在 pandas 中,我們可以使用 concat() 和 merge() 對 DataFrame 進行拼接。
1. concat()
concat() 函數的作用是沿着某個坐标軸對 DataFrame 進行拼接。在 concat() 函數中,有幾個常用的參數。
- axis:指出在哪個坐标軸的方向上進行拼接。可取的值為
0/index,1/columns
- join:指出拼接的方式,可取的值為
inner,outer
outer
- ignore_index:指出是否使用拼接軸上的索引,可取的值為
False、True
1.1 DataFrame 的列索引相同
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([144, 145, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index = ['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2])) 在上面的例子中,df1 和 df2 有完全相同的列,是以拼接之後的 DataFrame 的列名也是相同的,拼接的方向為垂直方向。拼接之後使用的索引是原來 DataFrame 的索引。如果不想使用原來的索引可以設定參數 ignore_index。例如:
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index = ['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"High": pd.Series([144, 145, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index = ['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2], ignore_index=True)) 上面代碼中,當設定參數 ignore_index=True 時,拼接後的 DataFrame 中便不再使用原來的索引,而是自動生成的索引。
1.2 DataFrame 的列索引有重疊
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Volume": pd.Series([105575500, 99788400, 76299700], index=['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2])) 在上面的代碼中,df2 比 df1 多了一列 Volume,少了一列 High。在最終拼接的 DataFrame 中,列為 df1 和 df2 列的并集,不存在的資料用 NaN 填充。因為拼接的方式預設為 outer,是以最終結果的列為 df1 和 df2 列的并集。我們還可以将拼接方式改為 inner,這時候最終結果的列為 df1 和 df2 列的交集。例如:
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Volume": pd.Series([105575500, 99788400, 76299700], index=['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2], join='inner')) 在上面的代碼中,由于将拼接方式設定成 inner,是以最終結果的列為 df1 和 df2 列的交集。上面的拼接方向都是垂直方向,當然我們還可以通過參數的設定進行水準方向的拼接。例如:
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index=['2021-07-08', '2021-07-09', '2021-07-12']),
"Volume": pd.Series([105575500, 99788400, 76299700], index=['2021-07-08', '2021-07-09', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2], axis=1)) 上面的代碼中,通過設定參數 axis=1 使得進行水準方向的拼接,當進行水準方向的拼接時,是按照行的索引進行拼接的,由于拼接的方式預設為 outer,是以對于進行拼接的 df1 和 df2,不存在的行對應的資料用 NaN 進行填充。我們也可以把拼接的方式設定成 inner,例如:
import pandas as pd
d1 = {
"Open": pd.Series([136, 137, 140, 143], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"High": pd.Series([137, 140, 143, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Low": pd.Series([135, 137, 140, 142], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07']),
"Close": pd.Series([137, 139, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-06', '2021-07-07'])
}
d2 = {
"Open": pd.Series([141, 142, 146], index=['2021-07-01', '2021-07-02', '2021-07-12']),
"Low": pd.Series([140, 142, 144], index=['2021-07-01', '2021-07-02', '2021-07-12']),
"Close": pd.Series([143, 145, 144], index=['2021-07-01', '2021-07-02', '2021-07-12']),
"Volume": pd.Series([105575500, 99788400, 76299700], index=['2021-07-01', '2021-07-02', '2021-07-12'])
}
df1 = pd.DataFrame(d1)
df2 = pd.DataFrame(d2)
print(df1)
print(df2)
print(pd.concat([df1, df2], axis=1, join='inner')) 在上面的例子中,df1 和 df2 索引相同的行為 2021-07-01 和 2021-07-02,是以最終的拼接結果中隻包含索引 2021-07-01 和 2021-07-02。
2. merge()
merge() 函數的作用和 SQL 裡的 join 操作的作用非常類似,都是根據一些條件将行拼接起來。
2.1 資料庫風格的拼接
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2)) 上面的例子是多對一的連接配接,df1 有多個被标記為 Alice 和 Bob 的行,在 df2 中,name 列的每個值僅對應一行。在進行拼接的過程中,df1 和 df2 中 name 列的值相同的行被連接配接在一起,不相同的行不在最終的連接配接結果中。因為預設情況下,merge 做的是内連接配接,結果中的鍵是交集。注意,在上面的例子中,我們并沒有指明要用哪個列進行連接配接。如果沒有指定,merge 會将重疊列的列名當做鍵。不過,最好明确指定,例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name')) 如果兩個 DataFrame 對象的列名不同,也可以分别進行指定。例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'lname': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'rname': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on='lname', right_on='rname')) 上面的連接配接方式預設為 inner,此外其他的連接配接方式還有 left、right 以及 outer。它們的連接配接規則是:
