可解釋的卷積濾波器 SincNet
Ravanelli, M. 在 NIPS 2018 進一步讨論了 SincNet 可解釋意義,令人感覺該模型已經能夠勝任在說話人識别的基礎上勝任更多的語音處理任務。是以,在先前的 SincNet 講解基礎上,筆者進一步分析 SincNet 的可解釋性、相關的無監督方法和潛在的安全威脅。
Notes from Speaker Recognition from Raw Waveform with SincNet:
In particular, we propose SincNet, a novel Convolutional Neural Network (CNN) that encourages the first layer to discover more meaningful filters by exploiting parametrized sinc functions.
This inductive bias offers a very compact way to derive a customized filter-bank front-end, that only depends on some parameters with a clear physical meaning.
The proposed architecture converges faster, performs better, and is more interpretable than standard CNNs.
文章目錄
- 可解釋的卷積濾波器 SincNet
-
- 摘要
- SincNet 設計
- SincNet 可解釋性
-
- 頻域上的實體意義
- 噪聲場景的解釋
- 基于 SincNet 無監督學習
- SincNet 對抗樣本
- 參考文獻
摘要
2018 年以後,SincNet 具有更快的收斂速度、更佳的表示能力和更好的可解釋性,但也暴露出其對抗攻擊的脆弱性。筆者詳細分析 SincNet 四部分:設計原理、可解釋性、無監督學習應用和對抗攻擊。考慮到 SincNet 在頻域方面的實體意義,它将為語音處理應用的研發提供極大的便利,例如說話人識别與語音識别。
SincNet 設計
在先前的 SincNet 講解基礎上,該部分着重分析參數化濾波器的設計,及其相關實體含義。值得重視的是:信号處理技術中的帶通濾波器是啟發 SincNet 設計的主要來源,是以,筆者從帶通濾波器的角度來描述參數化濾波器的設計原理。
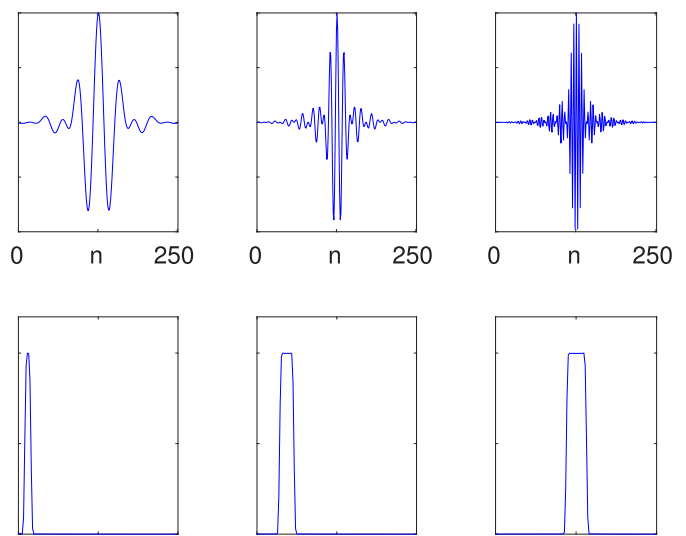
為了更好的了解參數化濾波器的設計原理,可以通過傳統卷積函數中的一維卷積來看待該濾波器,例如 PyTorch 的
nn.Conv1d
。在此基礎上,可以任務該濾波器就是一個長度為 L L L 的一維向量,這些向量的權重,可以通過參數更新的方法學習獲得。
根據上圖給出第一行圖檔,可以了解為三個不同的一維卷積 c = { c i } i = 0 250 \mathbb{c}=\{c_i\}_{i=0}^{250} c={ci}i=0250,它們的長度都為 L = 251 L=251 L=251。通過這樣的數學符号,可以将其與二維卷積直接聯系起來。簡單來說,SincNet 帶通濾波器就是一種特定的一維卷積。
那麼如何設計這樣一個特定的一維卷積函數呢?**直覺地,讓濾波器去學習特定頻域範圍内的資訊。**為設計這樣的濾波器,需要了解一下内容:
- 為什麼希望 SincNet 參數化濾波器來學習特定頻率範圍的内容?
