作者丨CY
1. 文章資訊
本次介紹的文章是2021年3月份發表在IEEE Transactions on Instrumentation and Measurement的關于自動駕駛場景下的目标檢測文章,文章題目為《YOLOv4-5D: An Effective and Efficient Object Detector for Autonomous Driving》
2. 摘要
自動駕駛汽車中,使用目标檢測算法變得極為重要。高精度的目标檢測和快速的推理速度是保證自動駕駛安全的關鍵。是以,必須考慮目标檢測器的有效性和效率之間的平衡。文章提出了一種one-stage的目标檢測架構,以提高檢測精度,同時支援基于YOLOv4的真實實時操作。該架構中的骨幹網是CSPDarknet53_dcn(P)。用變形卷積代替CSPDarknet53的最後一個輸出層,以提高檢測精度。為了進行特征融合,設計了一種新的特征融合子產品pan++,并采用5個尺度檢測層來提高小目标的檢測精度。此外,文章還提出了一種優化的網絡剪枝算法,以解決車載計算平台計算資源有限,無法滿足算法實時性的問題。利用稀疏尺度因子的方法對現有的通道剪枝算法進行了改進。與YOLOv4相比,YOLOv4 - 5d在BDD資料集上平均精度提高了4.23%,在KITTI資料集上平均精度提高了1.68%。最後,通過對模型進行裁剪,在檢測精度基本不變的情況下,yolov - 5d的推理速度提高了31.3%,記憶體僅為98.1 MB。然而,該算法能夠以超過66幀/s (fps)的速度進行實時檢測,并且在相同的幀數下比之前的算法具有更高的準确率。
3. 簡介
近年來,深度學習已被廣泛應用于各個領域,包括計算機視覺和自動駕駛。傳感器和GPU計算單元的快速發展顯著加快了深度學習算法的疊代速度。
自動駕駛汽車的主要功能是實時準确識别車輛周圍的物體,以確定安全、正确的控制決策。一般來說,自動駕駛汽車使用各種傳感器,如攝像頭、雷射雷達等,用于檢測車輛、行人、交通燈、交通标志等物體。與其他傳感器相比,現在的錄影機在探測物體方面更加精确,成本效益也更高。
基于深度學習的目标檢測和語義分割算法在自動駕駛領域中已經變得非常重要。基于深度學習的算法可以在使用較少計算資源的前提下實作較高的檢測精度,是以成為自動駕駛系統中必不可少的方法。針對自動駕駛汽車的目标檢測算法需要滿足以下兩個條件。一是對道路目标的檢測精度高。其次,實時檢測速度對于車輛控制器的快速響應和減少延遲至關重要。基于CNN的目标檢測算法可以分為兩類。第一類是基于生成region proposal的兩階段檢測算法,如Faster R-CNN和cascade R-CNN。兩階段探測器對目标的檢測精度較高,但檢測速度較慢。第二類是一階段探測器,如SSD和YOLO,可以同時進行物體分類和邊界盒回歸,不需要生成region proposal,直接生成類對象的位置坐标。是以,一階段探測器的檢測速度能夠滿足實時性要求,但檢測精度低于兩級檢測器。
以往的方法不能滿足608 × 608及以上分辨率作為輸入時對實時檢測速度的要求,而608 × 608及以上分辨率作為輸入是為了達到較高的精度不可或缺的。自動駕駛計算平台的計算資源有限,需要同時處理檢測、跟蹤、決策等多種傳感和計算任務。是以,檢測算法需要具有較小的記憶體占用率和計算資源占用率。自動駕駛應用的一個先決條件是使用超過30幀/秒。這表明,平衡檢測精度和速度仍然是一個主要問題。此外,大多數傳統的目标檢測算法最關鍵的問題之一是大小目标的檢測精度不能很好地平衡。通常,大的物體容易被檢測到,而小的物體往往被檢測器忽略。在自動駕駛的情況下,忽略小物體(交通燈、行人等)的檢測是非常危險的,因為它會引起過度的反應,如意外刹車,進而降低駕駛的穩定性和效率,導緻緻命的事故。YOLOv4-5D中的特征融合子產品是PAN++,它是在原PAN的基礎上改進的,更适合于小目标的檢測。然而,在上述算法中,YOLOv4并沒有針對自動駕駛資料集進行優化。YOLOv4可以用一個推理來檢測多個對象,呈現出非常快的檢測速度。然而與兩階段方法相比,YOLOv4對小目标的準确度普遍較低。是以,在保持實時目标檢測能力的同時,提高精度至關重要。為此,本文提出通過變形卷積的backbone模組化和對YOLOv4檢測子產品的重新設計提高檢測精度。同時,提出了一種優化的通道剪枝方法,可在車載計算平台上實時運作。
