1、數字
123 1.23e2
-0.125 1.25E-1 2、邏輯
布爾型,常量值隻有
TRUE
和
FALSE
。
**注意:**R 語言區分大小寫,true 或 True 不能代表 TRUE。
3、字元串
在 R 語言中,字元串既可以用單引号包含,也可以用雙引号包含
| 字元串函數 | 說明 |
| toupper(“xxx”) | 轉換為大寫 |
| tolower(“xxx”) | 轉換為小寫 |
| ncahr(“xxx”, type=“bytes”) | 統計位元組長度 |
| ncahr(“xxx”, type=“char”) | 統計字元長度 |
| substr(“123456”, 1, 5) | 截取字元串,從1到5 |
| substring(“1234567890”, 5) | 截取字元串,從5到結束 |
| as.numeric(“12”) | 将字元串轉換為數字 |
| as.character(12.34) | 将數字轉換為字元串 |
| strsplit(“2019;10;1;”, “;”) | 分隔符拆分字元串 |
| gsub(“/”, “-”, “2019/10/1”) | 替換字元串2019-10-1 |
在 Windows 計算機上實作,使用的是 GBK 編碼标準,是以一個中文字元是兩個位元組,如果在 UTF-8 編碼的計算機上運作,單個中文字元的位元組長度應該是 3。
4、向量
向量從資料結構上看就是一個線性表,可以看成一個數組
向量的生成
1、建立向量函數:
c()
2、等差數列:
seq()
seq(1, 9, 2) # 1 3 5 7 9
seq(0, 1, length.out=3) # 0.0 0.5 1.0 3、重複序列:
rep()
rep(0, 5) # 0 0 0 0 0 向量中常會用到 NA 和 NULL ,這裡介紹一下這兩個詞語與差別:
- NA 代表的是"缺失",NULL 代表的是"不存在"。
- NA 缺失就像占位符,代表這裡沒有一個值,但位置存在。
- NULL 代表的就是資料不存在。
向量通路
a = c(10,20,30,40,50,60)
print(a[2])
#取出第1項到第4項,10 20 30 40
a[1:4]
#取出第1,3,5項,10 30 50
a[c(1,3,5)]
#去掉第1和第5項,20 30 40 60
a[c(-1,-5)] 可以通過下标取向量中的元素,小标從1開始
向量支援标量計算
a = c(1,2,3)
a = a - 0.5 # 0.5 1.5 2.5
b = c(1,2)
b = b ^ 2 # 1 4 向量函數
| 函數 | 說明 |
| sort(a) | 從小到大排序 |
| rev(a) | 從大到小排序 |
| order(a) | 向量排序之後的下标向量,排序後的這項在排序前的下标 |
| sum | 求和 |
| mean | 求平均值 |
| var | 方差 |
| sd | 标準差 |
| min | 最小值 |
| max | 最大值 |
| range | 取值範圍(二維向量,最大值和最小值) |
| which() | a = c(1,2,3,4,5) b =a[which(a>=3 & a<=4)] # 2 3 4 |
| all() | 向量全為TRUE,傳回TRUE |
| any() | 向量存在一個TRUE,傳回TRUE |
5、矩陣
矩陣類似于二維數組
矩陣生成:
vector = c(1,2,3,4,5,6) # 建立向量
m = matrix(vector, 2, 3) #建立矩陣,2行3列 矩陣通路:
m[1,1] # 第1行、第1列 設定矩陣行列名稱:
colnames(m) = c("x", "y", "z")
rownames(m) = c("a", "b")
x y z
a 1 2 3
b 4 5 6 矩陣乘法運算:
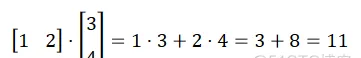
> m1 = matrix(c(1, 2), 1, 2)
> m2 = matrix(c(3, 4), 2, 1)
> m1 %*% m2
[,1]
[1,] 11 逆矩陣:

> A = matrix(c(1, 3, 2, 4), 2, 2)
> solve(A)
[,1] [,2]
[1,] -2.0 1.0
[2,] 1.5 -0.5 solve() 函數用于求解線性代數方程,基本用法是 solve(A,b),其中,A 為方程組的系數矩陣,b 方程的向量或矩陣。
> (A = matrix(c(1, 3, 2, 4), 2, 2))
[,1] [,2]
[1,] 1 2
[2,] 3 4
> apply(A, 1, sum) # 第二個參數為 1 按行操作,用 sum() 函數
[1] 3 7
> apply(A, 2, sum) # 第二個參數為 2 按列操作
[1] 4 6