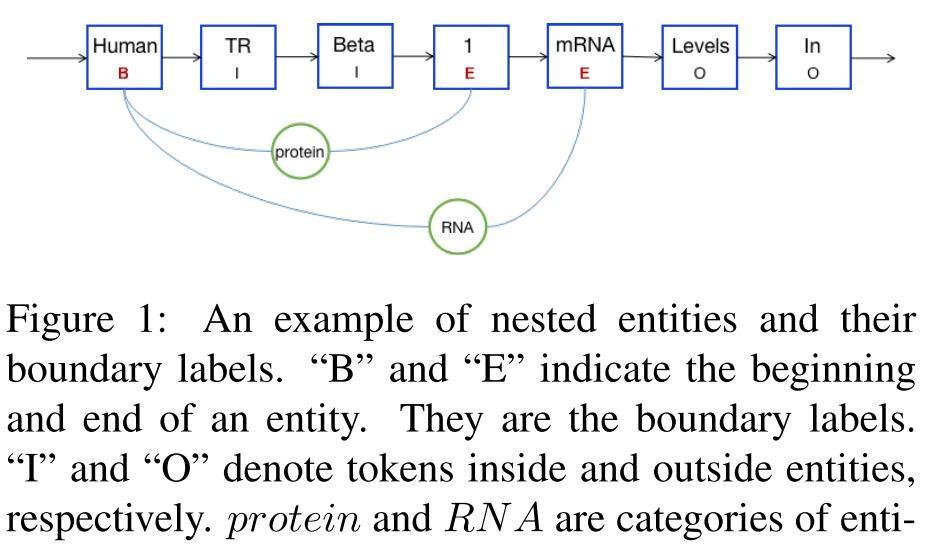
在 NER 任務中,有一類特殊的 nested entity, 即兩個不同的實體互相嵌套,如Figure1中的 protein 實體 和 RNA 實體。在這種情況下,同一個 token (例如圖中的 “1” ), 就會具備不同的實體标簽。
傳統方法會通過人工提供特征來解決這裡問題,但卻受限于特征工程的繁重工作。在今年的方法中,有兩類方法解決nested NER問題:
- Layered Sequence Labeling model: 通過層級的序列标注,先識别内層的實體,然後基于此通過下一層的序列标注來識别外層的實體;然而這一方法的受限于錯誤傳遞;
- Region Classification Model: 發現序列中所有可能的實體位置區間(span), 将他們輸入分類層來發現具體的實體;然而這一方法的缺點是由于缺乏精确的邊界資訊,會抽取出很多并非 target entity 的 entity mention.
基于以上兩種方法的優缺點,本文考慮将他們結合起來: 用序列标注模型來發現實體的位置,用 region classification model 對序列标注發現的 entity span candidate 進行實體類型的分類; 同時,由于 實體标簽預測 和 邊界發現 是在同一區間範圍内的,是以引入多任務學習對它們進行優化。
Contributions
- 本文設計了邊界感覺的神經網絡模型來預測實體的類别資訊,它可以首先定位出實體的位置(span), 然後在對應的位置區間内進行實體類型的預測;
- 引入多任務學習來捕實體邊界與事件标簽之間的依賴關系;
- 在公開的 nested NER 資料集上,本文模型取得了超越 SOTA 的效果,并在inference取得了更快的速度。
相關工作
在相關工作中,作者指出了如下幾點:
- 在現有的 NER 相關工作中,對 nested NER 進行研究的工作相對較少;
- 現有的 nested NER 工作提出的方案,可能是考慮了太多備援的 span/region 資訊, 或是 将邊界預測和标簽分類兩個字任務太過于隔離,沒有很好地利用現有的上下文資訊。
- 本文提出的模型,則是用 更少、更精确的實體邊界資訊,來提高實體分類的性能。
模型

本文模型具體包括以下部分:
Token Representaiton
對于包含 n n n 個tokens的句子 ( t 1 , t 2 , . . . , t n ) (t_1, t_2, ..., t_n) (t1,t2,...,tn), 通過如下三個步驟得到初始的表示:
-
通過 lookup table 擷取 t i t_i ti 的 word embedding:
x i w = e w ( t i ) x_i^w = e^w(t_i) xiw=ew(ti)
- 若一個token t i t_i ti 包含若幹個 characters x i c x_i^c xic, 則先通過 e c ( x i c ) e^{c}(x_i^c) ec(xic) 得到其對應的詞向量,然後通過 BiLSTM 得到每個字元的表示:
x i c = [ h i c ← ; h i c → ] x_i^c = [ \overleftarrow{h_i^c}; \overrightarrow{h_i^c}] xic=[hic
;hic
]
- 最後将 token 和 對應字元的表示進行拼接:
x i t = [ x i w , x i c ] x_i^t = [x_i^w, x_i^c] xit=[xiw,xic]
Shared Feature Extractor
在得到 x i t x_i^t xit 的表示後,通過 BiLSTM 再次進行特征抽取:
Entity Boundary Detection
