前言
我将通過幾篇文章來介紹一下RNN用于降噪的執行個體。
綜合論文和項目介紹及代碼編寫
原文連結:https://people.xiph.org/~jm/demo/rnnoise/
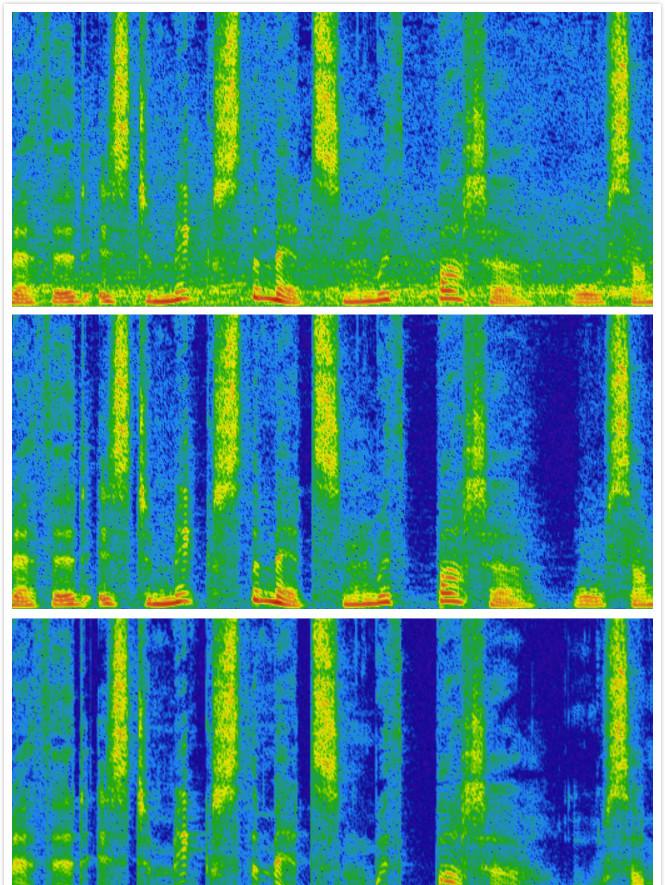
上圖顯示了前後音頻噪聲抑制的頻譜圖。(上:noisy,中:RNNoise,下:clean speech)
RNNoise
該示範介紹了RNNoise項目,顯示了如何将深度學習應用于噪聲抑制。主要思想是将經典信号處理與深度學習結合起來,建立一個小而快速的實時噪聲抑制算法。不需要昂貴的GPU,可以在Raspberry Pi上輕松運作。結果更簡單(更容易調諧),聽起來比傳統的噪音抑制系統更好。
噪聲抑制
噪音抑制是言語進行中的一個相當古老的話題,至少可以追溯到70年代。顧名思義,這個想法是采取嘈雜的信号,并盡可能多地消除噪音,同時對感興趣的言論造成最小的失真。

傳統噪音抑制
這是傳統噪聲抑制算法的概念圖。語音活動檢測(VAD)子產品檢測信号何時包含聲音以及何時隻是噪聲。這被噪聲譜估計子產品用于計算噪聲的頻譜特性(每個頻率多少功率)。然後,知道噪聲模型,它可以從輸入音頻“減去”(并沒有那麼簡單)。
從上圖看,噪聲抑制看起來很簡單:隻是三個概念上簡單的任務,任何大學EE學生都可以寫一個噪音抑制算法,有時困難的是在任何時間,各種噪音情況下使系統工作正常。這需要非常仔細地調整算法中的每個參數,需要在包含大量特殊信号的情況下進行大量的測試。speexdsp庫中的噪音抑制器做了一些工作,但不是很好。
深度學習和循環神經網絡
深度學習是一種新思想的新版本:人工神經網絡。雖然自六十年代以來一直存在,但近年來有了很多重要的新發展:
我們現在知道如何使使用比兩個隐藏層更深的網絡;
我們知道如何讓循環網絡在過去很長時間記住狀态;
我們有實際訓練他們的計算資源。
循環神經網絡(RNN)很好地應用于語音處理,因為它們可以對時間序列模組化,而不是僅僅考慮輸入和輸出幀。這對噪聲抑制特别重要,因為我們需要在時間尺度上獲得較好的噪聲估計。長期以來,RNN的能力受到很大的限制,因為它們長期不能儲存資訊,并且通過時間進行反向傳播時涉及的梯度下降過程是非常低效的(梯度消失問題)。這兩個問題都通過門控單元來解決,如長期記憶(LSTM),門控循環單元(GRU)及多種變體。
RNNoise使用門控循環單元(GRU),因為它在此任務上執行得比LSTM略好,并且需要更少的資源(CPU和權重的存儲容量)。與簡單的循環單元相比,GRU有兩個額外的門。複位門決定是否将目前狀态(記憶)用于計算新狀态,而更新門決定目前狀态将根據新輸入改變多少。這個更新門(關閉時)使得GRU可以長時間地記住資訊,這是GRU(和LSTM)比簡單的循環單元執行得更好的原因。
上圖将簡單的循環單元與GRU進行比較。差別在于GRU的r和z門,這使得有可能學習更長期的模式。兩者都是基于整個層的先前狀态和輸入計算的軟開關(0到1之間的值),具有S形激活功能。當更新門z在左邊時,狀态可以在很長一段時間内保持恒定,直到一個條件使z轉向右邊。
混合方法
由于深入學習的成功,在工程問題中引入深層神經網絡是普遍做法。這些方法稱為端到端——神經元接受并傳遞資訊,使得誤差最小化。端對端方法已被應用于語音識别和語音合成等工程問題,這些端到端系統已經證明了深度神經網絡的強大。另一方面,這些系統有時可能不是最優的,而且在資源方面是浪費的。例如,噪聲抑制的一些方法使用具有數千個神經元和數千萬個權重的層來執行噪聲抑制。缺點是模型運作網絡所需的計算成本巨大,模型本身的規模也難以控制,因為存儲了數千行代碼以及幾十兆位元組的神經元權重。
這就是為什麼我們采用不同的方法原因:保持所有必要的基本信号處理(未經過神經網絡的仿真),緊接着讓神經網絡學習所有需要反複調整參數的棘手繁雜的工作。與現有的深度學習噪音抑制工作不同的是,我們的目标是實時通信而不是語音識别,是以處理的語音幀不能超過幾毫秒(在這種情況下為10毫秒)。
定義問題
為了避免因大量的神經元産生大量的輸出,我們決定不直接使用樣本或頻譜。相反,我們考慮遵循bark scale采用的頻段,一個與我們感覺到的聲音相比對的頻率比例。在此基礎上我們使用總共22個頻段,而不是複雜的480個頻譜值。
