
Deep Modular Co-Attention Networks for Visual Question Answering
先了解下這個要幹嘛:
Visual Question Answering (VQA): 給一個圖檔和關于這個圖檔的問題,然後模型輸入這兩個資料,輸出答案。
文章中用得到的資料庫VQA-v2裡的一個例子:

把中間的亂七八糟給蓋住:
輸入問題:胡子是用什麼做的?
輸出答案:香蕉
需要設計網絡做到同時了解文本内容,抓住關鍵詞,同時了解圖檔中關鍵區域的内容:“哪裡是胡子”這個問題肯定得先定位出來才能解下來回答“是用什麼做的”。
網絡既能了解文本又能了解圖像,一聽就比較神奇,這就涉及到多模态(兩種不同的資料類型)了。
文章中認為此類問題的關鍵是 共同注意力機制 “co-attention”,同時關注文本中的key word以及圖檔中的key objects。
之前的研究可以利用淺層網絡實作 “co-attention”,但是效果一般,加深的網絡相比于淺層網絡也沒什麼提升。
文章中針對上面的問題,提出了 Modular Co-Attention Network 網絡,這個網絡又由MCA layer組合而成。
每個MCA layer都由兩個元素組成,1 self-attention 2 guided-attention
MCA layer
Modular Co-Attention Layer
兩個基本單元,self-attention unit (SA)和guided-attention unit (GA),本質上是一樣的,其實就是受transformer的啟發,the scaled dot-product attention ,具體可以參考[1];
這兩種單元可以做特定的組合,能夠得到三種不同結構的 MCA layer;
self-attention unit (SA)
一個輸入X;
一個輸出Z;
輸入 X X X X = [ x 1 ; . . . ; x m ] ∈ 2 R m ⇥ d x {X = [x_1; ...; x_m]}\in2 R^{m⇥d_x} X=[x1;...;xm]∈2Rm⇥dx
multi-head attention學習到了成對輸入元素之間的關系, < x i , x j > <x_i, x_j> <xi,xj>
得到的輸出Z,直接會經過FC(4d)-ReLU-Dropout(0.1)- FC(d);
guided-attention unit (GA)
兩個輸入X和Y;
一個輸出Z;
X ∈ R m ⇥ d x X\in R^{m⇥d_x} X∈Rm⇥dx
$Y = [y_1 ; …; y_n ]\in R^{n⇥d_y} $
Y對X的attention具有指導作用;
GA對X與Y元素之間 < x i , y j > <x_i, y_j> <xi,yj>的組合關系進行模組化;
組合
三種組合
不同的輸入以及連接配接方式;
MCAN
兩種deep co-attention模型:stacking 和encoder-decoder;
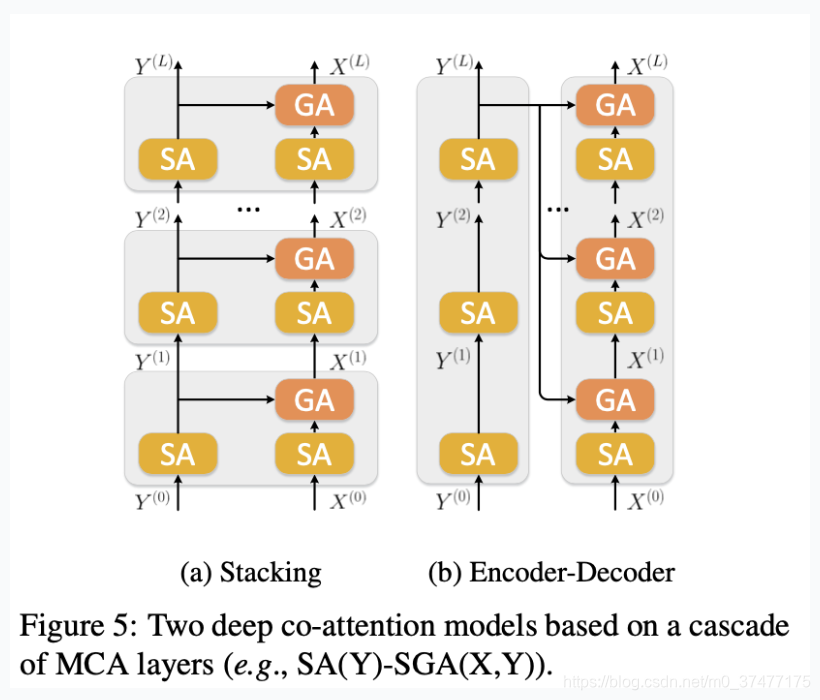
stacking模型是由多個MCA層串聯成的,輸出的是最終的圖像特征和問題特征。encoder-decoder模型思路來自于Transformer模型,編碼器是由L個SA單元來學習問題特征,解碼器是用SGA單元,根據問題特征來學習圖像特征。
圖像特征次元 X ∈ R m ⇥ d x X \in R^{m⇥d_x} X∈Rm⇥dx.
文本query是将輸入的問題先劃分為單詞,最多為14個單詞,之後再用300維的GloVe word embeddings方法将每一個單詞轉化為一個向量。詞嵌入再輸入一個單層的LSTM網絡(有個隐藏單元),輸出一個query的特征矩陣Y。
參考
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob
Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010, 2017.