在深度學習中,樣本不均衡是指不同類别的資料量差别較大,利用不均衡樣本訓練出來的模型泛化能力差并且容易發生過拟合。
對不平衡樣本的處理手段主要分為兩大類:資料層面 (簡單粗暴)、算法層面 (複雜) 。
資料層面
采樣(Sample)
資料重采樣:上采樣或者下采樣
| 上采樣 | 下采樣 | |
|---|---|---|
| 使用情況 | 資料不足時 | 資料充足 (支撐得起你的浪費) |
| 資料集變化 | 增加 | 間接減少(量大類被截流了) |
| 具體手段 | 大量複制量少類樣本 | 批處理訓練時,控制從量大類取的圖像數量 |
| 風險 | 過拟合 |
資料合成
資料合成方法是利用已有樣本生成更多的樣本。其中最常見的一種方法叫做SMOTE,它利用小衆樣本在特征空間的相似性來生成新樣本。對于小衆樣本xi∈Smin,從它屬于小種類的K近鄰中随機選取一個樣本,生成一個新的小衆樣本xnew:
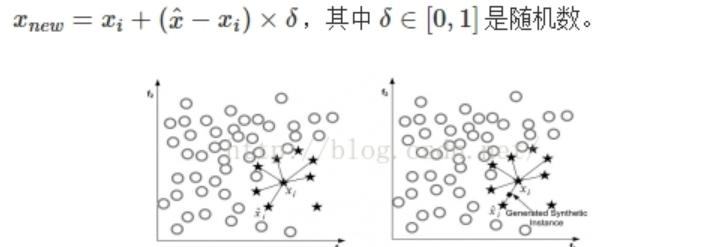
上圖是SMOTE方法在K=6近鄰下的示意圖,黑色圓點是生成的新樣本。
算法層面
在目标函數中,增加量少類樣本被錯分的損失值 。
準确度這個評價名額在類别不均衡的分類任務中并不能work.
代價敏感學習算法(Cost-Sensitive Learning)
不同類型的五分類情況導緻的代價是不一樣的。是以定義代價矩陣,Cij表示将類别j誤分類為i的代價,顯然C00=C11=0.C01和C10為兩種不同的誤分類代價,當兩者相等時為代價不敏感的學習問題。

代價敏感學習方法主要有以下的實作方式:
(1)從學習模型出發,着眼于對某一具體學習方法的改造,使之能适應不平衡資料下的學習,研究者們針對不同的學習模型如感覺機,支援向量機,決策樹,神經網絡等分别提出了其代價敏感的版本。以代價敏感的決策樹為例,可從三個方面對其進行改進以适應不平衡資料的學習,這三個方面分别是決策門檻值的選擇方面、分裂标準的選擇方面、剪枝方面,這三個方面中都可以将代價矩陣引入。
(2)從貝葉斯風險理論出發,把代價敏感學習看成是分類結果的一種後處理,按照傳統方法學習到一個模型,以實作損失最小為目标對結果進行調整,優化公式如下所示。此方法的優點在于它可以不依賴所用具體的分類器,但是缺點也很明顯它要求分類器輸出值為機率。
(3)從預處理的角度出發,将代價用于權重的調整,使得分類器滿足代價敏感的特性。
參考:
[1] http://blog.csdn.net/jningwei/article/details/79249195
[2] https://www.jianshu.com/p/3e8b9f2764c8
[3] http://blog.csdn.net/lujiandong1/article/details/52658675