https://help.aliyun.com/document_detail
資料壓縮與編碼
我們分為兩種情況,一種是壓縮、一種是編碼。
此為典型的儉約空間的做法,在一些場景下,甚至可以節約90%的空間
目前 我們建議采取 snappy 方式,編碼采取 DIFF 即可
Snappy在GZIP、LZO等衆多的壓縮格式中,壓縮率較高、編碼、解碼的速度較快,目前 平台已經預設支援
-
修改壓縮編碼的步驟:
-
1、修改表的屬性,此為壓縮編碼
-
alter 'test', NAME => 'f', COMPRESSION => 'snappy', DATA_BLOCK_ENCODING =>'DIFF'
-
2、壓縮編碼并不會立即生效,需要major_compact,此會耗時較長,注意在業務低峰期進行
-
major_compact 'test'
read讀取優化
其實HBase還是比較靈活的,關鍵看你是否使用得當,以下主要列舉一些讀的優化。HBase在生産中往往會遇到Full GC、程序OOM、RIT問題、讀取延遲較大等一些問題,使用更好的硬體往往可以解決一部分問題,但是還是需要使用的方式。
我們把優化分為:
用戶端優化、服務端優化、平台優化(ApsaraDB for HBase平台完成)
用戶端優化
get請求是否可以使用批量請求
這樣可以成倍減小用戶端與服務端的rpc次數,顯著提高吞吐量
-
Result[] re= table.get(List<Get> gets)
大scan緩存是否設定合理
scan一次性需求從服務端傳回大量的資料,用戶端發起一次請求,用戶端會分多批次傳回用戶端,這樣的設計是避免一次性傳輸較多的資料給服務端及用戶端有較大的壓力。目前 資料會加載到本地的緩存中,預設100條資料大小。 一些大scan需要擷取大量的資料,傳輸數百次甚至數萬的rpc請求。 我們建議可以 适當放開 緩存的大小。
-
scan.setCaching(int caching) //大scan可以設定為1000
請求指定列族或者列名
HBase是列族資料庫,同一個列族的資料存儲在一塊,不同列族是分開的,為了減小IO,建議指定列族或者列名
離線計算通路Hbase建議禁止緩存
當離線通路HBase時,往往就是一次性的讀取,此時讀取的資料沒有必要存放在blockcache中,建議在讀取時禁止緩存
-
scan.setBlockCache(false)
可幹預服務端優化
請求是否均衡
讀取的壓力是否都在一台或者幾台之中,在業務高峰期間可以檢視下,可以到 HBase管控平台檢視HBase的ui。如果有明顯的熱點,一勞永逸是重新設計rowkey,短期是 把熱點region嘗試拆分
BlockCache是否合理
BlockCache作為讀緩存,對于讀的性能比較重要,如果讀比較多,建議記憶體使用1:4的機器,比如:8cpu32g或者16pu64g的機器。目前可以調高 BlockCache 的數值,降低 Memstore 的數值。
在ApsaraDB for HBase控制台可以完成:hfile.block.cache.size 改為0.5 ; hbase.regionserver.global.memstore.size 改為0.3;再重新開機
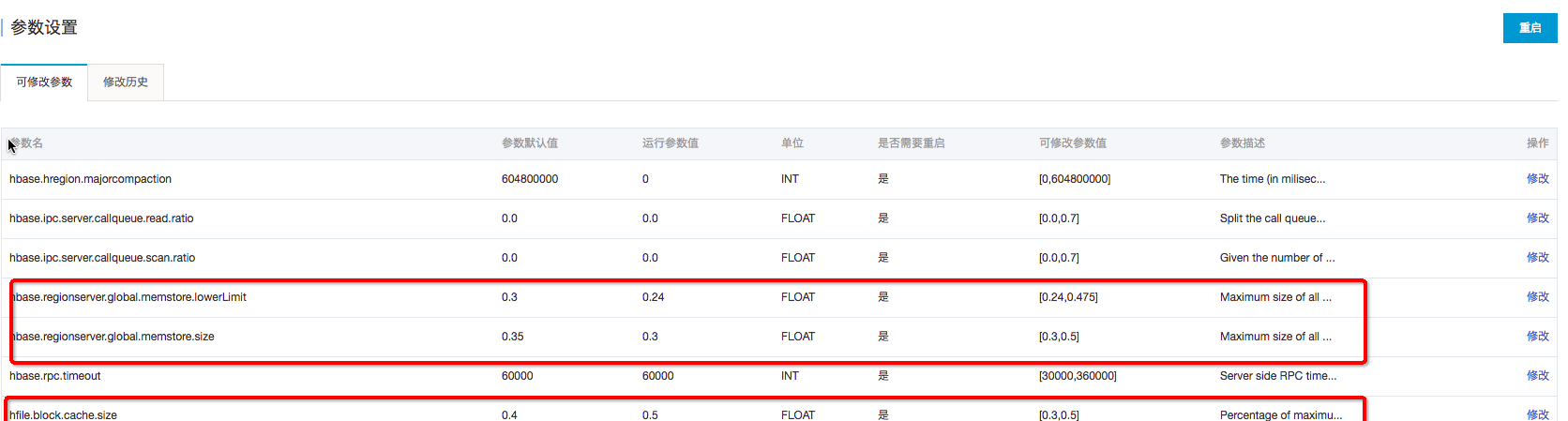
HFile檔案數目
因為讀取需要頻繁打開HFile,如果檔案越多,IO次數就越多,讀取的延遲就越高此 需要主要定時做 major compaction,如果晚上的業務壓力不大,可以在晚上做major compaction
Compaction是否消耗較多的系統資源
compaction主要是将HFile的小檔案合并成大檔案,提高後續業務的讀性能,但是也會帶來較大的資源消耗。Minor Compaction一般情況下不會帶來大量的系統資源消耗,除非因為配置不合理。 切勿在高峰期間做 major compaction。 建議在業務低峰期做major compaction。
