1. 原理
TF-IDF(term frequency–inverse document frequency)是資訊處理和資料挖掘的重要算法,它屬于統計類方法。最常見的用法是尋找一篇文章的關鍵詞。
其公式如下:
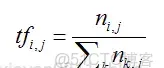
TF(詞頻)是某個詞在這篇文章中出現的頻率,頻率越高越可能是關鍵字。它具體的計算方法如上面公式所示:某關鍵在文章中出現的次數除以該文章中所有詞的個數,其中的i是詞索引号,j是文章的索引号,k是檔案中出現的所有詞。

IDF(逆向文檔頻率)是這個詞出現在其它文章的頻率,它具體的計算方法如上式所示:其中分子是文章總數,分母是包含該關鍵字的文章數目,如果包含該關鍵字的檔案數為0,則分子為0,為解決此問題,分母計算時常常加1。當關鍵字,如“的”,在大多數文章中都出現,計算出的idf值算小。
把TF和IDF相乘,就是這個詞在該文章中的重要程度。
2. 使用Sklearn提供的TF-IDF方法
Sklearn是最常用的機器學習第三方模型,它也支援對TF-IDF算法。
本例中,先使用Jieba工具分詞,并模仿英文句子,将其組裝成以空格分割的字元串。
01 import jieba
02 import pandas as pd
03 from sklearn.feature_extraction.text import CountVectorizer
04 from sklearn.feature_extraction.text import TfidfTransformer
05
06 arr = ['第一天我參觀了美術館',
07 '第二天我參觀了博物館',
08 '第三天我參觀了動物園',]
09
10 arr = [' '.join(jieba.lcut(i)) for i in arr] # 分詞
11 print(arr)
12 # 傳回結果:(謝彥的技術部落格)
13 ['第一天 我 參觀 了 美術館', '第二天 我 參觀 了 博物館', '第三天 我 參觀 了 動物園'] 然後使用sklearn提供的CountVectorizer工具将句子清單轉換成詞頻矩陣,并将其組裝成DataFrame。
01 vectorizer = CountVectorizer()
02 X = vectorizer.fit_transform(arr)
03 word = vectorizer.get_feature_names()
04 df = pd.DataFrame(X.toarray(), columns=word)
05 print(df)
06 # 傳回結果:(謝彥的技術部落格)
07 # 動物園 博物館 參觀 第一天 第三天 第二天 美術館
08 # 0 0 0 1 1 0 0 1
09 # 1 0 1 1 0 0 1 0
10 # 2 1 0 1 0 1 0 0 其方法get_feature_names傳回資料中包含的所有詞,需要注意的是它去掉了長度為1的單個詞,且重複的詞隻保留一個。X.toarray()傳回了詞頻數組,組合後生成了包含關鍵詞的字段,這些操作相當于對中文切分後做OneHot展開。每條記錄對應清單中的一個句子,如第一句“第一天我參觀了美術館”,其關鍵字“參觀”、“第一天”、“美術館”被置為1,其它關鍵字置0。
接下來使用TfidfTransformer方法計算每個關鍵詞的TF-IDF值,值越大,該詞在它所在的句子中越重要:
01 transformer = TfidfTransformer()
02 tfidf = transformer.fit_transform(X)
03 weight = tfidf.toarray()
04 for i in range(len(weight)): # 通路每一句
05 print("第{}句:".format(i))
06 for j in range(len(word)): # 通路每個詞
07 if weight[i][j] > 0.05: # 隻顯示重要關鍵字
08 print(word[j],round(weight[i][j],2)) # 保留兩位小數
09 # 傳回結果 (謝彥的技術部落格)
10 # 第0句:美術館 0.65 參觀 0.39 第一天 0.65
11 # 第1句:博物館 0.65 參觀 0.39 第二天 0.65
12 # 第2句:動物園 0.65 參觀 0.39 第三天 0.65 經過對資料X的計算之後,傳回了權重矩陣,句中的每個詞都隻在該句中出現了一次,是以其TF值相等,由于“參觀”在三句中都出現了,其IDF較其它關鍵字更低。細心的讀者可以發現,其TF-IDF結果與上述公式中計算得出的結果這一緻,這是由于Sklearn除了實作基本的TF-IDF算法外,還其行了歸一化、平滑等一系列優化操作。詳細操作可參見Sklearn源碼中的sklearn/feature_extraction/text.py具體實作。
3. 寫程式實作TF-IDF方法
TF-IDF算法相對比較簡單,手動實作代碼量也不大,并且可以在其中加入定制作化操作,例如:下例中也加入了單個字重要性的計算。
本例中使用了Counter方法統計各個詞在所在句中出現的次數。
01 from collections import Counter
02 import numpy as np
03
04 countlist = []
05 for i in range(len(arr)):
06 count = Counter(arr[i].split(' ')) # 用空格将字串切分成字元串清單,統計每個詞出現次數
07 countlist.append(count)
08 print(countlist)
09 # 傳回結果:(謝彥的技術部落格)
10 # [Counter({'第一天': 1, '我': 1, '參觀': 1, '了': 1, '美術館': 1}),
11 # Counter({'第二天': 1, '我': 1, '參觀': 1, '了': 1, '博物館': 1}),
12 # Counter({'第三天': 1, '我': 1, '參觀': 1, '了': 1, '動物園': 1})] 接下來定義了函數分别計算TF,IDF等值。
01 def tf(word, count):
02 return count[word] / sum(count.values())
03 def contain(word, count_list): # 統計包含關鍵詞word的句子數量
04 return sum(1 for count in count_list if word in count)
05 def idf(word, count_list):
06 return np.log(len(count_list) / (contain(word, count_list)) + 1) #為避免分母為0,分母加1
07 def tfidf(word, count, count_list):
08 return tf(word, count) * idf(word, count_list)
09 for i, count in enumerate(countlist):
10 print("第{}句:".format(i))
11 scores = {word: tfidf(word, count, countlist) for word in count}
12 for word, score in scores.items():
13 print(word, round(score, 2))
14 # 運作結果:(謝彥的技術部落格)
15 # 第0句:第一天 0.28 我 0.14 參觀 0.14 了 0.14 美術館 0.28
16 # 第1句:第二天 0.28 我 0.14 參觀 0.14 了 0.14 博物館 0.28
17 # 第2句:第三天 0.28 我 0.14 參觀 0.14 了 0.14 動物園 0.28