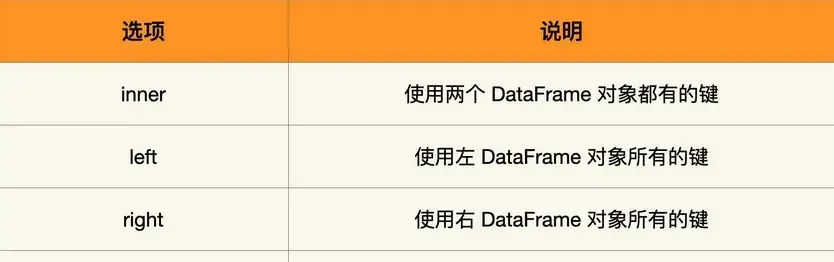
我們以剛才的例子為例,來看看各自的輸出結果。
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='left')) 左連接配接以左邊的 DataFrame 對象的鍵為主,右邊 DataFrame 對象不存在的鍵對應的資料用 NaN 填充。
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='right')) 右連接配接以右邊的 DataFrame 對象的鍵為主,左邊 DataFrame 對象不存在的鍵對應的資料用 NaN 填充。
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Deniel'],
'score2': [96, 82, 97]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='outer')) 外連接配接取兩個 DataFrame 對象的鍵的并集,相對并集來說不存在的鍵對應的值以 NaN 填充。上面講的是多對一的例子,下面來看下多對多的例子:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'score2': [95, 80, 81, 98, 85]
})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name')) 多對多連接配接産生的是行的笛卡爾積。由于左邊的 DataFrame 對象中有 3 個 Bob 行,右邊的有 2 個 Bob 行,是以最終結果中就有 6 個 Bob 行。多對多連接配接同樣可以設定連接配接的方式。例如:
left:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='left')) right:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='right')) outer:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', how='outer')) 如果要根據多個鍵進行合并,傳入一個由列名組成的清單即可,例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'gender': ['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'gender': ['Female', 'Male', 'Female', 'Male', 'Male'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on=['name', 'gender'])) 當合并後的 DataFrame 對象中有重複列名時,會預設為左邊 DataFrame 對象中的列名加上 _x 字尾,為右邊 DataFrame 對象中的列名加上 _y 字尾。附加的字尾我們也可以通過參數 suffixes 來設定。例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'gender': ['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Deniel'],
'gender': ['Female', 'Male', 'Female', 'Male', 'Male'],
'score2': [95, 80, 81, 98, 85]})
print(df1)
print(df2)
print(pd.merge(df1, df2, on='name', suffixes=('_left', '_right'))) 2.2基于索引的拼接
有時候,DataFrame 中的連接配接鍵位于其索引中。在這種情況下,可以傳入
left_index=True
或
right_index=True
(或兩個都傳)以說明索引應該被用作連接配接鍵,例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'score2': [96, 82, 97]}, index=['Alice', 'Bob', 'Deniel'])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on='name', right_index=True)) 上面的例子中,df1 中用于連接配接的鍵為 name,是以指定參數
left_on=name
,df2 中用于連接配接的鍵位于索引中,是以指定參數
right_index=True
。上面的連接配接預設采用 inner 的方式,當然我們也可以設定其他的連接配接方式。例如:
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'score2': [96, 82, 97]}, index=['Alice', 'Bob', 'Deniel'])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on='name', right_index=True, how='outer')) import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'gender': ['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'score2': [96, 82, 97, 92]},
index=[['Alice', 'Alice', 'Bob', 'Bob'],
['Female', 'Female', 'Male', 'Male']])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on=['name', 'gender'], right_index=True)) import numpy as np
import pandas as pd
df1 = pd.DataFrame({'name': ['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
'gender': ['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male'],
'score1': [97, 92, 88, 98, 86, 99, 94]})
df2 = pd.DataFrame({'score2': [96, 82, 97, 92]},
index=[['Alice', 'Alice', 'Bob', 'Bob'],
['Female', 'Female', 'Male', 'Male']])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_on=['name', 'gender'], right_index=True, how='outer')) import numpy as np
import pandas as pd
df1 = pd.DataFrame({'score1': [97, 92, 88, 98, 86, 99, 94]},
index = [['Bob', 'Bob', 'Alice', 'Charlie', 'Alice', 'Alice', 'Bob'],
['Male', 'Male', 'Female', 'Male', 'Female', 'Female', 'Male']])
df2 = pd.DataFrame({'score2': [96, 82, 97, 92]},
index=[['Alice', 'Alice', 'Bob', 'Bob'],
['Female', 'Female', 'Male', 'Male']])
print(df1)
print(df2)
print(pd.merge(df1, df2, left_index=True, right_index=True)) ![Kafka:Topic概念與API介紹[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)