Bloomfilter設定是否合理
Bloomfilter主要用來在查詢時,過濾HFile的,避免不需要的IO操作。Bloomfilter能提高讀取的性能,一般情況下建立表,都會預設設定為:BLOOMFILTER => ‘ROW’
平台端優化
資料本地率是否太低?(平台已經優化)
Hbase 的HFile,在本地是否有檔案,如果有檔案可以走Short-Circuit Local Read目前平台在重新開機、磁盤擴容時,都會自動拉回移動出去的region,不降低資料本地率;另外 定期做major compaction也有益于提高本地化率
Short-Circuit Local Read (已經預設開啟)
目前HDFS讀取資料需要經過DataNode,開啟Short-Circuit Local Read後,用戶端可以直接讀取本地資料
Hedged Read (已經預設開啟)
優先會通過Short-Circuit Local Read功能嘗試本地讀。但是在某些特殊情況下,有可能會出現因為磁盤問題或者網絡問題引起的短時間本地讀取失敗,為了應對這類問題,開發出了Hedged Read。該機制基本工作原理為:用戶端發起一個本地讀,一旦一段時間之後還沒有傳回,用戶端将會向其他DataNode發送相同資料的請求。哪一個請求先傳回,另一個就會被丢棄
關閉swap區(已經預設關閉)
swap是當實體記憶體不足時,拿出部分的硬碟空間當做swap使用,解決記憶體不足的情況。但是會有較大的延遲的問題,是以我們HBase平台預設關閉。 但是關閉swap導緻anon-rss很高,page reclaim沒辦法reclaim足夠的page,可能導緻核心挂住,平台已經采取相關隔離措施避免此情況。
write寫入優化
HBase基于LSM模式,寫是寫HLOG及Memory的,也就是基本沒有随機的IO,是以在寫鍊路上性能高校還比較平穩。很多時候,寫都是用可靠性來換取性能。
用戶端優化
批量寫
也是為了減少rpc的次數
-
HTable.put(List<Put>)
Auto Flush
autoflush=false可以提升幾倍的寫性能,但是還是要注意,直到資料超過2M(hbase.client.write.buffer決定)或使用者執行了hbase.flushcommits()時才向regionserver送出請求。需要注意并不是寫到了遠端。
HTable.setWriteBufferSize(writeBufferSize) 可以設定buffer的大小
服務端優化
WAL Flag
不寫WAL可以成倍提升性能,因為不需要寫HLog,減少3次IO,寫MemStore是記憶體操作
是以資料可靠性為代價的,在資料導入時,可以關閉WAL
增大memstore的記憶體
目前可以調高Memstore 的數值,降低 BlockCache 的數,跟讀優化的思路正好相反
大量的HFile産生
如果寫很快,很容易帶來大量的HFile,因為此時HFile合并的速度還沒有寫入的速度快
需要在業務低峰期做majorcompaction,充分利用系統資源;如果HFile降低不下來,則需要添加節點
讀寫分離
HBase有三個典型的API : read(get、scan)、write ,我們有時候希望這三個通路盡可能的互相不影響,可以參考如下配置:(線上預設沒有配置讀寫分離)
場景
- 寫請求與讀請求都比較高,業務往往接受:寫請求慢點可以,讀請求越快越好,最好有單獨的資源保障
- scan與get都比較多,業務希望scan不影響get(因為scan比較消耗資源)
相關配置:
- hbase.ipc.server.callqueue.read.ratio
