目錄
-
- 研究成果意義
-
- 成果
- 曆史意義
- 網絡結構
- 網絡結構和參數計算
-
- ReLU(Rectified Linear Units)
- LRN(Local Response Normalization)
- Overlapping Pooling
- 網絡特色和訓練技巧
-
- Data Augmentation
- Dropout
- 結果分析
-
- 卷積核可視化
- 特征的相似性
- Top-5的語義分析
- 總結
研究成果意義
成果
ILSVRC-2012以超出第二名10.9百分比奪冠。
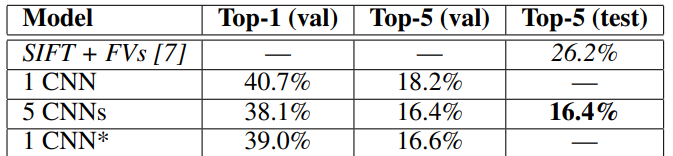

曆史意義
- 拉開了卷積神經網絡統治計算機視覺的序幕
- 加速計算機視覺應用落地.
AlexNet論文學習筆記(超詳解)
網絡結構
采用了5個卷積層和3個全連接配接層,輸出為1000個經過softmax的值。
網絡結構和參數計算
ReLU(Rectified Linear Units)
飽和激活函數和非飽和激活函數:
當我們的n趨近于正無窮,激活函數的導數趨近于0,那麼我們稱之為右飽和。
當我們的n趨近于負無窮,激活函數的導數趨近于0,那麼我們稱之為左飽和。
當一個函數既滿足左飽和又滿足右飽和的時候我們就稱之為飽和,典型的函數有Sigmoid,Tanh函數。
因為使用例如 f ( x ) = t a n h ( x ) f(x)=tanh(x) f(x)=tanh(x)和 f ( x ) = ( 1 + e − x ) − 1 f(x)=(1+e^{-x})^{-1} f(x)=(1+e−x)−1這樣的飽和激活函數速度是非常慢的。是以使用了非飽和激活函數 f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)。
優點:
- 使網絡訓練更快
- 防止梯度消失(彌散)(因為大于零時梯度為1)
- 使網絡具有稀疏性(因為小于零時梯度為零)
LRN(Local Response Normalization)
局部響應标準化:有助于AlexNet泛化能力的提升,受真實神經元側抑制(lateral inhibition)啟發
側抑制:細胞分化變為不同時,它會對周圍細胞産生抑制信号,阻止它們向相同方向分化,最終表現為細胞命運的不同。
使用了這個技術後top-1、top-5精度提高了1.4%、1.2%
Overlapping Pooling
通常我們使用的池化都是步長等于滑動視窗大小,但是這裡使用了帶重疊的池化,這裡的步長為2滑動視窗大小為3。
使用了這個技術後top-1、top-5精度提高了0.4%、0.3%。
網絡特色和訓練技巧
Data Augmentation
第一種方式
在訓練的時候,從256x256的圖像中随機抽出224x224大小的圖檔,并進行水準翻轉。這樣每個圖檔就可以得到32x32x2=2048張圖檔。
在測試的時候,從256x256的圖像中四個角和中間抽出5張224x224大小的圖檔,并進行水準翻轉。這樣每個圖檔可以得到10張測試圖檔。把這10個圖檔都輸入進去,對結果求平均值。
第二種方式
通過PCA方法修改RGB通道的像素值,實作顔色擾動,效果有限,僅在top-1提高一個點(top-1 acc約為62.5%)
Dropout
通常結合多個模型進行預測可以提高效果。但是使用多個模型會非常耗費時間。我們使用Dropout就可以實作這個效果,我們給神經元設定失活的機率(通常為0.5,而且在測試的時候不進行失活,是以測試的時候需要對結果乘以失活機率)。因為每次都會有神經元随機失活,是以相當于每次訓練的是不同的模型,而之後測試時使用完整的神經網絡,就可以達到類似于多個模型一起預測的效果。
結果分析
卷積核可視化
- 卷積核呈現出不同的頻率、顔色和方向
- 兩個GPU還呈現分工學習
為什麼使用第一層卷積進行可視化? 因為第一層的卷積核比較大,看着比較清楚;越往後學到的特征是越進階越抽象的,第一個卷積層更符合人眼所見的。
特征的相似性
相似圖檔的第二個全連接配接層輸出的特征向量的歐氏距離相近。
最後一個全連接配接層的輸入一共有4096個,這些資料相等于是提取出來的進階特征。如果兩個圖檔的這些進階特征歐氏距離相近則說明差距更小。在實際中發現歐氏距離相近的圖檔往往都是同一個物體。
啟發:可用AlexNet提取進階特征進行圖像檢索、圖像聚類、圖像編碼。
Top-5的語義分析
可以看到預測出來的top-5都是接近的事物。
總結
關鍵點
- 大量帶标簽資料–ImageNet
- 高性能計算資源–GPU
- 合理算法模型–深度卷積神經網絡
創新點
- 采用ReLu加快大型神經網絡訓練
- 采用LRN提升大型網絡泛化能力
- 采用Overlapping Pooling提升名額
- 采用随機裁剪翻轉及色彩擾動增加資料多樣性
- 采用Dropout減輕過拟合
啟發點
- 深度與寬帶可決定網絡能力
- 更強大的GPU及更多資料可進一步提高模型性能
- 圖檔縮放細節,當不是我們需要的大小(256x256)時,對短邊先縮放,為了避免短邊的像素缺失。(比如一個512x1024的圖檔,我們得到256x512的圖檔,然後從中間裁剪)
- ReLU不需要對輸入進行标準化來防止飽和現象,即說明sigmoid/tanh激活函數有必要對輸入進行标準化。
- 卷積核學習到頻率、方向和顔色特征
- 相似圖檔具有“相近”的進階特征
- 圖像檢索可以基于進階特征,效果應該優于原始圖像
- 網絡結構具有相關性,不可輕易移除某一層
- 采用視訊資料可能有新突破,因為視訊資訊可以有時間次元的資訊