4. 相關工作
YOLOv4是對YOLO系列算法的進一步改進。YOLOv4的網絡架構如下圖所示。
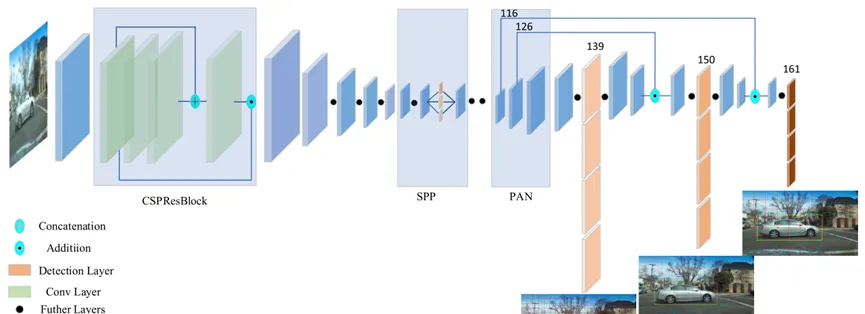
YOLOv4采用CSPDarknet53結構作為骨幹,解決了推送過程中檢測算法需要大量計算的問題。最突出的特性是以類似的方式在三個不同的尺度上進行檢測,使得YOLOv4可以檢測各種大小的對象。由于YOLOv4是一個全卷積網絡,僅由YOLOv3那樣的1 × 1和3 × 3的小型卷積濾波器組成,是以檢測速度與YOLO和YOLOv2相等。YOLOv4的檢測速度可以滿足自動駕駛系統的實時性要求。然而,YOLOv4的精度,特别是對于小目标,仍然低于兩階段探測器。算法記憶體和計算資源占用較大,無法滿足自動駕駛汽車對感覺算法記憶體比例小、計算資源少的需求。
在真實的道路交通環境中,道路場景目标檢測具有大量不同大小的小目标。一個典型的真實道路檢測場景如下圖所示。

由于攝影測量中的透視畸變的存在,使得遠處的物體變得更小,而探測小的物體是一個已知的難點問題。從上圖中可以看出,場前的物體與右上方的交通标志大小相差約90倍。并且bbox大小的明顯差異不僅發生在不同類型的對象之間,而且也發生在相同類的對象之間。在上圖中,當車輛位于遠視圖時,交叉口對面的灰色車輛,與場景前方車輛的bbox區域存在顯著差異。BDD資料集中對象檢測bbox的大小分布如從下圖所示。可以清楚地看到,大多數分布是由小物體組成的。
上圖揭示了研究自動駕駛場景下小目标高精度檢測算法的意義。現有的檢測網絡由于道路檢測場景中近遠目标的bbox區域差異較大,無法滿足對行車交通目标檢測精度的要求。是以,需要一種道路檢測模型,可以較好的處理大的和小的對象。
5. 方法
基于anchor的一階段檢測器通常由backbone、neck和用于物體分類和定位的head組成。文章對YOLOv4的詳細結構進行了修改,并提出了一個用CSPDarknet53_dcn取代backbone的修改版本。這個修改後的版本在文章中被用作baseline。文章還對YOLOv4的特征融合子產品進行了重新設計,設計了5種尺度的檢測子產品。改進後的檢測算法被稱為YOLOV4-5D,一種自動駕駛道路場景的多尺度實時檢測算法。
A. Backbone
在YOLOv4中,首先使用CSPDarkNet-53提取不同尺度的feature map。CSPDarknet53可以解決大部分檢測場景的特征提取任務。為了提高backbone在複雜流量環境下的特征提取能力,利用DCN (deformableconvolutional network)對骨幹網進行優化。如下圖所示,DCN使用一個可學習的偏移量來描述目标的特征方向,使得網絡的接受域不局限于固定的範圍,更能靈活地适應目标幾何形狀的變化。DCN有利于對複雜場景進行充分的檢測。
雖然DCN本身并沒有顯著增加模型中的參數數量和FLOPs,但DCN的有效性在許多檢測模型中得到了驗證。在實際應用中,多個DCN層增加了推理時間。是以,為了平衡效率和有效性,文章隻在最後階段用DCN替換3 × 3卷積層。這個修改後的主幹被标記為CSPDarkNet53_dcn,DCN層在下圖YOLOv4-5D架構圖中用一個黑色三角形标記。
B. Detection Neck
在YOLOv4中用SPP和PAN來增加網絡的感受野,并建立一個特征圖之間橫向連接配接的特征金字塔。為了提高小目标的檢測精度,設計了pan++作為特征融合子產品。對于pan++,針對兩個點實作了兩個特征融合子產品。其中一個子產品充分利用了主幹網的低層實體資訊和高層語義資訊;第二個子產品用于适應新檢測層引起的所需特征圖的比例變化。在YOLOv4中,最大檢測規模為79 × 79。在79 × 79的小尺度下,檢測算法都不利于對小目标進行最終的位置資訊回歸。是以,文章提出的YOLOV4-5D中使用的最大比例尺特征圖變為304 × 304,為小目标檢測提供了重要的特征。如上面YOLOV4-5D的架構圖,YOLOV4-5D網絡結構輸出五尺度檢測圖像,經過pan++。YOLOv4-5d與YOLOv4相比增加了152 × 152和304 × 304兩個大型小目标探測器。
C. Detection Head