- hbase.ipc.server.callqueue.scan.ratio
具體含義:
- hbase.ipc.server.callqueue.read.ratio 設定為0.5,代表有50%的線程數處理讀請求
- 如果再設定hbase.ipc.server.callqueue.scan.ratio 設定為0.5,則代表在50%的讀線程之中,再有50%的線程處理scan,也就是全部線程的25%
操作步驟
- 打開HBase控制台,找到執行個體,點選進去,找到 - 參數設定
- 修改配置,按照業務讀寫情況
- 不重新開機不會生效,請在業務低峰期重新開機叢集,重新開機不會中斷業務,可能會有一些抖動

請根據實際的業務配置以上數值,預設情況下是沒有配置的,也就是讀寫都共享。
預分區
初次接觸HBase的客戶,在建立HBase表的時候,不指分區的數目,另外就是rowkey設計不合理,導緻熱點。
最為常見的建表語句為:
create ‘t3’,’f1’, { NUMREGIONS => 50, SPLITALGO => ‘HexStringSplit’ , COMPRESSION => ‘snappy’}
- 其中 NUMREGIONS 為 region的個數,一般取10-500左右,叢集規模大,可以取大一些,
- SPLITALGO 為 rowkey分割的算法:Hbase自帶了兩種pre-split的算法,分别是 HexStringSplit 和 UniformSplit,HexStringSplit 如果我們的row key是十六進制的字元串作為字首的,就比較适合用HexStringSplit,關于rowkey的設計可以參考:RowKey設計
- COMPRESSION壓縮算法,參考:資料壓縮與編碼
Rowkey設計
HBase的rowkey設計可以說是使用HBase最為重要的事情,直接影響到HBase的性能,常見的RowKey的設計問題及對應通路為:
Hotspotting
的行由行鍵按字典順序排序,這樣的設計優化了掃描,允許存儲相關的行或者那些将被一起讀的鄰近的行。然而,設計不好的行鍵是導緻 hotspotting 的常見原因。當大量的用戶端流量( traffic )被定向在叢集上的一個或幾個節點時,就會發生 hotspotting。這些流量可能代表着讀、寫或其他操作。流量超過了承載該region的單個機器所能負荷的量,這就會導緻性能下降并有可能造成region的不可用。在同一 RegionServer 上的其他region也可能會受到其不良影響,因為主機無法提供服務所請求的負載。設計使叢集能被充分均勻地使用的資料通路模式是至關重要的。
為了防止在寫操作時出現 hotspotting ,設計行鍵時應該使得資料盡量同時往多個region上寫,而避免隻向一個region寫,除非那些行真的有必要寫在一個region裡。
下面介紹了集中常用的避免 hotspotting 的技巧,它們各有優劣:
Salting
Salting 從某種程度上看與加密無關,它指的是将随機數放在行鍵的起始處。進一步說,salting給每一行鍵随機指定了一個字首來讓它與其他行鍵有着不同的排序。所有可能字首的數量對應于要分散資料的region的數量。如果有幾個“hot”的行鍵模式,而這些模式在其他更均勻分布的行裡反複出現,salting就能到幫助。下面的例子說明了salting能在多個RegionServer間分散負載,同時也說明了它在讀操作時候的負面影響。
假設行鍵的清單如下,表按照每個字母對應一個region來分割。字首‘a’是一個region,‘b’就是另一個region。在這張表中,所有以‘f’開頭的行都屬于同一個region。這個例子關注的行和鍵如下:
-
foo0001
-
foo0002
-
foo0003