- 問題:音調和基頻是幫助識别說話人身份的重要線索,也是非常重要且具有實體含義的聲學特性。Mel-Scale 濾波器組提供了提取這類資訊類似的功能。然而,傳統的頻譜提取方法,例如 MFCC、PLP、FBANK 等,是依據以往經驗提取的信号資訊,無法直接證明這些資訊的所有組成成分都是有利于特定語音處理任務的。
- SincNet 參數化濾波器:為了适應特定的語音處理任務,設計可學習的濾波器,來替換人工提取的濾波器組或者頻譜相關系數。是以,該學習濾波器滿足一下設計要求:
- 處理原始信号:在深度學習架構中,它位于與原始波形直接關聯的位置,即網絡第一層,替代 MFCC、FBANK 或者 PLP 的功能。
- 提取頻率相關的資訊:頻譜分析提供了非常重要的資訊,例如音調和基頻,或者特定頻帶的資訊。
- 要具有實體含義:“數字信号處理”從實體的角度提供了大量的數字信号濾波器設計相關的知識,例如高通濾波器、低通濾波器、帶通濾波器等。
- 為什麼帶通濾波器可以學習特定頻率範圍内的内容?
- 帶通濾波器:在“數字信号處理”領域,帶通濾波器的屬性是讓特定頻帶(連續頻率範圍)的數字信号通過。上圖的第二行描述了三種帶通濾波器的頻域特性——通帶。它往往可以用于噪聲過濾,例如高頻噪聲過濾。
- 數字信号:在“數字信号處理”領域,有一個關于傅裡葉的觀點:**任何周期函數,都可以看作是不同振幅,不同相位正弦波的疊加。**就像在“高等數學”的範疇下,把一個周期函數展開成傅裡葉級數。
根據經驗,把說話人的語音看作一個周期信号是可行的,
或者說,忽略語音信号的非周期成分不會顯著影響語音處理效果。
- 通過與衰減:根據傅裡葉理論,帶通濾波器将通帶以外的頻率都衰減掉了,而留下的通帶内的頻率。
- 如何設計這樣的濾波器?
-
c = { c i } i = 0 250 \mathbb{c}=\{c_i\}_{i=0}^{250} c={ci}i=0250:為了使一維卷積滿足帶通濾波器的特性,需要建構與兩個截至頻(低、高)相關的參數化模型。這裡已知濾波器頻域特性,可以通過逆向傅裡葉變換來獲得濾波器 g ( n , f 1 , f 2 ) g(n,f_1,f_2) g(n,f1,f2) 在頻域上的參數 ( f 1 f_1 f1 與 f 2 f_2 f2),相應的數學公式為:
g ( n , f 1 , f 2 ) = 2 f 2 sinc ( 2 π f 2 n ) − 2 f 1 sinc ( 2 π f 1 n ) g(n,f_1,f_2)=2f_2\text{sinc}(2\pi f_2 n)-2f_1\text{sinc}(2\pi f_1 n) g(n,f1,f2)=2f2sinc(2πf2n)−2f1sinc(2πf1n)
其中 n n n 表示濾波器長度 L L L,上圖中, n = L = 251 n=L=251 n=L=251。
- 窗函數 (window):帶通濾波器的矩形窗特性無法通過有限的傅裡葉成分精準的描述,且這樣的矩形窗特性存在突變不連續性。為此,“數字信号處理”領域采用 window 來克服。
-
根據上述原理,帶通濾波器的一維卷積提供了一種提取信号特定頻率範圍資訊的功能,它的截至頻的可學習的特性,使得該一維卷積可以通過資料來自适應地學到帶通濾波器的通帶。本質上,SincNet 的參數化濾波器是借鑒了帶通濾波器的設計,并使其可學習化。
SincNet 中第一層濾波器,即參數話帶通濾波器,其精簡後的代碼(完整代碼參考連結)如下。特别地,SincNet 的輸入語音通常采用 200 ms 長與 10 ms 間隔的采樣方式。
class SincConv_fast(nn.Module):
@staticmethod
def to_mel(hz):
return 2595 * np.log10(1 + hz / 700)
@staticmethod
def to_hz(mel):
return 700 * (10 ** (mel / 2595) - 1)
def __init__(self, out_channels, kernel_size, sample_rate=16000, in_channels=1,
stride=1, padding=0, dilation=1, bias=False, groups=1, min_low_hz=50, min_band_hz=50):
super(SincConv_fast,self).__init__()
self.out_channels = out_channels
self.kernel_size = kernel_size
# Forcing the filters to be odd (i.e, perfectly symmetrics)
if kernel_size%2==0:
self.kernel_size=self.kernel_size+1
self.stride = stride
self.padding = padding
self.dilation = dilation
self.sample_rate = sample_rate
