文章目錄
- 一、本文說明
- 二. MultiHead Attention
- 2.1 MultiHead Attention理論講解
- 2.2. Pytorch實作MultiHead Attention
- 三. Masked Attention
- 3.1 為什麼要使用Mask掩碼
- 3.2 如何進行mask掩碼
- 3.3 為什麼是負無窮而不是0
一、本文說明
看本文前,需要先徹底搞懂Self-Attention。推薦看我的另一篇博文層層剖析,讓你徹底搞懂Self-Attention、MultiHead-Attention和Masked-Attention的機制和原理。本篇文章内容在上面這篇也有,可以一起看。
二. MultiHead Attention
2.1 MultiHead Attention理論講解
在Transformer中使用的是MultiHead Attention,其實這玩意和Self Attention差別并不是很大。先明确以下幾點,然後再開始講解:
- MultiHead的head不管有幾個,參數量都是一樣的。并不是head多,參數就多。
- 當MultiHead的head為1時,并不等價于Self Attetnion,MultiHead Attention和Self Attention是不一樣的東西
- MultiHead Attention使用的也是Self Attention的公式
- MultiHead除了三個矩陣外,還要多額外定義一個。
好了,知道上面幾點,我們就可以開始講解MultiHeadAttention了。
MultiHead Attention大部分邏輯和Self Attention是一緻的,是從求出Q,K,V後開始改變的,是以我們就從這裡開始講解。
現在我們求出了Q, K, V矩陣,對于Self-Attention,我們已經可以帶入公式了,用圖像表示則為:
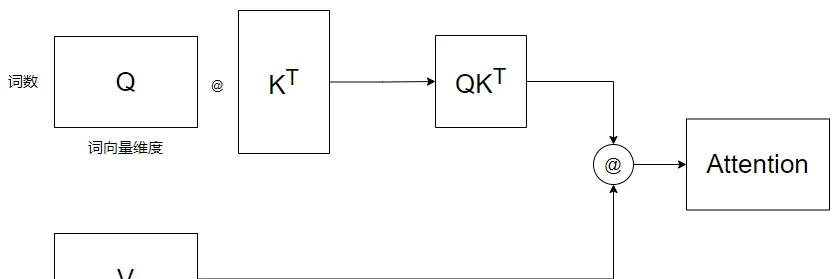
為了簡單起見,該圖忽略了Softmax和
而MultiHead Attention在帶入公式前做了一件事情,就是拆,它按照“詞向量次元”這個方向,将Q,K,V拆成了多個頭,如圖所示:

這裡我的head數為4。既然拆成了多個head,那麼之後的計算,也是各自的head進行計算,如圖所示:
但這樣拆開來計算的Attention使用Concat進行合并效果并不太好,是以最後需要再采用一個額外的矩陣,對Attention再進行一次線性變換,如圖所示:
到這裡也能看出來,head數并不是越多越好。而為什麼要用MultiHead Attention,Transformer給出的解釋為:Multi-head attention允許模型共同關注來自不同位置的不同表示子空間的資訊。反正就是用了比不用好。
2.2. Pytorch實作MultiHead Attention
該代碼參考項目annotated-transformer。
首先定義一個通用的Attention函數:
def attention(query, key, value):
"""
計算Attention的結果。
這裡其實傳入的是Q,K,V,而Q,K,V的計算是放在模型中的,請參考後續的MultiHeadedAttention類。
這裡的Q,K,V有兩種Shape,如果是Self-Attention,Shape為(batch, 詞數, d_model),
例如(1, 7, 128),即batch_size為1,一句7個單詞,每個單詞128維
但如果是Multi-Head Attention,則Shape為(batch, head數, 詞數,d_model/head數),
例如(1, 8, 7, 16),即Batch_size為1,8個head,一句7個單詞,128/8=16。
這樣其實也能看出來,所謂的MultiHead其實就是将128拆開了。
在Transformer中,由于使用的是MultiHead Attention,是以Q,K,V的Shape隻會是第二種。
"""
# 擷取d_model的值。之是以這樣可以擷取,是因為query和輸入的shape相同,
# 若為Self-Attention,則最後一維都是詞向量的次元,也就是d_model的值。
# 若為MultiHead Attention,則最後一維是 d_model / h,h為head數
d_k = query.size(-1)
# 執行QK^T / √d_k
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 執行公式中的Softmax
# 這裡的p_attn是一個方陣
# 若是Self Attention,則shape為(batch, 詞數, 次數),例如(1, 7, 7)
# 若是MultiHead Attention,則shape為(batch, head數, 詞數,詞數)
p_attn = scores.softmax(dim=-1)
# 最後再乘以 V。
# 對于Self Attention來說,結果Shape為(batch, 詞數, d_model),這也就是最終的結果了。
# 但對于MultiHead Attention來說,結果Shape為(batch, head數, 詞數,d_model/head數)
# 而這不是最終結果,後續還要将head合并,變為(batch, 詞數, d_model)。不過這是MultiHeadAttention
# 該做的事情。
return torch.matmul(p_attn, value)
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model):
"""
h: head的數量
"""
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
# 定義W^q, W^k, W^v和W^o矩陣。
# 如果你不知道為什麼用nn.Linear定義矩陣,可以參考該文章:
self.linears = [
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model),
nn.Linear(d_model, d_model),
]
def forward(self, x):