-
foo0004
現在,假設想将它們分散到不同的region上,就需要用到四種不同的 salts :a,b,c,d。在這種情況下,每種字母字首都對應着不同的一個region。用上這些salts後,便有了下面這樣的行鍵。由于現在想把它們分到四個獨立的區域,理論上吞吐量會是之前寫到同一region的情況的吞吐量的四倍。
-
a-foo0003
-
b-foo0001
-
c-foo0004
-
d-foo0002
如果想新增一行,新增的一行會被随機指定四個可能的salt值中的一個,并放在某條已存在的行的旁邊。
-
a-foo0003
-
b-foo0001
-
c-foo0003
-
c-foo0004
-
d-foo0002
由于字首的指派是随機的,因而如果想要按照字典順序找到這些行,則需要做更多的工作。從這個角度上看,salting增加了寫操作的吞吐量,卻也增大了讀操作的開銷。
Hashing
可用一個單向的 hash 散列來取代随機指派字首。這樣能使一個給定的行在“salted”時有相同的字首,從某種程度上說,這在分散了RegionServer間的負載的同時,也允許在讀操作時能夠預測。确定性hash( deterministic hash )能讓用戶端重建完整的行鍵,以及像正常的一樣用Get操作重新獲得想要的行。
考慮和上述salting一樣的情景,現在可以用單向hash來得到行鍵foo0003,并可預測得‘a’這個字首。然後為了重新獲得這一行,需要先知道它的鍵。可以進一步優化這一方法,如使得将特定的鍵對總是在相同的region。
Reversing the Key(反轉鍵)
第三種預防hotspotting的方法是反轉一段固定長度或者可數的鍵,來讓最常改變的部分(最低顯著位, the least significant digit )在第一位,這樣有效地打亂了行鍵,但是卻犧牲了行排序的屬性
單調遞增行鍵/時序資料
在一個叢集中,一個導入資料的程序鎖住不動,所有的client都在等待一個region(因而也就是一個單個節點),過了一會後,變成了下一個region… 如果使用了單調遞增或者時序的key便會造成這樣的問題。使用了順序的key會将本沒有順序的資料變得有順序,把負載壓在一台機器上。是以要盡量避免時間戳或者序列(e.g. 1, 2, 3)這樣的行鍵。
如果需要導入時間順序的檔案(如log)到HBase中,可以學習OpenTSDB的做法。它有一個頁面來描述它的HBase模式。OpenTSDB的Key的格式是[metric_type][event_timestamp],乍一看,這似乎違背了不能将timestamp做key的建議,但是它并沒有将timestamp作為key的一個關鍵位置,有成百上千的metric_type就足夠将壓力分散到各個region了。是以,盡管有着連續的資料輸入流,Put操作依舊能被分散在表中的各個region中
簡化行和列
在HBase中,值是作為一個單元(Cell)儲存在系統的中的,要定位一個單元,需要行,列名和時間戳。通常情況下,如果行和列的名字要是太大(甚至比value的大小還要大)的話,可能會遇到一些有趣的情況。在HBase的存儲檔案( storefiles )中,有一個索引用來友善值的随機通路,但是通路一個單元的坐标要是太大的話,會占用很大的記憶體,這個索引會被用盡。要想解決這個問題,可以設定一個更大的塊大小,也可以使用更小的行和列名 。壓縮也能得到更大指數。
大部分時候,細微的低效不會影響很大。但不幸的是,在這裡卻不能忽略。無論是列族、屬性和行鍵都會在資料中重複上億次。
列族
盡量使列族名小,最好一個字元。(如:f 表示)
屬性
詳細屬性名 (如:”myVeryImportantAttribute”) 易讀,最好還是用短屬性名 (e.g., “via”) 儲存到HBase.