在邊界檢測階段,對于句子 ( t 1 , t 2 , . . . , t n ) (t_1, t_2, ..., t_n) (t1,t2,...,tn), 我們将其包含的 entity 表示為 R ( i , j ) R(i,j) R(i,j), 表示 ( t i , t i + 1 , . . . , t j ) (t_i, t_{i+1}, ..., t_j) (ti,ti+1,...,tj) 構成一個實體。具體地,将 t i t_i ti 和 t j t_j tj 标注為 B 和 E, 區間内的token标注為 I, 非實體的token标注為 O。
對于每個token, 通過如下計算預測其對應的邊界标簽:
并通過下式定義 boundary detection 的 loss:
L b c l s = − ∑ ( d i t ^ log ( d i t ) ) L_{bcls} = -\sum{(\hat{d_i^t} \log(d_i^t))} Lbcls=−∑(dit^log(dit))
Entity Categorical Label Prediction
基于 boundary detection 得到 R(i,j) 的基礎上,首先計算得到 R(i,j) 部分對應的表示:
R i , j = [ 1 j − i + 1 ∑ k = i j h k t ] R_{i,j} = [ \frac{1}{j-i+1} \sum_{k=i}^j{h_k^t}] Ri,j=[j−i+11k=i∑jhkt]
然後對 R(i,j) 進行實體類别的分類,并定義loss:
Multitask Training
多任務的 loss 如下定義, 其中 α \alpha α 是控制各子任務重要性的超參
a l p h a ∑ L b c l s + ( 1 − α ) ∑ L e c l s alpha \sum{ L_{bcls} }+ (1-\alpha) \sum{L_{ecls}} alpha∑Lbcls+(1−α)∑Lecls
實驗
實驗部分主要介紹了所用的資料集、Baseline、參數設定 和 評價函數。
結果與讨論
- 分析總體實驗結果。結果顯示,本文模型的實驗結果超越了現有的SOTA模型,且作者認為由于本文方法能更準确地發現entity邊界以及 end2end 多任務抽取模式帶來的提升,并在下文進行了分析。
- 分析Boundary Detection上的實驗結果。從文中表5,6 看出本文在Boundary Detection 上就取得了比其他模型更好的效果,作者将這歸因于multiLoss 同時考慮了 實體邊界與實體類型間依賴; 同時,正是因為Boundary Detection 上更好的實驗效果,整個 nested NER 任務才取得了更好的效果。
- 分析本文模型與現有模型在 Inference Time 上的差別。本文模型取得了更高的效率,作者将這歸因于 本文發現的 entity boundary 是更精确的,較之前人工作,non-entity boundary 更少。
- 分析多任務學習的影響。作者将本文的 Boundary Detection 與 EntityLabel Prediction 用 Pipiline 的方式進行了運作,發現仍舊是ene2end取得了較好的結果。作者将這歸因于,** Multi-task Learning 能夠捕捉到 實體邊界和實體類型标簽間隐含的依賴資訊**。
- 分析本文模型在** Flat NER** 任務上的結果。作者用本文模型在 JNLPBA DataSet 進行了 Falt NER 的實驗,仍舊取得了較好的效果。
- 執行個體分析。作者通過一則執行個體對不同方法的特點進行分析,例句中 human TATA binding factor 是内嵌于 transcriptionally active human TATA binding factor的實體,Layered model 都隻檢出了 outer entity, 這說明相比之下本文模型能更加準确地發現 entity 的區間範圍; 而本文方法的 PipiLine 模式隻檢測出了 inner entity, 這說明 Multitask 的方法能夠在邊界檢測子產品和實體類型預測子產品間進行資訊共享,這有助于結果的提升。
了解更多深度學習相關知識與資訊,請關注公衆号深度學習的知識小屋