本文是我的比對模型合集的其中一期,如果你想了解更多的比對模型,歡迎參閱我的另一篇博文比對模型合集
所有的模型均采用tensorflow進行了實作,歡迎start,[代碼位址]
https://github.com/terrifyzhao/text_matching
簡介
DIIN模型和其他比對模型的結構都很接近,也是采用CNN與LSTM來做特征提取,但是在其輸入層,作者提出了很多想法,同時采用了詞向量、字向量,并且添加了一些額外的特征例如詞性等,其本意在于能額外輸入一些句法特征,CNN部分也采用了DenseNet的結構,接下來就為大家詳細介紹該模型。
結構
DIIN的結構主要分為五層,分别是Embedding Layer、Encoding Layer、Interaction Layer、Feature Extraction Layer、Output Layer,主要結構如下圖所示
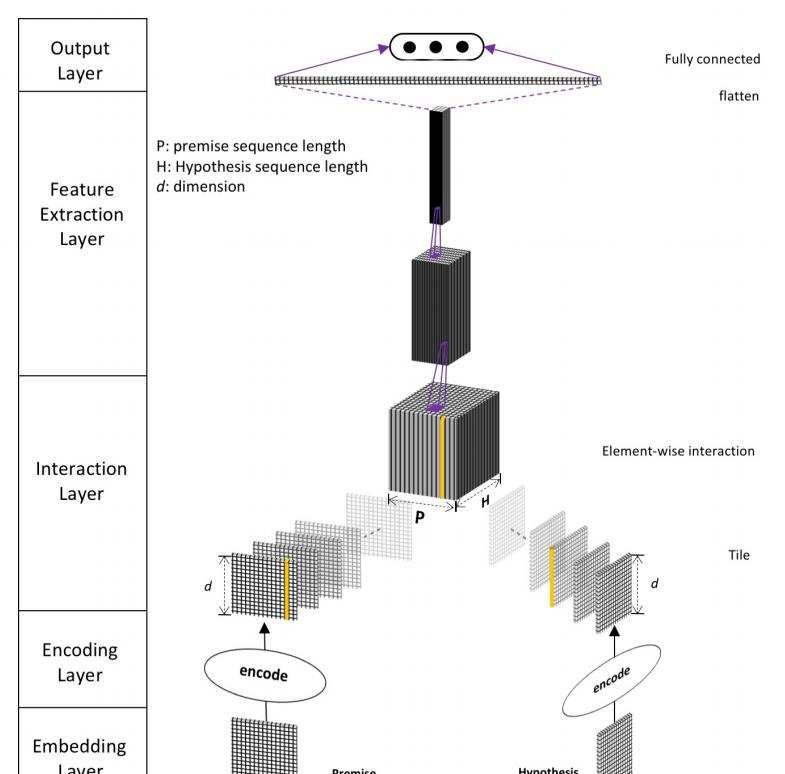
Embedding Layer
Embedding Layer會把每一個詞或者說段落轉變為向量表示,和其他模型不同的點在于其不僅僅隻采用了字、詞向量,還添加句法特征。其中詞向量是用預訓練好的模型得到的,并且在訓練的過程中繼續更新。而對于字向量則是先采用了1維卷積加最大池化層的方式來提取特征,其中卷積核對于P與H來說是共享的,字向量可以有效降低OOV引起的誤差。對于句法特征,包含了one-hot形式的詞性特征與exact match特征,exact match主要是針對英文,在去除時态、單複數等情況下兩個句子裡的詞是否一樣,在中文中這個特征我們就不考慮了,在我的代碼實作中主要以前三個特征為主。
Encoding Layer
Encoding Layer的主要作用是将上一層的特征進行融合并進行encode。論文中作者采用的是self-attention機制,同時考慮到了詞序和上下文資訊。以P作為例子,首先計算attetion matrix
A i j = α ( P ^ i ) , P ^ j ∈ R A_{ij} = \alpha (\hat P_i),\hat P_j \in R Aij=α(P^i),P^j∈R
這裡的attention matrix的 計算方法和transformer的還不太一樣,作者取了三個次元的值并拼接起來,如下面的公式所示,我的了解是a與b應該是一樣的,因為都是針對的P,唯一多了個 a ∘ b a\circ b a∘b其中的 ∘ \circ ∘是對位相乘,如果P的次元是 d d d,那麼拼接後的向量次元是 3 d 3d 3d
α ( a , b ) = w a T [ a ; b ; a ∘ b ] \alpha(a,b) = w_a^T[a;b;a\circ b] α(a,b)=waT[a;b;a∘b]
然後加上softmax計算self-attention的值
P ˉ = ∑ j = 1 p e x p ( A i j ) ∑ k = 1 p e x p ( A k j ) P ^ j \bar P = \sum_{j=1}^p\frac{exp(A_{ij})}{\sum_{k=1}^pexp(A_{kj})} \hat P_j Pˉ=j=1∑p∑k=1pexp(Akj)exp(Aij)P^j
接下來作為引入了LSTM中門的概念semantic composite fuse gate,其計算公式如下
