文 | 鄒晨俊
前言
有贊資料平台從 2017 年上半年開始,逐漸使用 SparkSQL 替代 Hive 執行離線任務,目前 SparkSQL 每天的運作作業數量5000個,占離線作業數目的55%,消耗的 cpu 資源占叢集總資源的50%左右。本文介紹由 SparkSQL 替換 Hive 過程中碰到的問題以及處理經驗和優化建議,包括以下方面的内容:
- 有贊資料平台的整體架構。
- SparkSQL 在有贊的技術演進。
- 從 Hive 到 SparkSQL 的遷移之路。
一、有贊資料平台介紹
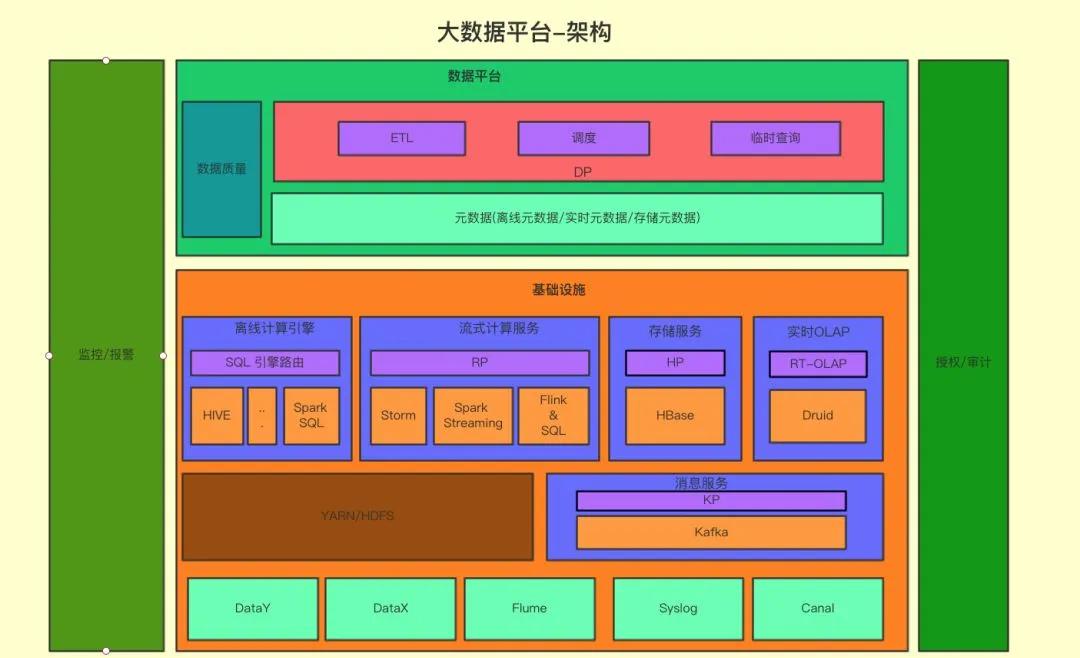
首先介紹一下有贊大資料平台總體架構:
如下圖所示,底層是資料導入部分,其中 DataY 差別于開源屆的全量導入導出工具 alibaba/DataX,是有贊内部研發的離線 Mysql 增量導入 Hive 的工具,把 Hive 中曆史資料和當天增量部分做合并。DataX / DataY 負責将 Mysql 中的資料同步到數倉當中,Flume 作為日志資料的主要通道,同時也是 Mysql binlog 同步到 HDFS 的管道,供 DataY 做增量合并使用。
第二層是大資料的計算架構,主要分成兩部分:分布式存儲計算和實時計算,實時架構目前主要支援 JStorm,Spark Streaming 和 Flink,其中 Flink 是今年開始支援的;而分布式存儲和計算架構這邊,底層是 Hadoop 和 Hbase,ETL主要使用 Hive 和 Spark,互動查詢則會使用 Spark,Presto,實時 OLAP 系統今年引入了 Druid,提供日志的聚合查詢能力。
第三層是資料平台部分,資料平台是直接面對資料開發者的,包括幾部分的功能,資料開發平台,包括日常使用的排程,資料傳輸,資料品質系統;資料查詢平台,包括ad-hoc查詢以及中繼資料查詢。有關有贊資料平台的詳細介紹可以參考往期有贊資料平台的部落格内容(https://tech.youzan.com/data_platform/)。
二、SparkSQL 技術演進
從 2017 年二季度,有贊資料組的同學們開始了 SparkSQL 方面的嘗試,主要的出發點是當時叢集資源是瓶頸,Hive 跑任務已經逐漸開始乏力,有些複雜的 SQL,通過 SQL 的邏輯優化達到極限,仍然需要幾個小時的時間。業務資料量正在不斷增大,這些任務會影響業務對外服務的承諾。同時,随着 Spark 以及其社群的不斷發展,Spark 及 Spark SQL 本身技術的不斷成熟,Spark 在技術架構和性能上都展示出 Hive 無法比拟的優勢。
從開始上線提供離線任務服務,再到 Hive 任務逐漸往 SparkSQL 遷移,踩過不少坑,也填了不少坑,這裡主要分兩個方面介紹,一方面是我們對 SparkSQL 可用性方面的改造以及優化,另一方面是 Hive 遷移時遇到的種種問題以及對策。
2.1 可用性改造
可用性問題包括兩方面,一個是系統的穩定性,監控/審計/權限等,另一個是使用者使用的體驗,使用者以前習慣用 Hive,如果 SparkSQL 的日志或者 Spark thrift server 的 UI 不能夠幫助使用者定位問題,解決問題,那也會影響使用者的使用或者遷移意願。是以我首先談一下使用者互動的問題。
2.1.1 使用者體驗
我們碰到的第一個問題是使用者向我們抱怨通過 JDBC 的方式和 Spark thrift server(STS) 互動,執行一個 SQL 時,沒有執行的進度資訊,需要一直等待執行成功,或者任務出錯時接收任務報錯郵件得知執行完。于是執行進度讓使用者可感覺是一個必要的功能。我們做了 Spark 的改造,增加運作時的 operation 日志,并且向社群送出了 patch(spark-22496), 而在我們内部,更增加了執行進度日志,每隔2秒列印出目前執行的 job/stage 的進度,如下圖所示。

2.1.2 監控
