小樣本學習&元學習經典論文整理||持續更新
核心思想
本文提出一種基于參數優化的小樣本學習算法(MetaNAS)。本文最重要的改進就是将神經架構搜尋(neural architecture search,NAS)引入到小樣本學習算法中,簡單地了解就是MAML和Reptile等元學習算法,是在确定網絡結構的基礎上,通過元訓練的方式獲得較好的初始化參數,而本文引入NAS後,不僅要對初始化參數進行學習,而且要對網絡結構參數進行學習。為了實作這一想法,作者将經典的NAS算法DARTS和小樣本學習算法Reptile進行了結合,為了友善大家了解,我們首先介紹一下DARTS算法的過程,如下圖所示
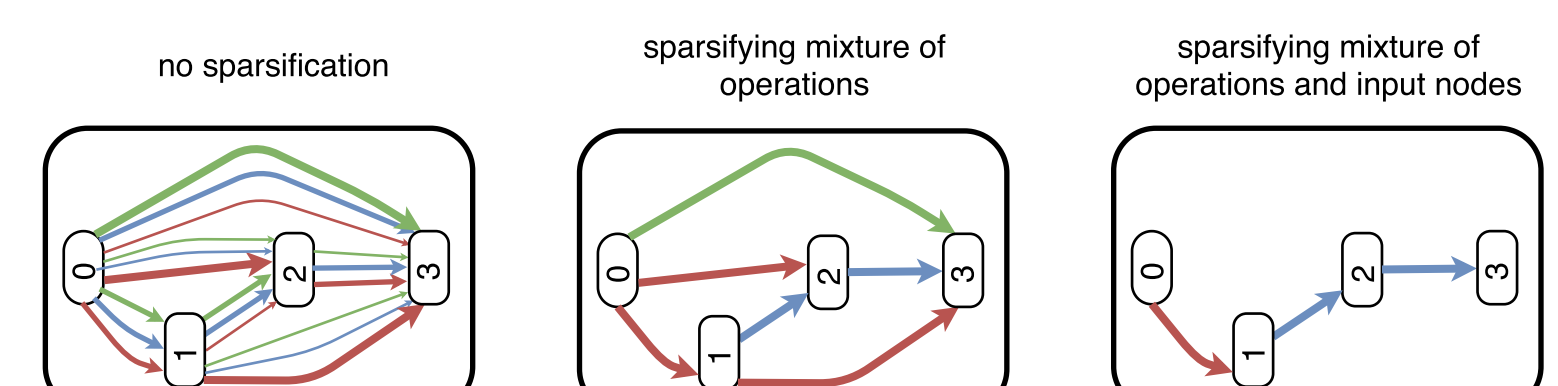
圖中帶有數字的矩形塊表示網絡中的結點,或者就是許多組特征圖,不同顔色的連線分别表示不同的操作(如3 * 3的卷積,5 * 5的卷積和最大值池化等),而連線的粗細表示不同操作所占的權重比例。經過NAS搜尋得到的網絡結構如最左側的圖所示,各個結點之間是稠密連結的,每兩個結點之間都有三種不同的操作方式,隻不過每種操作所占的比例不同,這一過程如下式

式中 x ( j ) x^{(j)} x(j)表示第 j j j個節點處的特征圖, O \mathcal{O} O表示所有可能操作的集合, α ^ o i , j \hat{\alpha}_o^{i,j} α^oi,j表示從節點 x ( i ) x^{(i)} x(i)到結點 x ( j ) x^{(j)} x(j)之間操作 o o o所占的權重比例, w o i , j w_o^{i,j} woi,j就表示操作 o o o所包含的正常參數,如卷積核的權重值等。而NAS搜尋的過程最重要的就是學習權重參數 α ^ o i , j \hat{\alpha}_o^{i,j} α^oi,j其計算方式如下
可以看到DARTS是通過權重求和的方式,将所有的操作混合起來,然後将所有 x ( j ) x^{(j)} x(j)結點之前的輸出都累加起來作為結點 x ( j ) x^{(j)} x(j)的輸入。通過這種混合操作,就将原本節點之間多種操作方式融合為一種,結點間的連接配接變得稀疏了一些,如中間的圖所示。但是盡管如此,每個結點的輸入都包含之前所有結點的輸出,結點之間的連接配接還是過于稠密,為了得到最終的網絡模型,DARTS算法采用一種硬剪枝(hard-pruning)的方式,對于每個結點僅保留1-2個輸入,其他輸入全部删去(如最右側的圖所示),但這種方式會導緻模型性能下降,是以需要将剪枝後的模型進行重訓練。
關于本文的另一個基礎算法MAML或Reptile可以參看我先前的筆記,這裡不再贅述。本文則是在MAML或Reptile的基礎上增加對于網絡結構權重參數 α o i , j \alpha_o^{i,j} αoi,j的元學習部分,在任務學習階段不僅要更新原本的權重參數 w w w還要更新結構參數 α \alpha α,計算過程如下