行鍵長度
讓行鍵短到可讀即可,這樣對擷取資料有幫助(e.g., Get vs. Scan)。短鍵對通路資料無用,并不比長鍵對get/scan更好。設計行鍵需要權衡
位元組模式
long類型有8位元組。8位元組内可以儲存無符号數字到18,446,744,073,709,551,615。 如果用字元串儲存——假設一個位元組一個字元——需要将近3倍的位元組數。
下面是示例代碼,可以自己運作一下:
-
// long
-
//
-
long l =
-
byte[] lb = Bytes.toBytes(l);
-
System.out.println("long bytes length: " + lb.length); // returns 8
-
String s = String.valueOf(l);
-
byte[] sb = Bytes.toBytes(s);
-
System.out.println("long as string length: " + sb.length); // returns 10
-
// hash
-
//
-
MessageDigest md = MessageDigest.getInstance("MD5");
-
byte[] digest = md.digest(Bytes.toBytes(s));
-
System.out.println("md5 digest bytes length: " + digest.length); // returns 16
-
String sDigest = new String(digest);
-
byte[] sbDigest = Bytes.toBytes(sDigest);
-
System.out.println("md5 digest as string length: " + sbDigest.length); // returns 26
不幸的是,用二進制表示會使資料在代碼之外難以閱讀。下例便是當需要增加一個值時會看到的shell:
-
hbase(main):
-
COUNTER VALUE =
-
hbase(main):
-
COLUMN CELL
-
f:q timestamp=
這個shell盡力在列印一個字元串,但在這種情況下,它決定隻将進制列印出來。當在region名内行鍵會發生相同的情況。如果知道儲存的是什麼,那自是沒問題,但當任意資料都可能被放到相同單元的時候,這将會變得難以閱讀。這是最需要權衡之處。
倒序時間戳
一個資料庫處理的通常問題是找到最近版本的值。采用倒序時間戳作為鍵的一部分可以對此特定情況有很大幫助。該技術包含追加( Long.MAX_VALUE - timestamp ) 到key的後面,如 [key][reverse_timestamp] 。
表内[key]的最近的值可以用[key]進行Scan,找到并擷取第一個記錄。由于HBase行鍵是排序的,該鍵排在任何比它老的行鍵的前面,是以是第一個。
該技術可以用于代替版本數,其目的是儲存所有版本到“永遠”(或一段很長時間) 。同時,采用同樣的Scan技術,可以很快擷取其他版本。
行鍵和列族
行鍵在列族範圍内。是以同樣的行鍵可以在同一個表的每個列族中存在而不會沖突。
行鍵不可改
行鍵不能改變。唯一可以“改變”的方式是删除然後再插入。這是一個常問問題,是以要注意開始就要讓行鍵正确(且/或在插入很多資料之前)。
行鍵和region split的關系
如果已經 pre-split (預裂)了表,接下來關鍵要了解行鍵是如何在region邊界分布的。為了說明為什麼這很重要,可考慮用可顯示的16位字元作為鍵的關鍵位置(e.g., “0000000000000000” to “ffffffffffffffff”)這個例子。通過 Bytes.split來分割鍵的範圍(這是當用 Admin.createTable(byte[] startKey, byte[] endKey, numRegions) 建立region時的一種拆分手段),這樣會分得10個region。
但問題在于,資料将會堆放在前兩個region以及最後一個region,這樣就會導緻某幾個region由于資料分布不均勻而特别忙。為了了解其中緣由,需要考慮ASCII Table的結構。根據ASCII表,“0”是第48号,“f”是102号;但58到96号是個巨大的間隙,考慮到在這裡僅[0-9]和[a-f]這些值是有意義的,因而這個區間裡的值不會出現在鍵空間( keyspace ),進而中間區域的region将永遠不會用到。為了pre-split這個例子中的鍵空間,需要自定義拆分。