SparkSQL 需要收集 STS 上執行的 SQL 的審計資訊,包括送出者執行的具體 SQL,開始結束時間,執行完成狀态。原生 STS 會把這些資訊通過事件的方式 post 到事件總線,監聽者角色 (HiveThriftServer2Listener) 在事件總線上注冊,訂閱消費事件,但是這個監聽者隻負責 Spark UI 的 JDBC Tab 上的展示,我們改造了 SparkListener 類,将 session 以及執行的 sql statement 級别的消息也放到了總線上,監聽者可以在總線上注冊,以便消費這些審計資訊,并且增加了一些我們感興趣的次元,如使用的 cpu 資源,歸屬的工作流(airflowId)。同時,我們增加了一種新的完成狀态 cancelled,以友善區分是使用者主動取消的任務。
2.1.3 Thrift Server HA
相比于 HiveServer,STS 是比較脆弱的,一是由于 Spark 的 driver 是比較重的,所有的作業都會通過 driver 編譯 sql,排程 job/task 執行,分發 broadcast 變量,二是對于每個 SQL,相比于 HiveServer 會新起一個程序去處理這個 SQL 的執行,STS 隻有一個程序去處理,如果某個 SQL 有異常,查詢了過多的資料量, STS 有 OOM 退出的風險,那麼生産環境維持 STS 的穩定性就顯得無比重要。
除了必要的存活報警,首先我們區分了 ad-hoc 查詢和離線排程的 STS 服務,因為離線排程的任務往往計算結束時是把結果寫入 table 的,而 ad-hoc 大部分是直接把結果彙總在 driver,對 driver 的壓力比較大;此外,我們增加了基于 ZK 的高可用。對于一種類型的 STS(事實上,有贊的 STS 分為多組,如 ad-hoc,大記憶體配置組)在 ZK 上注冊一個節點,JDBC 的連接配接直接通路 ZK 擷取随機可用的 STS 位址。這樣,偶然的 OOM ,或者 bug 被觸發導緻 STS 不可用,也不會嚴重到影響排程任務完全不可用,給開發運維人員比較充足的時間定位問題。
2.1.4 權限控制
之後有另一個文章詳細介紹我們對于安全和權限的建設之路,這裡簡單介紹一下,Hive 的權限控制主要包括以下幾種:
- SQL Standards Based Hive Authorization
- Storage Based Authorization in the Metastore
- ServerAuthorization using Apache Ranger & Sentry
調研對比各種實作方案之後,由于我們是從無到有的增加了權限控制,沒有曆史負擔。我們直接選擇了ranger + 元件 plugin 的權限管理方案。
除了以上提到的幾個點,我們還從社群 backport 了數十個 patch 以解決影響可用性的問題,如不識别 hiveconf/hivevar (SPARK-13983),最後一行被截斷(HIVE-10541) 等等。
2.2 性能優化
之前談到,STS 隻有一個程序去處理所有送出 SQL 的編譯,所有的 SQL Job 共享一個 Hive 執行個體,更糟糕的是這個 Hive 執行個體還有處理 loadTable/loadPartition 這樣的 IO 操作,會阻塞其他任務的編譯,存在單點問題。我們之前測試一個上萬 partition 的 Hive 表在執行 loadTable 操作時,會阻塞其他任務送出,時間長達小時級别。對于 loadTable 這樣的IO操作,要麼不加鎖,要麼減少加鎖的時間。我們選擇的是後者,首先采用的是社群 SPARK-20187 的做法,将 loadTable 實作由 copyFile 的方式改為 moveFile,見下圖:
之後變更了配置 spark.sql.hive.metastore.jars=maven,運作時通過 Maven 的方式加載 jar 包,解決包依賴關系,使得加載的 Hive 類是2.1.1的版本,和我們 Hive 版本一緻,這樣得好處是很多行為都會和 Hive 的相一緻,友善排查問題;比如删除檔案到 Trash,之前 SparkSQL 删除表或者分區後是不會落到 Trash 的。
2.3 小檔案問題
我們在使用 SparkSQL 過程中,發現小檔案的問題比較嚴重,SparkSQL 在寫資料時會産生很多小檔案,會對 namenode 産生很大的壓力,進而帶來整個系統穩定性的隐患,最近三個月檔案個數幾乎翻了個倍。對于小檔案問題,我們采用了社群 SPARK-24940 的方式處理,借助 SQL hint 的方式合并小檔案。同時,我們有一個專門做 merge 的任務,定時異步的對天級别的分區掃描并做小檔案合并。