Opus混合式編碼的布局與實際的Bark比例頻段的比較。對于RNNoise,我們使用與Opus相同的基本布局。由于我們使頻段重疊,Opus編碼的頻段之間的分界成為重疊的RNNoise頻段的中心。由于耳朵在高頻部分的分辨率較差,是以在高頻段較寬,在低頻下,頻段較窄,但并不像巴克比例那樣窄,因為我們沒有足夠的資料來做出很好的估計。
當然,我們無法從22個頻段的能量重建音頻。我們可以做的是計算一個應用于每個頻帶信号的增益。可以将其視為使用22頻段均衡器,并快速更改每個頻段的電平,以便衰減噪聲,但讓信号通過。
計算頻帶增益的優點:首先,它使模型變得非常簡單,隻需要很少的頻帶計算。第二,不會産生所謂的音樂噪聲僞影(musical noise artifacts),因為在周圍被衰減的同時隻有單音調能通過。這些僞影在噪聲中很常見且很難處理,頻帶足夠寬時,要麼讓整個頻帶通過,要麼剪掉。第三個優點來自于如何優化模型。由于增益總是在0和1之間,是以簡單地使用S形激活函數(其輸出也在0和1之間)來計算它們確定計算方法的正确,比如不在一開始就引入認為噪聲。
分頻段計算的缺點是在沒有語音的足夠分辨率時不能在基頻諧波之間很細緻的抑制噪聲。但是這并不是那麼重要,因為可以通過額外的手段來處理,比如使用一個類似于語音編碼增強的後濾波方法:使用梳狀濾波器在一個基頻周期(pitch period)内消除間諧波噪聲(inter-harmonic noise)。
由于我們計算的輸出是基于22個頻段的,是以輸入頻率分辨率更高是沒有意義的,是以我們使用相同的22個子帶将頻譜資訊提供給神經網絡。因為音頻具有很大的動态範圍,是以計算能量的log而不是直接傳送能量值。更進一步,我們使用這個對數值進行DCT對特征進行去相關。所得到的資料是基于Bark量表的倒譜,其與語音識别中非常常用的梅爾倒譜系數(MFCC)密切相關。
頻帶結構
純粹的RNN模型處理8khz語音,計算增益使用了6144個隐藏單元,大概1000萬個權重
對于20ms的48khz語音需要400個輸出。
使用一個較粗的範圍尺度比按照頻率尺度計算更有效。選取了音頻編碼較常使用的bark scale
Ex的計算:
求平方和,并做一次指數平滑,每個頻帶的增益:
Ex是clean speech,Es是noisy信号,頻率尺度的插值增益:
深層結構
我們使用的網絡架構靈感源于傳統的噪音抑制方法。大部分工作是由3個GRU層完成的。下圖顯示了我們用于計算頻帶增益的層次,以及架構如何映射到噪聲抑制中的傳統步驟。當然,與普通神經網絡一樣,我們沒有實際的證據證明網絡如我們期望的一樣運作,而是設計成這樣的結構确實證明能比其他的網絡做的效果更好。
上圖的展示的是次項目所使用的拓撲結構,每個方框代表了一層中的神經元,指出了數目,标記了激活函數。一個VAD輸出,在某些方面有用,但是并沒有用于噪聲抑制網絡的乘數。另一個22維的輸出,将增益用于不同的頻率,可以進行噪聲抑制。
訓練資料
在噪聲抑制的情況下,我們不能僅僅收集可用于監督學習的輸入/輸出資料,因為我們很少同時獲得幹淨的語音和噪音。相反,我們必須從清晰的語音和噪音的單獨錄音中人為地建立資料。 棘手的部分是獲得各種各樣的噪音資料,以增強語音。 我們還必須確定覆寫各種錄音條件。 例如,僅在全頻段音頻(0-20 kHz)下訓練的早期版本在8 kHz低通濾波時失效。作者使用McGill TSP speech database1 (Frenchand English) 和NTT Multi-Lingual Speech Database for Telephonometry 。噪聲有computer fans, office, crowd, airplane, car,train, construction。使用6小時的clean speech和4小時的noise,産生了140個小時的noisy speech,并在40khz-54khz範圍内重采樣。
與語音識别常見的不同,我們選擇不将倒譜平均歸一化應用于特征,并保留代表能量的第一個倒譜系數。 是以,我們必須確定資料包括所有現實級别的音頻。 我們還對音頻應用随機濾波器,使系統對各種麥克風頻率響應(通常由倒譜均值歸一化處理)具有魯棒性。
r∈[-3/8,3/8]