同理在元學習階段也需要對兩個參數進行更新,對于MAML算法,其計算過程如下
對于Reptile算法,其計算過程如下
同DARTS算法一樣,在得到網絡結構權重參數 α \alpha α後需要進行剪枝操作,但原本的硬剪枝操作存在兩個問題:1.剪枝後需要重訓練,這對于需要分成多個任務進行訓練的小樣本學習算法而言,成本太高;2.對于小樣本學習多個任務而言,訓練得到的網絡結構是相同的,不能根據不同的任務調整網絡結構。針對上述兩個問題,本文提出一種柔性剪枝(soft-pruning)的方法,具體的實作過程就是給 α ^ o i , j \hat{\alpha}_o^{i,j} α^oi,j計算中增加一個退火溫度參數 τ α \tau_{\alpha} τα,如下式所示
随着溫度參數 τ α \tau_{\alpha} τα逐漸衰退到0,網絡結構權重參數 α ^ o i , j \hat{\alpha}_o^{i,j} α^oi,j會收斂到0或1,這樣就相當于獲得了一個獨熱向量,兩個結點間多種操作中隻有一種操作的權重接近1,其他的都接近0(相當于被剪枝)。用這一方式取代了DARTS算法中權重求和的方式,實作了對不同操作的剪枝,而且作者認為溫度參數衰減的過程,就是網絡權重參數逐漸适應任務需求的過程,根據每個任務的訓練集不同,可以學習到不同的權重參數 α ^ o i , j \hat{\alpha}_o^{i,j} α^oi,j以滿足不同任務的需求,整個過程如下圖所示
最後對于每個結點的多個輸入進行剪枝,處理過程與上文采用的方式類似。令兩個節點之間的連接配接權重為 β i , j \beta^{i,j} βi,j,并引入退火溫度參數 τ β \tau_{\beta} τβ,然後按照下式進行計算
實作過程
網絡結構
通過NAS的方式進行學習
損失函數
式中 Φ k \Phi^k Φk表示第 k k k個任務學習器
訓練政策
與Reptile算法相結合的訓練過程如下圖所示
創新點
- 将NAS中的DARTS算法與小樣本學習中的Reptile算法相結合,通過元學習的方式同時訓練權重參數和結構參數
- 引入退火溫度參數,實作任務自适應的柔性剪枝方案
算法評價
真是一個萬物皆可AutoML的時代,連我認為與AutoML訴求最為沖突的小樣本學習問題都納入了NAS的研究版圖。因為對于普通的問題,采用NAS方法實際上是将搜尋空間擴大,不僅尋找最好的權重或者偏置參數,而且還要尋找最好的模型結構,而這一過程無疑加劇了對于資料集的依賴,必須有充足的樣本用于訓練,才能夠避免過拟合的問題,是其具備較好的泛化能力,而小樣本學習問題所缺少的恰恰就是訓練樣本。本文是利用元學習的方式,将網絡結構參數作為學習的對象,利用MAML或Reptile等方法進行訓練,并且設計了一種新的柔性剪枝方案,使其更好的适應小樣本學習任務。
如果大家對于深度學習與計算機視覺領域感興趣,希望獲得更多的知識分享與最新的論文解讀,歡迎關注我的個人公衆号“深視”。