轉自:https://www.qcloud.com/community/article/835460
作者 |塗小剛
編輯 | 顧鄉
通過文章“【Spark教程】核心概念RDD”我們知道,Spark的核心是根據RDD來實作的,Spark任務排程則為Spark核心實作的重要一環。Spark的任務排程就是如何組織任務去處理RDD中每個分區的資料,根據RDD的依賴關系建構DAG,基于DAG劃分Stage,将每個Stage中的任務發到指定節點運作。基于Spark的任務排程原理,我們可以合理規劃資源利用,做到盡可能用最少的資源高效地完成任務計算。
分布式運作架構
Spark可以部署在多種資源管理平台,例如Yarn、Mesos等,Spark本身也實作了一個簡易的資源管理機制,稱之為Standalone模式。由于工作中接觸較多的是Saprk on Yarn,不做特别說明,以下所述均表示Spark on Yarn。Spark部署在Yarn上有兩種運作模式,分别為client和cluster模式,它們的差別僅僅在于Spark Driver是運作在Client端還是ApplicationMater端。如下圖所示為Spark部署在Yarn上,以cluster模式運作的分布式計算架構。
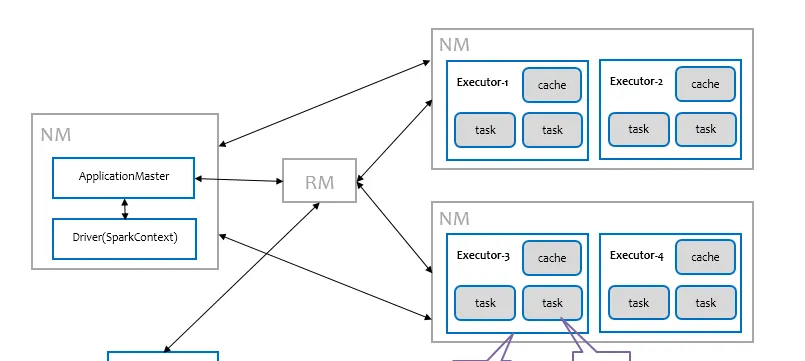
其中藍色部分是Spark裡的概念,包括Client、ApplicationMaster、Driver和Executor,其中Client和ApplicationMaster主要是負責與Yarn進行互動;Driver作為Spark應用程式的總控,負責分發任務以及監控任務運作狀态;Executor負責執行任務,并上報狀态資訊給Driver,從邏輯上來看Executor是程序,運作在其中的任務是線程,是以說Spark的任務是線程級别的。通過下面的時序圖可以更清晰地了解一個Spark應用程式從送出到運作的完整流程。

送出一個Spark應用程式,首先通過Client向ResourceManager請求啟動一個Application,同時檢查是否有足夠的資源滿足Application的需求,如果資源條件滿足,則将ApplicationMaster的啟動上下文,交給ResourceManager,并循環監控Application狀态。
當送出的資源隊列中有資源時,ResourceManager會在某個NodeManager上啟動ApplicationMaster程序,ApplicationMaster會單獨啟動Driver背景線程,當Driver啟動後,ApplicationMaster會通過本地的RPC連接配接Driver,并開始向ResourceManager申請Container資源運作Executor程序 (一個Executor對應與一個Container),當ResourceManager傳回Container資源,則在對應的Container上啟動Executor。
Driver線程主要是初始化SparkContext對象,準備運作所需的上下文,然後一方面保持與ApplicationMaster的RPC連接配接,通過ApplicationMaster申請資源,另一方面根據使用者業務邏輯開始排程任務,将任務下發到已有的空閑Executor上。
當ResourceManager向ApplicationMaster傳回Container資源時,ApplicationMaster就嘗試在對應的Container上啟動Executor程序,Executor程序起來後,會向Driver注冊,注冊成功後保持與Driver的心跳,同時等待Driver分發任務,當分發的任務執行完畢後,将任務狀态上報給Driver。
Driver把資源申請的邏輯給抽象出來,以适配不同的資源管理系統,是以才間接地通過ApplicationMaster去和Yarn打交道。
從上述時序圖可知,Client隻管送出Application并監控Application的狀态。對于Spark的任務排程主要是集中在兩個方面: 資源申請和任務分發,其主要是通過ApplicationMaster、Driver以及Executor之間來完成,下面詳細剖析Spark任務排程每個細節。
Spark任務排程總覽
當Driver起來後,Driver則會根據使用者程式邏輯準備任務,并根據Executor資源情況逐漸分發任務。在詳細闡述任務排程前,首先說明下Spark裡的幾個概念。一個Spark應用程式包括Job、Stage以及Task三個概念:
- Job是以Action方法為界,遇到一個Action方法則觸發一個Job;
- Stage是Job的子集,以RDD寬依賴(即Shuffle)為界,遇到Shuffle做一次劃分;
- Task是Stage的子集,以并行度(分區數)來衡量,分區數是多少,則有多少個task。
Spark的任務排程總體來說分兩路進行,一路是Stage級的排程,一路是Task級的排程,總體排程流程如下圖所示。