優化過程Optimization process
在(0,1)範圍内,交叉熵是神經網絡訓練普遍使用的損失函數,但是對于語音信号,結果并不能很好的比對感覺影響(perceptual effect),采用了平方誤差L(g_b,g ̂_b)=(〖g_b〗^γ-〖g ̂_b〗^γ )^2
γ是一個感覺參數,控制了在多大程度抑制噪聲。使用時不采用log域的mean square loss防止過度抑制,折中的做法是取γ=1/2。
VAD 的輸出使用的是标準交叉熵損失。
訓練過程使用tensorflow backend和keras library。
Gain smoothing
使用增益g來抑制噪聲會使聲音聽起來很枯燥,缺少回響。可以通過限制g在幀之間的衰減來修複:
g(prev)是前一幀的過濾後的增益,λ=0.6可以相當于回響時間是135ms。
Pitch filtering
由于我們的頻帶的頻率分辨率不足,無法濾除音調諧波之間的噪聲,是以我們使用基本的信号處理。 這是混合方式的另一部分。當有相同變量的多個測量值時,提高精度(降低噪聲)的最簡單方法就是計算平均值。顯然,隻是計算相鄰音頻樣本的平均值不是我們想要的,因為它會導緻低通濾波。然而,當信号是周期性的(例如語音)時,我們可以計算由基頻周期偏移的采樣的平均值。引入梳狀濾波器,使基頻諧波通過,同時衰減它們之間的頻率這是含有噪聲的部分。為了避免信号失真,梳狀濾波器被獨立地應用于每個頻帶,并且其濾波器強度取決于基頻相關性和神經網絡計算的頻帶增益。
我們目前使用FIR濾波器進行pitch filtering,但也可以使用IIR濾波器,如果強度太高,則會導緻更高的失真風險,進而産生較大的噪聲衰減。
從Python到C
神經網絡的所有設計和訓練都是使用Keras深度學習庫在Python中完成的。由于Python通常不是實時系統的首選語言,是以我們必須在C中實作代碼。幸運的是,運作神經網絡比訓練一個神經網絡簡單得多,是以我們隻需要實作一次前向傳播經過GRU層,輸出22維的增益。為了更好的調整出權重的合理步幅,我們在訓練期間将權重的大小限制為+/- 0.5,這使得可以使用8位值輕松存儲它們。所得到的模型僅85 kB(而不是将權重存儲為32位浮點數所需的340 kB)。
C代碼可以使用BSD許可證。代碼在x86 CPU上的運作速度比實時的要快60倍。它甚至比Raspberry Pi 3上的實時速度快7倍。具有良好的矢量化(SSE / AVX),應該可以比現在快四倍。
該代碼仍然在積極的開發(沒有封裝API),但已經在應用程式中使用。它目前的應用場景是VoIP /視訊會議應用程式,但通過一些調整,它可能适用于許多其他任務。一個容易想到的任務是自動語音識别(ASR),雖然我們隻能去除嘈雜的語音并将輸出發送到ASR,但這不是最優的,因為它丢棄了一些不确定性的有用資訊。ASR不僅需要clean speech,而且還可以依賴于這一估計值時,這是更有用的。 RNNoise的另一個可能的目标是為電子樂器創造一個更加智能的噪音門。所有它應該采用的是良好的訓練資料和一些代碼的變化,将一個Raspberry Pi變成一個真正好的吉他噪音門。
參考文檔
RNNoise: Learning Noise Suppression
https://people.xiph.org/~jm/demo/rnnoise/
1、 The code: RNNoise Git repository :
https://git.xiph.org/?p=rnnoise.git;a=summary
(Github mirror:https://github.com/xiph/rnnoise/)
2、J.-M. Valin, A Hybrid DSP/Deep Learning Approach to Real-Time Full-Band Speech Enhancement, arXiv:1709.08243 [cs.SD], 2017.
https://arxiv.org/pdf/1709.08243.pdf
3、 Jean-Marc’s blog post for comments
https://jmvalin.dreamwidth.org/15210.html