z i = t a n h ( W 1 t [ P ^ i ; P ˉ i ] + b 1 ) r i = σ ( W 2 T [ P ^ i ; P ˉ i ] + b 2 ) f i = σ ( W 3 T [ P ^ i ; P ˉ i ] + b 3 ) P ~ i = r i ∘ P ^ i + f i ∘ z i z_i = tanh(W^{1t}[\hat P_i; \bar P_i]+b^1) \\ r_i = \sigma(W^{2T}[\hat P_i; \bar P_i]+b^2) \\ f_i = \sigma(W^{3T}[\hat P_i; \bar P_i]+b^3) \\ \tilde P_i = r_i \circ \hat P_i +f_i \circ z_i zi=tanh(W1t[P^i;Pˉi]+b1)ri=σ(W2T[P^i;Pˉi]+b2)fi=σ(W3T[P^i;Pˉi]+b3)P~i=ri∘P^i+fi∘zi
其中 W W W的次元均是 [ 2 d , d ] [2d,d] [2d,d], b b b的次元是 d d d, σ \sigma σ表示的是sigmoid函數
H的操作和P的操作一樣,就不再贅述了,有一點需要注意,論文中人為P和H是有細微差距的,是以attention的權重和gate的權重是沒有共享的,不過論文中的任務五是NLI,如果是相似度比對的任務我覺得此處是可以共享的,必須相似度比對兩個句子本身就是很接近的,此觀點僅代表個人想法沒有驗證過,代碼中我們還是以論文為主。
Interaction Layer
Interaction Layer的主要目的是把P與H做一個相似度的計算,提取出其中的相關性,可以采用餘弦相似度、歐氏距離等等,這裡作者發現對位相乘的想過很好,是以公式中的 β ( a , b ) = a ∘ b \beta(a,b) = a \circ b β(a,b)=a∘b
I i j = β ( P ~ i , H ~ i ) ∈ R d I_{ij} = \beta(\tilde P_i, \tilde H_i) \in R^d Iij=β(P~i,H~i)∈Rd
Feature Extraction Layer
Feature Extraction Layer的任務正如其名,做特征提取。這一層論文主要采用的是CNN的結構,作者實驗發現ResNet效果會好一些,但是最終還是選擇了DenseNet,因為DenseNet能更好的儲存參數,并且作者觀察到ResNet如果把skip connection移除了模型就沒法收斂了(ResNet的關鍵就在于skip connection不知道作者為什麼要說明這一點)BN還會導緻收斂變慢(這裡應該是指針對目前這個模型來說)是以作者并沒有采用ResNet。卷積采用的是relu激活函數,都是1×1的卷積核來對上文提到的相關性tensor進行縮放,并且這裡引入了一個超參數 η \eta η,例如輸入的channel是 k k k那麼輸出的channel就是 k × η k×\eta k×η,然後把結果送到3層Dense block中,Dense block包含了n個3×3的卷積核,成長率是 g g g,transition layer采用了1×1的卷積核來做channel的縮減,然後跟上一個步長為2的最大池化層,transition layer的縮減率用 θ \theta θ表示。這一層的關鍵就在于DenseNet,對DenseNet不清楚的小夥伴一定要先去了解該網絡的結構原理,這也是為啥作者會把該模型取名為Densely Interactive Inference Network
Output Layer
最後就是輸出層了,全連接配接層+softmax層,不再贅述。
小結
DIIN相比于之前介紹的比對模型,最大的改進點在于輸入的特征變多,其次特征提取時采用了DenseNet,但在Interaction層并沒有做多元度的比對,如果結合BiMPM的結構,把該部分從多個不同的粒度進行比對,效果應該還會進一步的提升,和其論文标題也會更加穩合一些。
參考文獻
NATURAL LANGUAGE INFERENCE OVER INTERACTION SPACE
![證券從業合格證書什麼時候列印?有哪些注意事項?[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)