Spark RDD通過其Transactions操作,形成了RDD血緣關系圖,即DAG,最後通過Action的調用,觸發Job并排程執行。DAGScheduler負責Stage級的排程,主要是将DAG切分成若幹Stages,并将每個Stage打包成TaskSet交給TaskScheduler排程。TaskScheduler負責Task級的排程,将DAGScheduler給過來的TaskSet按照指定的排程政策分發到Executor上執行,排程過程中SchedulerBackend負責提供可用資源,其中SchedulerBackend有多種實作,分别對接不同的資源管理系統。有了上述感性的認識後,下面這張圖描述了Spark-On-Yarn模式下在任務排程期間,ApplicationMaster、Driver以及Executor内部子產品的互動過程。
Driver初始化SparkContext過程中,會分别初始化DAGScheduler TaskScheduler SchedulerBackend以及HeartbeatReceiver。SchedulerBackend會啟動一個RPC服務與外界打交道,SchedulerBackend通過ApplicationMaster申請資源,并不斷從TaskScheduler中拿到合适的Task分發到Executor執行。HeartbeatReceiver也會啟動RPC服務負責接收Executor的心跳資訊,監控Executor的存活狀況,并通知到TaskScheduler。下面着重剖析DAGScheduler負責的Stage排程以及TaskScheduler負責的Task排程。
Stage級的排程
Spark的任務排程是從DAG切割開始,主要是由DAGScheduler來完成。當遇到一個Action操作後就會觸發一個Job的計算,并交給DAGScheduler來送出,下圖是涉及到Job送出的相關方法調用流程圖。
Job由最終的RDD和Action方法封裝而成,SparkContext将Job交給DAGScheduler送出,它會根據RDD的血緣關系構成的DAG進行切分,将一個Job劃分為若幹Stages,具體劃分政策是,由最終的RDD不斷通過依賴回溯判斷父依賴是否是款依賴,即以Shuffle為界,劃分Stage,窄依賴的RDD之間被劃分到同一個Stage中,可以進行pipeline式的計算,如上圖紫色流程部分。劃分的Stages分兩類,一類叫做ResultStage,為DAG最下遊的Stage,由Action方法決定,另一類叫做ShuffleMapStage,為下遊Stage準備資料,下面看一個簡單的例子WordCount。
Job由
saveAsTextFile
觸發,該Job由RDD-3和
saveAsTextFile
方法組成,根據RDD之間的依賴關系從RDD-3開始回溯搜尋,直到沒有依賴的RDD-0,在回溯搜尋過程中,RDD-3依賴RDD-2,并且是寬依賴,是以在RDD-2和RDD-3之間劃分Stage,RDD-3被劃到最後一個Stage,即ResultStage中,RDD-2依賴RDD-1,RDD-1依賴RDD-0,這些依賴都是窄依賴,是以将RDD-0、RDD-1和RDD-2劃分到同一個Stage,即ShuffleMapStage中,實際執行的時候,資料記錄會一氣呵成地執行RDD-0到RDD-2的轉化。不難看出,其本質上是一個深度優先搜尋算法。
一個Stage是否被送出,需要判斷它的父Stage是否執行,隻有在父Stage執行完畢才能送出目前Stage,如果一個Stage沒有父Stage,那麼從該Stage開始送出。Stage送出時會将Task資訊(分區資訊以及方法等)序列化并被打包成TaskSet交給TaskScheduler,一個Partition對應一個Task,另一方面監控Stage的運作狀态,隻有Executor丢失或者Task由于Fetch失敗才需要重新送出失敗的Stage以排程運作失敗的任務,其他類型的Task失敗會在TaskScheduler的排程過程中重試。
相對來說DAGScheduler做的事情較為簡單,僅僅是在Stage層面上劃分DAG,送出Stage并監控相關狀态資訊。TaskScheduler則相對較為複雜,下面詳細闡述其細節。
Task級的排程
Spark Task的排程是由TaskScheduler來完成,由前文可知,DAGScheduler将Stage打包到TaskSet交給TaskScheduler,TaskScheduler會将其封裝為TaskSetManager加入到排程隊列中,TaskSetManager負責監控管理同一個Stage中的Tasks。前面也提到,TaskScheduler初始化後會啟動SchedulerBackend,它負責跟外界打交道,接收Executor的注冊資訊,并維護Executor的狀态,是以說SchedulerBackend是管“糧食”的,同時它在啟動後會定期地去“詢問”TaskScheduler有沒有任務要運作,也就是說,它會定期地“問”TaskScheduler“我有這麼餘量,你要不要啊”,TaskScheduler在SchedulerBackend“問”它的時候,會從排程隊列中按照指定的排程政策選擇TaskSetManager去排程運作,大緻方法調用流程如下圖所示。
排程政策
前面講到,TaskScheduler會先把DAGScheduler給過來的TaskSet封裝成TaskSetManager扔到任務隊列裡,然後再從任務隊列裡按照一定的規則把它們取出來在SchedulerBackend給過來的Executor上運作。這個排程過程實際上還是比較粗粒度的,是面向TaskSetManager的。
