文章轉自:知乎 原文連結:https://zhuanlan.zhihu.com/p/146165099
作者:Danny明澤
簡介
語義分割是計算機視覺中一個基本而又具有挑戰性的問題。通過語義分割獲得更好的場景,有利于許多應用程式,如機器人,視覺SLAM和虛拟/增強現實。與基于RGB圖像的方法相比,基于深度(RGB-D)的RGB方法可以利用來自場景的額外的三維幾何資訊,有效地解決單一2D顯示方法所面臨的挑戰,然而,大多數已有的方法都需要精确的深度圖作為場景分割的輸入,這嚴重限制了它們的應用。現有的資料庫RGB-D資料集 i.e NYU-v2, SUN-RGBD 的深度圖/視差圖不夠精确,準确來說有很大缺陷,例如中心目标标簽像素的缺失[0,0,0],導緻最終預測的結果失敗;
在本文中,提出在挖掘有用的深度域資訊的同時,通過提取幾何感覺嵌入來聯合推斷語義和深度資訊,以消除這種強限制。此外,通過提出的幾何感覺傳播架構和多個跳躍特征融合塊,利用所學的嵌入知識來提高語義分割的品質。通過将單任務預測網絡解耦為語義分割和幾何嵌入學習兩個聯合任務,并結合提出的資訊傳播和特征融合架構,在公開資料及上取得了 state-of-the-art結果。
工作描述:
在這項工作中,我們提出通過學習密集的深度嵌入的聯合推理架構來提取/提取幾何感覺的資訊,用于單個RGB圖像的語義分割。該模型沒有直接采用深度資訊作為輸入,而是将深度圖嵌入,與RGB輸入一起提取,進而指導語義分割。在該架構中,通過提出的幾何感覺傳播塊将學習到的嵌入資訊與二維外觀特征融合,利用幾何親和性來指導語義傳播。此外,發現分割結果往往缺乏細節,特别是近物體邊界。在特征空間中提出了一種增量的跨尺度融合方案,進而進一步豐富了結構細節。一些對象可能有非常相似的2D外觀,不能很好地識别。該模型能夠很好地将三維幾何資訊嵌入到所學特征中,使預測具有語義一緻性和幾何一緻性。
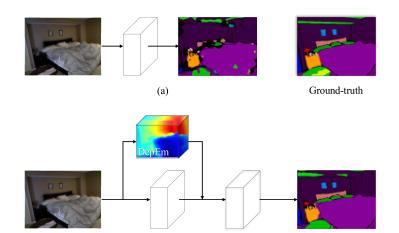
如圖所示,僅根據二維特征很難對枕頭進行分割,而通過學習嵌入,由于枕頭的三維幾何資訊與周圍環境不同,可以很好地進行分類。床的形狀也受益于學習的嵌入,它揭示了提煉的幾何資訊的有效性。我們的方法的關鍵思想是預測語義标簽從單一的RGB圖像,同時考慮三維幾何資訊隐含。
本文的主要貢獻歸納為:
1)提出了一種新的方法,通過隐式深度推斷提取幾何感覺嵌入,有效地指導RGB輸入場景分割。
2)該聯合架構實作了深度标簽和語義标簽之間的資訊融合,并具有端到端可訓練性。
3)模型在NYU-Dv2和SUN RGBD的室内語義分割資料集方面達到了最先進的性能。
3. 幾何感覺蒸餾
提出了幾何感覺精餾的架構,以隐式地提高分割性能。整個網絡通過一個聯合目标函數進行端到端的訓練。
3.1 學習深度感覺嵌入
這項工作的目标是利用幾何(深度)資訊進行語義分割,而不需要額外的深度圖作為輸入。一種直覺的方法是首先從輸入的RGB圖像中預測深度圖,然後将深度資訊并入傳統的RGB- d分割管道。本文建議從RGB圖像中學習一種深度感覺嵌入方法,并同時進行語義分割,而不是采用這種順序的解決方案。将深度感覺嵌入定義為在語義層次上對深度資訊和像素親和力進行編碼的表示。
給定一個RGB圖像像素I,深度感覺嵌入是從一個可學習的投影函數g(I),它将RGB像素轉換到一個高維空間,嵌入相應的特征。然後将嵌入學習模組化為一個優化問題:

其中E(x,x)為資料拟合項,D為提供需要通過投影嵌入的深度資訊的GT。第二項s(x) = E(g (x),x)是語義項,目的是嵌入語義資訊,n是像素的總數。
為了得到一個好的投影g,用一個深度神經網絡模型來參數化它,通過反向傳播來優化嵌入。是以,g被定義為f,其中f是一個深度CNN。然後将優化重新表述為:
3.2 幾何感覺的導引傳播---GAP
在學習了嵌入後,将其應用于語義分割的即時驗證。提出一種幾何感覺傳播(GAP)方法來利用已學習的嵌入作為指導。通過這種方式,深度嵌入作為一種親和引導,提供幾何資訊,以便更好地組合這些特征。給定嵌入空間中的一個點i與其相鄰點j,對于用于預測語義标簽的分數圖中位置j對應的特征點pj,其在位置i的傳播輸出q i可表示為:
其中Gem = f(I)為學習的深度嵌入,W ij為幾何指導G em導出的傳播權值。由于W ij表示嵌入空間的幾何親和力,這裡我們将其定義為解耦嵌入的點積為:
兩個參數将原始嵌入解耦為兩個子嵌入。為了應對傳播過程中維數的變化,進一步利用映射算法将語義特征一緻地投影到嵌入空間中。特别是傳播權由幾個卷積單元設計,這些單元可以通過反向傳播自動學習。特别地,将原始語義特征加入到傳播結果中,避免了整個傳播過程的中斷。将所提出的間隙塊定義為:
3.3 模型結構
通過引導傳播和金字塔特征融合提取幾何感覺資訊,進行精确分割。如下圖所示,該網絡由共享骨幹網絡、語義分割分支、深度嵌入分支、感覺幾何傳播塊、跳過金字塔融合塊五部分組成。所提出的網絡在全球範圍内遵循一種編解碼器結構,具有多任務預測。該編碼器的網絡權值由兩種任務共享。在解碼器部分,上分支通過預測深度圖來預測語義标簽,下分支通過預測深度圖來學習深度嵌入。
将深度分支(通過總和)傳播到各個分支以提供多尺度深度引導。在解碼器中,還傳播不同的尺度特征,以豐富最後一層的輸出。解碼器的每一層都是上采樣,然後是卷積。在語義分支的末端應用幾何感覺傳播塊(GAP),以學習到的嵌入作為指導,提高語義特征的品質。通過skip pyramid fusion block (SPF),結合來自骨幹網的多級特征圖,進一步細化蒸餾後的輸出。最後使用來自底部SPF塊的得分圖進行語義标簽的預測。對最右邊的特征和每一級SPF側輸出進行語義監控。相應的深度映射作為學習嵌入的超視覺。整個網絡由一個聯合目标函數端到端進行訓練(具體見目标函數部分)。
Geometry-Aware傳播
幾何感覺傳播是通過幾個卷積層、批處理歸一化和元素處理來實作的。詳細結構如圖下所示。深度嵌入首先被發送到兩個conv單元,以實作幾何親和力。然後以幾何親和力為導向,與語義特征進行融合。最後,将原始語義特征與融合的資訊結合在一起輸出,如圖3中的藍色塊所示。整個傳播主體獲得語義特征的次元。在不知道深層組合政策的情況下,将深度特征和顔色特征融合在一起,深度資訊指導特征融合。
Skip Pyramid Fusion
跳連金字塔融合。當圖像通過編碼器和解碼器時,可能會丢失很多細節資訊,試最終的語義特征圖中豐富和恢複更多的細節,如下所示。靈感來自特征金字塔網絡的目标檢測,利用多層次的特征從編碼器骨幹通過跳躍連接配接。由于編碼器和解碼器之間的特征空間是最稀疏的、細節最少的,解碼器最終恢複的特征圖幾乎不包含有用的細節。是以,向編碼器部分尋求更多的資訊。skip - pyramid fusion (SPF) block的結構如圖下所示。第一個SPF(spf1)将提取出來的特征作為輸入,經過1×1卷積,适當調整大小後與來自編碼器骨幹的特征圖進行拼接。經過3×3卷積後,組合的特征被傳播到另一個SPF。同時,每個SPF預測一個側輸出用于語義分割。
3.4損失函數
為了緩解資料不平衡問題,把用于對象檢測的丢失函數擴充到義分割任務中,如下所示:
除了語義監督外,深度感覺嵌入的學習還需要深度領域的監督。根據最先進的算法進行深度估計,我們使用berHu損失作為我們的深度監督定義為:
最後結合中間層語義預測(k層聚合)的損失Lsk (spf k處的Ls),最終的聯合損失函數為:
4 結果對比
在NYU-Dv2資料集上的結果比較如下:
在NYU-Dv2資料集上的結果比較如下:
各個類别分類準确性比較如下:
Ablation Study的結果
5 分割結果圖
6 結論
充分利用三維幾何資訊的深度感覺嵌入隐式提取的單一RGB圖像語義分割。通過解耦共享骨幹網絡,共同推導了幾何精餾和動态标簽預測。通過幾何感覺的傳播結構,将學習到的嵌入作為改進語義特征的指導。通過跳過金字塔融合塊,将提取出來的特征進一步回報到共享主幹中,與多層次的上下文資訊融合。模型僅以一個RGB圖像作為輸入,就可以同時擷取二維外觀和三維幾何資訊。在室内RGB-D語義分割的實驗結果表明,模型取得了較先進的方法更好的性能。