self.min_low_hz = min_low_hz
self.min_band_hz = min_band_hz
# initialize filterbanks such that they are equally spaced in Mel scale
low_hz = 30
high_hz = self.sample_rate / 2 - (self.min_low_hz + self.min_band_hz)
mel = np.linspace(self.to_mel(low_hz),
self.to_mel(high_hz),
self.out_channels + 1)
hz = self.to_hz(mel)
# filter lower frequency (out_channels, 1)
self.low_hz_ = nn.Parameter(torch.Tensor(hz[:-1]).view(-1, 1))
# filter frequency band (out_channels, 1)
self.band_hz_ = nn.Parameter(torch.Tensor(np.diff(hz)).view(-1, 1))
# Hamming window
# computing only half of the window
n_lin=torch.linspace(0, (self.kernel_size/2)-1, steps=int((self.kernel_size/2)))
self.window_=0.54-0.46*torch.cos(2*math.pi*n_lin/self.kernel_size);
# (1, kernel_size/2)
n = (self.kernel_size - 1) / 2.0
# Due to symmetry, I only need half of the time axes
self.n_ = 2*math.pi*torch.arange(-n, 0).view(1, -1) / self.sample_rate
def forward(self, waveforms):
self.n_ = self.n_.to(waveforms.device)
self.window_ = self.window_.to(waveforms.device)
low = self.min_low_hz + torch.abs(self.low_hz_)
high = torch.clamp(low + self.min_band_hz + torch.abs(self.band_hz_),self.min_low_hz,self.sample_rate/2)
band=(high-low)[:,0]
f_times_t_low = torch.matmul(low, self.n_)
f_times_t_high = torch.matmul(high, self.n_)
# Equivalent of Eq.4 of the reference paper (SPEAKER RECOGNITION FROM RAW WAVEFORM WITH SINCNET).
# I just have expanded the sinc and simplified the terms. This way I avoid several useless computations.
band_pass_left=((torch.sin(f_times_t_high)-torch.sin(f_times_t_low))/(self.n_/2))*self.window_
band_pass_center = 2*band.view(-1,1)
band_pass_right= torch.flip(band_pass_left,dims=[1])
band_pass=torch.cat([band_pass_left,band_pass_center,band_pass_right],dim=1)
band_pass = band_pass / (2*band[:,None])
self.filters = (band_pass).view(
self.out_channels, 1, self.kernel_size)
return F.conv1d(waveforms, self.filters, stride=self.stride,
padding=self.padding, dilation=self.dilation,
bias=None, groups=1)
SincNet 可解釋性
帶通濾波器源自數字信号處理,這使得 SincNet 第一層濾波器具有很好的可解釋性,在頻率上的可解釋意義。
頻域上的實體意義
- SincNet 第一層濾波器,即參數化、可學習的帶通濾波器,複制了帶通濾波器的特性與功能,是以,它的實體意義可以與帶通濾波器相當——一維卷積的截至頻 f 1 f_1 f1 與 f 2 f_2 f2 表示了特定任務所需的頻域資訊。