TaskScheduler是以樹的方式來管理任務隊列,樹中的節點類型為Schdulable,葉子節點為TaskSetManager,非葉子節點為Pool,下圖是它們之間的繼承關系。
TaskScheduler支援兩種排程政策,一種是FIFO,也是預設的排程政策,另一種是FAIR。在TaskScheduler初始化過程中會執行個體化
rootPool
,表示樹的根節點,是Pool類型。如果是采用FIFO排程政策,則直接簡單地将TaskSetManager按照先來先到的方式入隊,出隊時直接拿出最先進隊的TaskSetManager,其樹結構大緻如下圖所示,TaskSetManager儲存在一個FIFO隊列中。
在闡述FAIR排程政策前,先貼一段使用FAIR排程政策的應用程式代碼,後面針對該代碼邏輯來詳細闡述FAIR排程的實作細節。
object MultiJobTest {
// spark.scheduler.mode=FAIR
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().getOrCreate()
val rdd = spark.sparkContext.textFile(...)
.map(_.split("\\s+"))
.map(x => (x(0), x(1)))
val jobExecutor = Executors.newFixedThreadPool(2)
jobExecutor.execute(new Runnable {
override def run(): Unit = {
spark.sparkContext.setLocalProperty("spark.scheduler.pool", "count-pool")
val cnt = rdd.groupByKey().count()
println(s"Count: $cnt")
}
})
jobExecutor.execute(new Runnable {
override def run(): Unit = {
spark.sparkContext.setLocalProperty("spark.scheduler.pool", "take-pool")
val data = rdd.sortByKey().take(10)
println(s"Data Samples: ")
data.foreach { x => println(x.mkString(", ")) }
}
})
jobExecutor.shutdown()
while (!jobExecutor.isTerminated) {}
println("Done!")
}
} 上述應用程式中使用兩個線程分别調用了Action方法,即有兩個Job會并發送出,但是不管怎樣,這兩個Job被切分成若幹TaskSet後終究會被交到TaskScheduler這裡統一管理,其排程樹大緻如下圖所示。
在出隊時,則會對所有TaskSetManager排序,具體排序過程是從根節點
rootPool
開始,遞歸地去排序子節點,最後合并到一個
ArrayBuffer
裡,代碼邏輯如下。
def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {
var sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]
val sortedSchedulableQueue = schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
for (schedulable <- sortedSchedulableQueue) {
sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue
}
sortedTaskSetQueue
} 使用FAIR排程政策時,上面代碼中的
taskSetSchedulingAlgorithm
的類型為
FairSchedulingAlgorithm
,排序過程的比較是基于Fair-share來比較的,每個要排序的對象包含三個屬性:
runningTasks
值(正在運作的Task數)、
minShare
值、
weight
值,比較時會綜合考量
runningTasks
值,
minShare
以及
weight
值。如果A對象的
runningTasks
大于它的
minShare
,B對象的
runningTasks
小于它的
minShare
,那麼B排在A前面;如果A、B對象的r
unningTasks
都小于它們的
minShare
,那麼就比較
runningTasks
與
minShare
的比值,誰小誰排前面;如果A、B對象的
runningTasks
都大于它們的
minShare
,那麼就比較
runningTasks
與
weight
的比值,誰小誰排前面。整體上來說就是通過
minShare
和
weight
這兩個參數控制比較過程,可以做到不讓資源被某些長時間Task給一直占了。
本地化排程
從排程隊列中拿到TaskSetManager後,那麼接下來的工作就是TaskSetManager按照一定的規則一個個取出Task給TaskScheduler,TaskScheduler再交給SchedulerBackend去發到Executor上執行。前面也提到,TaskSetManager封裝了一個Stage的所有Task,并負責管理排程這些Task。