YOLOV4-5D的檢測頭非常簡單。它由一個3 × 3卷積層和一個1 × 1卷積層組成,通過卷積層得到最終的預測結果。每個最終預測的輸出通道為3(K + 5),其中K為類數。最終預測的每個位置都與三個不同的anchor相關聯。在YOLOv4的三尺度檢測頭的基礎上,根據上述相關設計增加了兩大尺度檢測層進行特征增強,即頸部檢測。這兩個大規模的檢測層都用于小目标的檢測。改進後的網絡平衡了遠距離小目标和大型目标的檢測性能。
D. 網絡剪枝
深度CNN所依賴的計算量和存儲量嚴重限制了其在資源有限的平台上的部署。基于各種政策的剪枝算法可以降低網絡權值的數量、計算複雜度和網絡備援度。然而,不同的資料結構和網絡結構對不同的剪枝方法有不同的性能影響,這增加了剪枝方法選擇的難度。特别是當某個卷積層中有太多的卷積核時(這通常意味着更多的備援),網絡訓練會使卷積層形成特殊的空間幾何結構,參數重要度評估方法将無法區分卷積核的重要度。Yolov4中卷積核的數目有很大的不同。最小的修剪層有32個卷積核,大部分有1024個卷積核。文章采用稀疏尺度因子的方法,避免了在備援度較大的卷積層中,參數重要性評估方法無法有效區分卷積核的重要性的問題。
6. 實驗及分析
實驗使用KITTI和BDD資料集。KITTI資料集是自動駕駛研究中常用的資料集,BDD資料集是最新釋出的自動駕駛資料集。KITTI資料集由7481張用于訓練的圖像和7518張用于測試的圖像組成,其中包括汽車、自行車和行人三類。BDD資料集包括10個類,包括公共汽車、燈光、辨別、人、自行車、卡車、機車、汽車、火車和騎手。建構多目标道路檢測模型的目的是為了準确地檢測出自然駕駛場景中的常見目标。是以,從100k圖像中選取80k的标簽圖像,去掉火車的标注,将标簽騎手、機車和自行車合并到标簽騎手中。最後的訓練集标簽有七個類别:汽車、公共汽車、卡車、人、交通燈、交通标志和騎手。以70k圖像作為訓練集,10k作為驗證集。實驗在NVIDIA GTX 2080Ti上進行,環境為CUDA 10.0和cuDNN v10.0。
下表比較了YOLOv4和建議的YOLOv4 - 5d的性能。
下表比較了本文算法與其他方法對BDD測試集的性能。從表中可以看出,提出的YOLOv4 - 5d的 mAP提高了4.23%,可以實作實時檢測,與52.3幀/s的YOLOv4相比速度略有差異。
最後采用基于通道的剪枝算法對YOLOV4-5D骨幹網進行剪枝,并對簡化模型進行微調,恢複模型的準确性。最終實驗資料如下表所示。
最後是檢測結果的可視化,基線的檢測結果和提出的算法在KITTI測試集上的表現如下圖所示。
7. 結論
目标檢測算法具有較高的檢測精度和實時檢測速度,對自動駕駛汽車的安全性和實時控制至關重要。然而,目前的研究還沒有解決平衡檢測精度和檢測速度的問題。同時,普遍欠缺對小目标的檢測能力。為了解決這些問題,文章提出了一種目标檢測算法,該算法在自動駕駛的精度和速度之間達到了最佳的權衡。利用可變形卷積對骨幹網絡進行優化,提高了骨幹網絡對幾何變對象的特征提取能力。将檢測頸設計為PAN++,并引入附加層,融合語義資訊和位置資訊。擴大了網絡檢測頭的最大檢測規模。在原有的三個較小的檢測尺度的基礎上,增加了兩個大規模的檢測頭用于小目标的檢測。文章是在YOLOv4中第一次嘗試用可變形的卷積來模組化主幹,并重新設計檢測子產品。是以,文章提出的YOLOV4-5D提高了自動駕駛中對小目标的檢測。此外,文章還提出了一種優化的網絡剪枝算法,以解決由于車載計算平台的計算資源有限,無法滿足算法實時性的問題。利用稀疏尺度因子的方法對現有的通道剪枝算法進行了改進。與YOLOv4相比,YOLOv4 - 5d在BDD資料集上的平均AP提高了4.23%,在KITTI資料集上的平均AP提高了1.68%。最後,通過對模型進行裁剪,在幾乎不影響檢測精度的情況下,yolov - 5d的推理速度提高了31.3%,記憶體僅為98.1 MB。然而,該算法能夠以超過66幀/s的速度進行實時檢測度。是以,文章提出的算法最适合于自動駕駛應用。該算法對交通标志、交通燈、車輛、人的檢測精度分别提高了5.31%、2.2%、2.13%、1.9%,證明了yolov - 5d在BDD資料集上比KITTI資料集具有更好的小目标檢測精度。在不影響大目标檢測精度的前提下,在支援實時操作的前提下,大大提高了交通标志、交通燈等小目标的檢測精度。所得到的結果和對比分析驗證了該算法在精度和檢測速度上的權衡,适用于自動駕駛。
本文僅做學術分享,如有侵權,請聯系删文。