- 與二維卷積相同,SincNet 可以同時學習多個一維卷積,例如 SincNet 第一層濾波器是 80 個,這就使得該帶通濾波器組具有實體統計意義——累積頻率響應(下圖紅色實線 SincNet),即将 80 個濾波器組的通帶累加,并歸一化。此外,先前的 SincNet 講解描述了 SincNet 相比較其與 CNN 學習的優勢。

可解釋的卷積濾波器 SincNet可解釋的卷積濾波器 SincNet - 在累積頻率響應的基礎上,可以發現特定頻率的資訊對特定任務的重要性——占比小/歸一化累積值低的頻域範圍的(針對任務的)重要性較低,例如下圖 2 kHz - 2.5 kHz。
可解釋的卷積濾波器 SincNet可解釋的卷積濾波器 SincNet
噪聲場景的解釋
噪聲場景的語音處理任務是常見的問題,通常設計噪聲魯棒的表示學習和遠距離/遠場的語音處理,包含語音識别和說話人識别。
針對人為的特定頻帶的噪聲,如上時頻譜圖,2 kHz - 2.5kHz 範圍内有一個噪聲。SincNet 可以更早(對比CNN)避免噪聲帶寬,如下圖 1 小時訓練後的累積頻率響應。
基于 SincNet 無監督學習
根據 SincNet 作為說話人的緊湊表示形式,Ravanelli, M. 将其作為語音編碼器,建立了一種無監督學習方法——Local Info Max (LIM)。在 TIMIT、Librispeech 與 VoxCeleb1 三個語料上,LIM 的性能超過了多種監督學習技術,該結論意味着一種潛在的可能:無監督學習方法獲得的說話人嵌入,可以獲得與監督學習更優或者相當的結果。
此外,在 LIM 的研究中,Ravanelli, M. 建立了兩個巧妙假設:
- 兩個随機的語音段可能屬于不同的說話人,
- 每一段語音僅包含當個說話人。
第 2 個假設在常見的訓練集中,通常都是成立的,因為大多數語音段都是按照不同說話人劃分的;而第 1 個假設并不一定成立,特别是在每個說話人都包含大量語音段都時候,有可能來個随機的語音段可能屬于相同的說話人,其機率大緻為 ( n − 1 ) / ( m − 1 ) (n-1)/(m-1) (n−1)/(m−1),其中 n n n 為訓練集中該說話人擁有的語音段數, m m m 為總的語音段數。例如 n = 101 , m = 10001 n=101,m=10001 n=101,m=10001,兩個不同的語音段選擇到同一說話人的機率為 0.1 0.1 0.1,即
( 101 − 1 ) / ( 10001 − 1 ) = 100 / 10000 = 0.01 (101-1)/(10001-1)=100/10000=0.01 (101−1)/(10001−1)=100/10000=0.01
由此可知,這一假設在“多目标說話人鑒别”或者大規模資料集中,其機率非常小,**這意味着假設 1 是顯著可行的。**根據這兩個假設,可以進一步形成一類無監督/自監督學習方法。
值得注意的是,本文采用了互資訊 (Mutual Information, MI) 作為測量兩個随機變量距離的方法,它不僅可以用作無監督學習的優化目标,仍可以作為監督學習模式的正則器。此外,MI 與判别器優化目标的一緻性(都是最大化),使得該學習模型的優化過程相對容易,不會産生類似 GANs 的 min-max 博弈的優化問題。
這裡列出 MI 數學模型 M I ( z 1 , z 2 ) MI(z_1,z_2) MI(z1,z2) 和最簡單有效的判别器損失 binary cross-entropy (BCE) L ( Θ , Φ ) L(\Theta,\Phi) L(Θ,Φ) 分别為:
M I ( z 1 , z 2 ) = ∫ z 1 ∫ z 2 p ( z 1 , z 2 ) log ( p ( z 1 , z 2 ) p ( z 1 ) p ( z 2 ) ) d z 1 d z 2 = D K L ( p ( z 1 , z 2 ) ∥ p ( z 1 ) p ( z 2 ) ) , MI(z_1,z_2)=\int_{z_1}\int_{z_2}p(z_1,z_2)\log\left(\frac{p(z_1,z_2)}{p(z_1)p(z_2)}\right)d_{z_1}d_{z_2}=D_{KL}(p(z_1,z_2)\Vert p(z_1)p(z_2)), MI(z1,z2)=∫z1∫z2p(z1,z2)log(p(z1)p(z2)p(z1,z2))dz1dz2=DKL(p(z1,z2)∥p(z1)p(z2)),
L ( Θ , Φ ) = E X p [ log ( g ( z 1 , z 2 ) ) ] + E X n [ 1 − log ( g ( z 1 , z r n d ) ) ] . L(\Theta,\Phi)=\mathbb{E}_{X_p}\left[\log(g(z_1,z_2))\right]+\mathbb{E}_{X_n}\left[1-\log(g(z_1,z_{rnd}))\right]. L(Θ,Φ)=EXp[log(g(z1,z2))]+EXn[1−log(g(z1,zrnd))].