在TaskSetManager初始化過程中,會對Tasks按照Locality級别進行分類,Task的Locality有五種,優先級由高到低順序:PROCESS_LOCAL(指定的Executor),NODE_LOCAL(指定的主機節點),NO_PREF(無所謂),RACK_LOCAL(指定的機架),ANY(滿足不了Task的Locality就随便排程)。這五種Locality級别存在包含關系,RACK_LOCAL包含NODE_LOCAL,NODE_LOCAL包含PROCESS_LOCAL,然而ANY包含其他所有四種。初始化階段在對Task分類時,根據Task的
preferredLocations
判斷它屬于哪個Locality級别,屬于PROCESS_LOCAL的Task同時也會被加入到NODE_LOCAL、RACK_LOCAL類别中,比如,一個Task的
preferredLocations
指定了在Executor-2上執行,那麼它屬于Executor-2對應的PROCESS_LOCAL類别,同時也把他加入到Executor-2所在的主機對應的NODE_LOCAL類别,Executor-2所在的主機的機架對應的RACK_LOCAL類别中,以及ANY類别,這樣在排程執行時,滿足不了PROCESS_LOCAL,就逐漸退化到NODE_LOCAL,RACK_LOCAL,ANY。TaskSetManager在決定排程哪些Task時,是通過上面流程圖中的
resourceOffer
方法來實作,為了盡可能地将Task排程到它的
preferredLocations
上,它采用一種延遲排程算法。
resourceOffer
方法原型如下,參數包括要排程任務的Executor Id、主機位址以及最大可容忍的Locality級别。
def resourceOffer(
execId: String,
host: String,
maxLocality: TaskLocality.TaskLocality)
: Option[TaskDescription] 延遲排程算法的大緻流程如下圖所示。
首先看是否存在
execId
對應的PROCESS_LOCAL類别的任務,如果存在,取出來排程,否則根據目前時間,判斷是否超過了PROCESS_LOCAL類别最大容忍的延遲,如果超過,則退化到下一個級别NODE_LOCAL,否則等待不排程。退化到下一個級别NODE_LOCAL後排程流程也類似,看是否存在
host
對應的NODE_LOCAL類别的任務,如果存在,取出來排程,否則根據目前時間,判斷是否超過了NODE_LOCAL類别最大容忍的延遲,如果超過,則退化到下一個級别RACK_LOCAL,否則等待不排程,以此類推…..。當不滿足Locatity類别會選擇等待,直到下一輪排程重複上述流程,如果你比較激進,可以調大每個類别的最大容忍延遲時間,如果不滿足Locatity時就會等待多個排程周期,直到滿足或者超過延遲時間退化到下一個級别為止。
失敗重試與黑名單機制
除了選擇合适的Task排程運作外,還需要監控Task的執行狀态,前面也提到,與外部打交道的是SchedulerBackend,Task被送出到Executor啟動執行後,Executor會将執行狀态上報給SchedulerBackend,SchedulerBackend則告訴TaskScheduler,TaskScheduler找到該Task對應的TaskSetManager,并通知到該TaskSetManager,這樣TaskSetManager就知道Task的失敗與成功狀态,對于失敗的Task,會記錄它失敗的次數,如果失敗次數還沒有超過最大重試次數,那麼就把它放回待排程的Task池子中,否則整個Application失敗。
在記錄Task失敗次數過程中,會記錄它上一次失敗所在的Executor Id和Host,這樣下次再排程這個Task時,會使用黑名單機制,避免它被排程到上一次失敗的節點上,起到一定的容錯作用。黑名單記錄Task上一次失敗所在的Executor Id和Host,以及其對應的“黑暗”時間,“黑暗”時間是指這段時間内不要再往這個節點上排程這個Task了。
推測式執行
TaskScheduler在啟動SchedulerBackend後,還會啟動一個背景線程專門負責推測任務的排程,推測任務是指對一個Task在不同的Executor上啟動多個執行個體,如果有Task執行個體運作成功,則會幹掉其他Executor上運作的執行個體。推測排程線程會每隔固定時間檢查是否有Task需要推測執行,如果有,則會調用SchedulerBackend的
reviveOffers
去嘗試拿資源運作推測任務。
檢查是否有Task需要推測執行的邏輯最後會交到TaskSetManager,TaskSetManager采用基于統計的算法,檢查Task是否需要推測執行,算法流程大緻如下圖所示。
TaskSetManager首先會統計成功的Task數,當成功的Task數超過75%(可通過參數spark.speculation.quantile控制)時,再統計所有成功的Tasks的運作時間,得到一個中位數,用這個中位數乘以1.5(可通過參數spark.speculation.multiplier控制)得到運作時間門限,如果在運作的Tasks的運作時間超過這個門限,則對它啟用推測。算法邏輯較為簡單,其實就是對那些拖慢整體進度的Tasks啟用推測,以加速整個TaskSet即Stage的運作。