教程1:預裂表( pre-splitting tables ) 是個很好的實踐,但pre-split時要注意使得所有的region都能在鍵空間中找到對應。盡管例子中解決的問題是關于16位鍵的鍵空間,但其他任何空間也是同樣的道理。
教程2:16位鍵(通常用到可顯示的資料中)盡管通常不可取,但隻要所有的region都能在鍵空間找到對應,它依舊能和預裂表配合使用。
一下case說明了如何16位鍵預分區
-
public static boolean createTable(Admin admin, HTableDescriptor table, byte[][] splits)
-
throws IOException {
-
try {
-
admin.createTable( table, splits );
-
return true;
-
} catch (TableExistsException e) {
-
logger.info("table " + table.getNameAsString() + " already exists");
-
// the table already exists...
-
return false;
-
}
-
}
-
public static byte[][] getHexSplits(String startKey, String endKey, int numRegions) {
-
byte[][] splits = new byte[numRegions-
-
BigInteger lowestKey = new BigInteger(startKey,
-
BigInteger highestKey = new BigInteger(endKey,
-
BigInteger range = highestKey.subtract(lowestKey);
-
BigInteger regionIncrement = range.divide(BigInteger.valueOf(numRegions));
-
lowestKey = lowestKey.add(regionIncrement);
-
for(int i=
-
BigInteger key = lowestKey.add(regionIncrement.multiply(BigInteger.valueOf(i)));
-
byte[] b = String.format("%016x", key).getBytes();
-
splits[i] = b;
-
}
-
return splits;
-
}
schema設計原則
Schema 建立
可以使用HBase Shell或者java API的HBaseAdmin來建立和編輯HBase的Schema
當修改列族時,建議先将這張表下線(disable):
-
Configuration config = HBaseConfiguration.create();
-
HBaseAdmin admin = new HBaseAdmin(config);
-
String table = "Test";
-
admin.disableTable(table); // 将表下線
-
HColumnDescriptor f1 = ...;
-
admin.addColumn(table, f1); // 增加新的列族
-
HColumnDescriptor f2 = ...;
-
admin.modifyColumn(table, f2); // 修改列族
-
HColumnDescriptor f3 = ...;
-
admin.modifyColumn(table, f3); // 修改列族
-
admin.enableTable(table);
更新
當表或者列族改變時(包括:編碼方式、壓力格式、block大小等等),都将會在下次marjor compaction時或者StoreFile重寫時生效
表模式設計經驗
- region規模大小再10到50g之間;