SincNet 對抗樣本
研究說話人識别的對抗攻擊具有兩個主要應用:
- 攻擊應用:在非系統期望的情況下,擾動說話人識别系統;
- 防禦應用:幫助改善說話人識别系統的性能與魯棒性。
考慮到 SincNet 是以原始波形作為輸入,因而對抗攻擊生成的擾動可以直接作用在原始波形上,産生攻擊行為,這意味着 SincNet 的對抗攻擊是可實作的,研究 SincNet 的對抗攻擊具有必要性。
攻擊者行為如下圖所示,從模型的角度,攻擊行為是建立一個攻擊者模型,該模型在原始波形上加入對抗擾動,進而産生目标模型的誤分類效果。其中攻擊模型采用 adversarial transformation networks (ATNs),該模型無需測試階段的梯度資訊。
另一方面,對抗攻擊加入的擾動會對原有的聲音造成影響,是以,單純采用 L 2 L_2 L2 距離來衡量對抗擾動量并不合理,Li, J. 引入“心理聲學” (psychoacoustic) 的感覺品質和噪聲擾動量來評價語音變化,具體地,PESQ (Perceptual Evaluation of Speech Quality) 與 SNR (Signal-to-Noise Ratio)。Non-targeted 攻擊實作 99.2% 分類誤差,擾動條件高達 57.2 dB SNR 與 4.2 PESQ。
根據擾動的頻譜分布可知,如上圖,高頻段(7 kHz - 8 kHz)較為顯著,這一資訊可以結合 SincNet 濾波器組的累積頻率響應曲線進行分析,但論文中并未做進一步的研究。
這裡有一個概念上的偏差,根據通俗的“累積頻率響應(cumulative frequency response)或者累積頻率圖”的描述:累積頻率用于确定位于資料集中特定值之上(或之下)的觀察次數。
從這一點來看,SincNet 原文中的累積頻率響應更像是一個頻率統計分布:不同頻率區間的濾波器數量統計,即橫軸為頻率,縱軸為頻數的柱狀分布圖(hist)。
參考文獻
本文中的所有圖檔來自參考文獻。
- Ravanelli, M., Bengio, Y., 2019. Speaker Recognition from Raw Waveform with SincNet, in: Proceedings of 2018 IEEE Spoken Language Technology Workshop (SLT). IEEE, Athens, Greece, pp. 1021–1028. https://doi.org/10.1109/SLT.2018.8639585
- Ravanelli, M., Bengio, Y., 2018. Interpretable Convolutional Filters with SincNet, in: 32nd Conference on Neural Information Processing Systems (NIPS 2018) IRASL Workshop. Montréal, Canada.
- Ravanelli, M., Bengio, Y., 2019. Learning speaker representations with mutual information, in: Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH. Graz, Austria, pp. 1153–1157. https://doi.org/10.21437/Interspeech.2019-2380
- Li, J., Zhang, X., Xu, J., Zhang, L., Wang, Y., Ma, S., Gao, W., 2020. Learning to Fool the Speaker Recognition, in: ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 2937–2941. https://doi.org/10.1109/ICASSP40776.2020.9053058
作者資訊:
CSDN:https://blog.csdn.net/i_love_home
Github:https://github.com/mechanicalsea
聯系方式:2019 級同濟大學博士研究所學生 王瑞 [email protected]
研究方向:說話人識别、說話人分離