# 擷取Batch Size
nbatches = x.size(0)
"""
1. 求出Q, K, V,這裡是求MultiHead的Q,K,V,是以Shape為(batch, head數, 詞數,d_model/head數)
1.1 首先,通過定義的W^q,W^k,W^v求出SelfAttention的Q,K,V,此時Q,K,V的Shape為(batch, 詞數, d_model)
對應代碼為 `linear(x)`
1.2 分成多頭,即将Shape由(batch, 詞數, d_model)變為(batch, 詞數, head數,d_model/head數)。
對應代碼為 `view(nbatches, -1, self.h, self.d_k)`
1.3 最終交換“詞數”和“head數”這兩個次元,将head數放在前面,最終shape變為(batch, head數, 詞數,d_model/head數)。
對應代碼為 `transpose(1, 2)`
"""
query, key, value = [
linear(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for linear, x in zip(self.linears, (x, x, x))
]
"""
2. 求出Q,K,V後,通過attention函數計算出Attention結果,
這裡x的shape為(batch, head數, 詞數,d_model/head數)
self.attn的shape為(batch, head數, 詞數,詞數)
"""
x = attention(
query, key, value
)
"""
3. 将多個head再合并起來,即将x的shape由(batch, head數, 詞數,d_model/head數)
再變為 (batch, 詞數,d_model)
3.1 首先,交換“head數”和“詞數”,這兩個次元,結果為(batch, 詞數, head數, d_model/head數)
對應代碼為:`x.transpose(1, 2).contiguous()`
3.2 然後将“head數”和“d_model/head數”這兩個次元合并,結果為(batch, 詞數,d_model)
"""
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
# 最終通過W^o矩陣再執行一次線性變換,得到最終結果。
return self.linears[-1](x) 接下來嘗試使用一下:
# 定義8個head,詞向量次元為512
model = MultiHeadedAttention(8, 512)
# 傳入一個batch_size為2, 7個單詞,每個單詞為512次元
x = torch.rand(2, 7, 512)
# 輸出Attention後的結果
print(model(x).size()) 輸出為:
torch.Size([2, 7, 512]) 三. Masked Attention
3.1 為什麼要使用Mask掩碼
在Transformer中的Decoder中有一個Masked MultiHead Attention。本節來對其進行一個詳細的講解。
首先我們來複習一下Attention的公式:
其中:
假設 對應着 。那麼 就對應着 。 其中 包含着 到 的所有注意力資訊。而計算 時的 這些字的權重就是 的第一行的 。
如果上面的回憶起來了,那麼接下來看一下Transformer的用法,假設我們是要用Transformer翻譯“Machine learning is fun”這句話。
首先,我們會将“Machine learning is fun” 送給Encoder,輸出一個名叫Memory的Tensor,如圖所示:
之後我們會将該Memory作為Decoder的一個輸入,使用Decoder預測。Decoder并不是一下子就能把“機器學習真好玩”說出來,而是一個詞一個詞說(或一個字一個字,這取決于你的分詞方式),如圖所示:
緊接着,我們會再次調用Decoder,這次是傳入“<bos> 機”:
依次類推,直到最後輸出
<eos>
結束:
當Transformer輸出
<eos>
時,預測就結束了。
到這裡我們就會發現,對于Decoder來說是一個字一個字預測的,是以假設我們Decoder的輸入是“機器學習”時,“習”字隻能看到前面的“機器學”三個字,是以此時對于“習”字隻有“機器學習”四個字的注意力資訊。
但是,例如最後一步傳的是“<bos>機器學習真好玩”,還是不能讓“習”字看到後面“真好玩”三個字,是以要使用mask将其蓋住,這又是為什麼呢?原因是:如果讓“習”看到了後面的字,那麼“習”字的編碼就會發生變化。
我們不妨來分析一下:
一開始我們隻傳入了“機”(忽略bos),此時使用attention機制,将“機”字編碼為了
第二次,我們傳入了“機器”,此時使用attention機制,如果我們不将“器”字蓋住的話,那“機”字的編碼就會發生變化,它就不再是是了,也許就變成了。
這就會導緻第一次“機”字的編碼是,第二次卻變成了,這樣就可能會讓網絡有問題。是以我們為了不讓“機”字的編碼産生變化,是以我們要使用mask,掩蓋住“機”字後面的字,也就是即使他能attention後面的字,也不讓他attention。
許多文章的解釋是Mask是為了防止Transformer在訓練時洩露後面的它不應該看到的資訊,我認為這個解釋是不對的:①Transformer的Decoder并沒有區分訓練和測試,是以如果是為了防止訓練洩露後面資訊的話,那為什麼推理時也要掩碼呢? ② 傳給Decoder的内容都是Decoder自己推理出來的,它自己推理出來的不讓它看,說是為了防止洩露資訊,這不扯淡嘛。
當然,這也是我的個人看法,也許是我自己了解錯看了
3.2 如何進行mask掩碼
要進行掩碼,隻需要對scores動手就行了,也就是
第一次,我們隻有
第二次,我們有
此時如果我們不對 進行掩碼的話,的值就會發生變化(第一次是 ,第二次卻變成了)。那這樣看,我們隻需要将 蓋住即可,這樣就能保證兩次的
是以第二次實際就為:
依次類推,如果我們執行到第次時,就應該變成:
3.3 為什麼是負無窮而不是0
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)