- 單個cell不超過10mMB,如果超過10MB,請使用mob(目前 ApsaraDB for HBase不支援,2.0會支援),再大可以考慮直接存在OSS中
- 一個典型的表中含有1-3個列族,hbase表不應該設計成類似RDBMS的表
- 一個表大約 50到100個 region,1或者2個列族。記住:每個列族内是連續的,不同列族之間是分割的
- 盡量讓你的列族名短,因為存儲時每個value都包含列族名(忽略字首編碼, prefix encoding )
- 如果在基于時間的機器上存儲資料這和日志資訊,row key是由裝置ID加上時間得到的,那最後得到這樣的模式:除了某個特定的時間段,舊的資料region沒有額外的寫。這樣的情況下,得到的是少量的活躍region和大量沒有新寫入的舊region。這時由于資源消耗僅僅來自活躍的region,大量的Region能被接受
列族的數量
現在HBase并不能很好的處理兩個或者三個以上的列族,是以盡量讓列族數量少一些。
目前, flush 和 compaction 操作是針對一個region。是以當一個列族操作大量資料的時候會引發一個flush。那些鄰近的列族也有進行flush操作,盡管它們沒有操作多少資料。
compaction操作現在是根據一個列族下的全部檔案的數量觸發的,而不是根據檔案大小觸發的。
當很多的列族在flush和compaction時,會造成很多沒用的I/O負載(要想解決這個問題,需要将flush和compaction操作隻針對一個列族) 。
盡量在模式中隻針對一個列族操作。将使用率相近的列歸為一列族,這樣每次通路時就隻用通路一個列族,提高效率。
列族的基數
如果一個表存在多個列族,要注意列族之間基數(如行數)相差不要太大。 例如列族A有100萬行,列族B有10億行,按照行鍵切分後,列族A可能被分散到很多很多region(及RegionServer),這導緻掃描列族A十分低效。
版本的數量
行的版本的數量是HColumnDescriptor設定的,每個列族可以單獨設定,預設是3。這個設定是很重要的,因為HBase是不會去覆寫一個值的,它隻會在後面在追加寫,用時間戳來區分、過早的版本會在執行major compaction時删除,這些在HBase資料模型有描述。這個版本的值可以根據具體的應用增加減少。
不推薦将版本最大值設到一個很高的水準 (如, 成百或更多),除非老資料對你很重要。因為這會導緻存儲檔案變得極大。
最小版本數
和行的最大版本數一樣,最小版本數也是通過HColumnDescriptor 在每個列族中設定的。最小版本數預設值是0,表示該特性禁用。 最小版本數參數和存活時間一起使用,允許配置如“儲存最後T秒有價值資料,最多N個版本,但最少約M個版本”(M是最小版本數,M<N)。 該參數僅在存活時間對列族啟用,且必須小于行版本數。
支援資料類型
HBase通過Put和Result支援 bytes-in/bytes-out 接口,是以任何可被轉為位元組數組的東西可以作為值存入。輸入可以是字元串、數字、複雜對象、甚至圖像,它們能轉為位元組。
存在值的實際長度限制 (如:儲存10-50MB對象到HBase可能對查詢來說太長); 搜尋郵件清單擷取本話題的對話。HBase的所有行都遵循HBase資料模型包括版本化。設計時需考慮到這些,以及列族的塊大小。
存活時間
列族可以設定TTL秒數,HBase在逾時後将自動删除資料,HBase裡面TTL時間時區是UTC
存儲檔案僅包含有過期的行(expired rows),它們可通過minor compaction删除。将 hbase.store.delete.expired.storefile設定為false,可禁用此功能;将最小版本數設定成非0值也可達到同樣的效果。
HBase的最新版本還支援将設定的時間存放在每個結構單元。TTL單元通過Mutation#setTTL作為更變請求(Appends, Increments, Puts, etc.)的一個屬性送出,如果TTL的屬性被設定了,它将會應用到由于該更變操作更新的所有單元上。cell TTL handling和ColumnFamily TTLs間有兩個顯著的差别:
1.Cell TTLs的數量級是毫秒而不是秒;
2.一個cell TTL不能超出ColumnFamily TTLs設定的有效時間。
轉載于:https://www.cnblogs.com/davidwang456/articles/9253631.html