資源申請機制
在前文已經提過,ApplicationMaster和SchedulerBackend起來後,SchedulerBackend通過ApplicationMaster申請資源,ApplicationMaster就是用來專門适配YARN申請Container資源的,當申請到Container,會在相應Container上啟動Executor程序,其他事情就交給SchedulerBackend。Spark早期版本隻支援靜态資源申請,即一開始就指定用多少資源,在整個Spark應用程式運作過程中資源都不能改變,後來支援動态Executor申請,使用者不需要指定确切的Executor數量,Spark會動态調整Executor的數量以達到資源利用的最大化。
靜态資源申請
靜态資源申請是使用者在送出Spark應用程式時,就要提前估計應用程式需要使用的資源,包括Executor數(num_executor)、每個Executor上的core數(executor_cores)、每個Executor的記憶體(executor_memory)以及Driver的記憶體(driver_memory)。
在估計資源使用時,應當首先了解這些資源是怎麼用的。任務的并行度由分區數(Partitions)決定,一個Stage有多少分區,就會有多少Task。每個Task預設占用一個Core,一個Executor上的所有core共享Executor上的記憶體,一次并行運作的Task數等于num_executor*executor_cores,如果分區數超過該值,則需要運作多個輪次,一般來說建議運作3~5輪較為合适,否則考慮增加num_executor或executor_cores。由于一個Executor的所有tasks會共享記憶體executor_memory,是以建議executor_cores不宜過大。executor_memory的設定則需要綜合每個分區的資料量以及是否有緩存等邏輯。下圖描繪了一個應用程式内部資源利用情況。
動态資源申請
動态資源申請目前隻支援到Executor,即可以不用指定num_executor,通過參數spark.dynamicAllocation.enabled來控制。由于許多Spark應用程式一開始可能不需要那麼多Executor或者其本身就不需要太多Executor,是以不必一次性申請那麼多Executor,根據具體的任務數動态調整Executor的數量,盡可能做到資源的不浪費。由于動态Executor的調整會導緻Executor動态的添加與删除,如果删除Executor,其上面的中間Shuffle結果可能會丢失,這就需要借助第三方的ShuffleService了,如果Spark是部署在Yarn上,則可以在Yarn上配置Spark的ShuffleService,具體操作僅需做兩點:
- 首先在yarn-site.xml中加上如下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property> - 将Spark ShuffleService jar包
$SPARK_HOME/yarn/spark-*-yarn-shuffle.jar
- 拷貝到每台NodeManager的
$HADOOP_HOME/share/hadoop/yarn/lib/
-
下,并重新開機所有的NodeManager。
當啟用動态Executor申請時,在SparkContext初始化過程中會執行個體化ExecutorAllocationManager,它是被用來專門控制動态Executor申請邏輯的,動态Executor申請是一種基于目前Task負載壓力實作動态增删Executor的機制。一開始會按照參數
spark.dynamicAllocation.initialExecutors
- 設定的初始Executor數申請,然後根據目前積壓的Task數量,逐漸增長申請的Executor數,如果目前有積壓的Task,那麼取積壓的Task數和
spark.dynamicAllocation.maxExecutors
- 中的最小值作為Executor數上限,每次新增加申請的Executor為2的次方,即第一次增加1,第二次增加2,第三次增加4,…。另一方面,如果一個Executor在一段時間内都沒有Task運作,則将其回收,但是在Remove Executor時,要保證最少的Executor數,該值通過參數
spark.dynamicAllocation.minExecutors
- 來控制,如果Executor上有Cache的資料,則永遠不會被Remove,以保證中間資料不丢失。
結語
本文詳細闡述了Spark的任務排程,着重讨論Spark on Yarn的部署排程,剖析了從應用程式送出到運作的全過程。Spark Schedule算是Spark中的一個大子產品,它負責任務下發與監控等,基本上扮演了Spark大腦的角色。了解Spark Schedule有助于幫助我們清楚地認識Spark應用程式的運作軌迹,同時在我們實作其他系統時,也可以借鑒Spark的實作。