還有一點是spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=2, MapReduce-4815 詳細介紹了 fileoutputcommitter 的原理,實踐中設定了 version=2 的比預設 version=1 的減少了70%以上的 commit 時間。
三、SparkSQL 遷移之路
解決了大部分的可用性問題以後,我們逐漸開始了 SparkSQL 的推廣,引導使用者選擇 SparkSQL 引擎,絕大部分的任務的性能能得到較大的提升。于是我們進一步開始将原來 Hive 執行的任務向 SparkSQL 轉移。
在 SparkSQL 遷移之初,我們選擇的路線是遵循二八法則,從優化耗費資源最多的頭部任務開始,把Top100的任務從 Hive 往 SparkSQL 遷移,逐漸積累典型錯誤,包括 SparkSQL 和Hive的不一緻行為,比較典型的問題由ORC格式檔案為空,Spark會抛空指針異常而失敗,ORC 格式和 metastore 類型不一緻,SparkSQL 也會報錯失敗。經過一波人工推廣之後,頭部任務節省的資源相當客觀,在2017年底,切換到 SparkSQL 的任務數占比5%,占的資源20%,資源使用僅占 Hive 運作的10%-30%。
在 case by case 處理了一段時間以後,我們發現這種方式不太能夠擴充了。首先和作業的 owner 協商修改需要溝通成本,而且小作業的改動收益不是那麼大,作業的 owner 做這樣的改動對他來說收益比較小,反而有一定機率的風險。是以到這個階段 SparkSQL 的遷移之路進展比較緩慢。
于是我們開始構思自動化遷移方式,構思了一種執行引擎之上的智能執行引擎選擇服務 SQL Engine Proposer(proposer),可以根據查詢的特征以及目前叢集中的隊列狀态為 SQL 查詢選擇合适的執行引擎。資料平台向某個執行引擎送出查詢之前,會先通路智能執行引擎選擇服務。在標明合适的執行引擎之後,資料平台将任務送出到對應的引擎,包括 Hive,SparkSQL,以及較大記憶體配置的 SparkSQL。
并且在 SQL Engine Proposer,我們添加了一系列政策:
- 規則政策,這些規則可以是某一種 SQL pattern,proposer 使用 Antlr4 來處理執行引擎的文法,對于某些遷移有問題的問題,将這種 pattern 識别出來,添加到規則集合中,典型的規則有沒有發生 shuffle 的任務,或者隻發生 broadcast join 的任務,這些任務有可能會産生很多小檔案,并且邏輯一般比較簡單,使用Hive運作資源消耗不會太多。
- 白名單政策,有些任務希望就是用Hive執行,就通過白名單過濾。當 Hive 和 SparkSQL 行為不一緻的時候,也可以先加入這個集合中,保持執行和問題定位能夠同時進行。
- 優先級政策,在灰階遷移的時候,是從低優先級任務開始的,在 proposer 中我們配置了灰階的政策,從低優先級任務切一定的流量開始遷移,逐漸放開,在優先級内達到全量,目前放開了除 P1P2 以外的3級任務。
- 過往執行記錄,proposer 選擇時會根據曆史執行成功情況以及執行時間,如果 SparkSQL 效率比 Hive 有顯著提升,并且在過去一直執行成功,那麼 proposer 會更傾向于選擇 SparkSQL。
截止目前,執行引擎選擇的作業數中 SparkSQL 占比達到了73%,使用資源僅占32%,遷移到 SparkSQL 運作的作業帶來了67%資源的節省。
四、未來展望
我們計劃 Hadoop 叢集資源進一步向 SparkSQL 方向轉移,達到80%,作業數達70%,把最高優先級也開放到選擇引擎,引入 Intel 開源的 Adaptive Execution(https://github.com/Intel-bigdata/spark-adaptive) 功能,優化執行過程中的 shuffle 數目,執行過程中基于代價的 broadcast join 優化,替換 sort merge join,同時更徹底解決小檔案問題。