前言
前段時間分析了yolov3的源碼,這次想帶着小夥伴一起把yolov5完全掌握。部落客還是保持着一貫的風格,依舊采用debug級别的源碼剖析。目的就是讓大家可以通過一個系列的文章就把yolov5的架構、設計理念和每一行源碼都弄懂。隻要小夥伴可以花時間把這個系列讀完,就會對yolov5的了解有所提升。
去年參加了kaggle的小麥檢測比賽,yolov5在比賽的中段開始呈現霸榜趨勢,超越了efficientdet。雖然最後yolov5因為權限等某些問題被kaggle官方禁用了,但是仍然展現出了其強大的能力。值得一學,學習本篇前讀者應該至少對于yolo系列中的一個或幾個有所了解,對照着學習更加利于了解。
前面做了yolov3的源碼剖析,不了解的讀者也可以學習下:
傳送門:
yolov3 源碼debug解析
下面我們就開始yolov5的學習吧,第一篇我們先focus在yolov5的架構上,對其各個元件有所了解,對其設計理念有所認知,然後在這個基礎上開始逐行對yolov5進行debug解析。值得注意的是yolov5的架構一直在疊代演進,不同版本之間稍有差別,但是基本上是一緻的。
一.yolov5 架構剖析
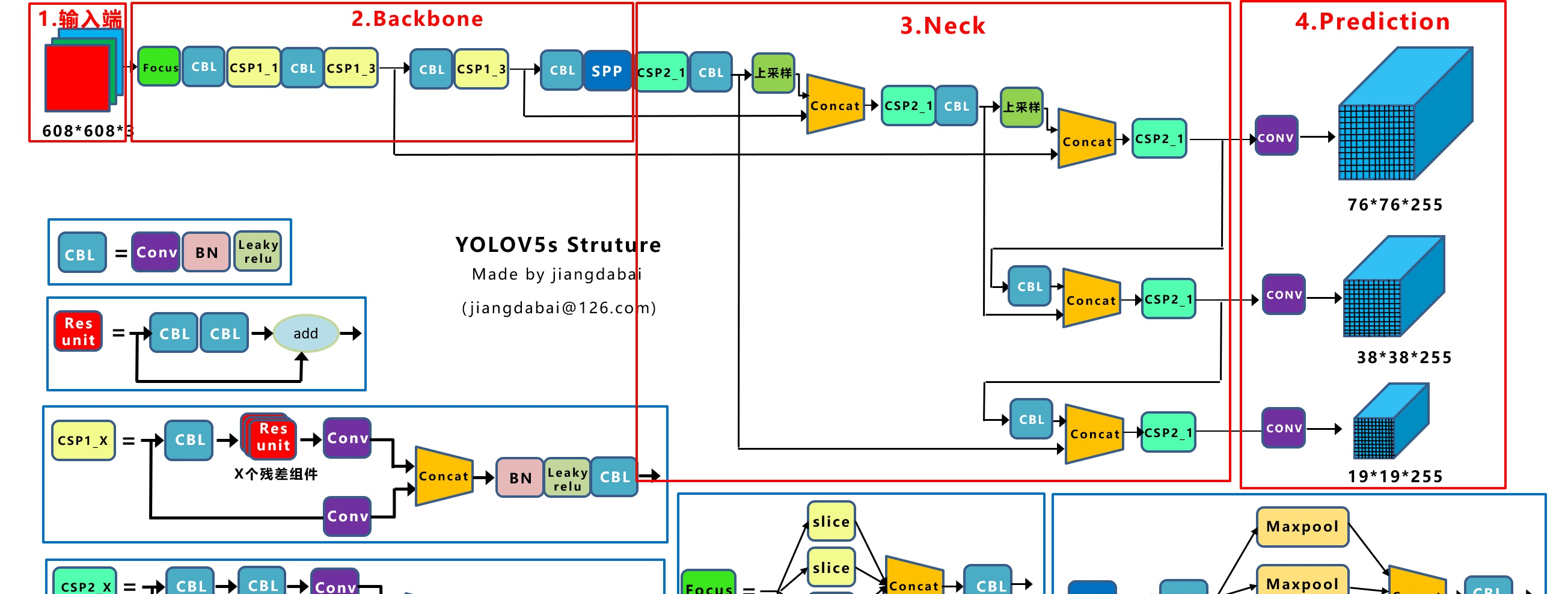
這是yolov5s的架構,圖來自于百度圖檔,部落客查了下應該是知乎上一個大神畫的。這裡尊重大神創作,給下位址:
圖檔出處傳送門
從yolov5s到yolov5x之間的差别就是不同的block疊加次數不同,見下圖:

從架構上看,yolov5的架構設計并不複雜,整體上維持了FPN的設計方式,FPN加強了重複疊代,兩次疊代的結構稱為PAN。這個結構還可以進一步重複,類似efficientdet那樣演進為BiFPN。backbone仍然是darknet的形式,通過殘差結構讓網絡加深。模型開始引入Focus的設計有點奇特,直接就降低了resolution應該是yolov5輕量的原因之一。SPP子產品的引入進一步融合了多尺度特征提取。有兩種不同的CSP子產品,差別是有無殘差結構,
整體設計和子產品的加減像是消融實驗的産物,不過我們還是逐個子產品過下:
1. Focus
Focus的理念比較特殊,執行過程見下圖:
我在觀察Focus這個設計的時候帶着的問題是這樣的設計是為什麼以及這樣的設計為什麼work?
我的了解是首先它這樣的排列方式是将相鄰的四個塊從平面改為特征上的concat。
也就是這樣的四個塊做了疊加,從3通道變為12通道,這樣盡可能的保留了位置資訊。同一個通道裡應該代表着局部的特征表達,這樣操作一個grid位置代表了原圖四個grid的特征。在保證了位置資訊盡可能保留的情況下又增大了感受野。
這樣的效果是特征圖的尺寸為原來的一半,在這裡我想到的問題是卷積是能夠保持特征的位置相對性的,那麼這種focus操作能否正常化代替pooling或者是stride=2的卷積呢?我們都知道pooling對feature map的資訊的丢失是很嚴重的(當然也有一部分正則化的作用),是以很多現在的架構設計裡pooling都被stride=2的convolution代替。我又想到了shufflenet裡的channel shuffle操作是在做了組卷積之後,怕看不到全局特征,為了增強channel間的特征共享,進行的特征融合。是以Focus操作後面是否也應該增強每個格點通過concat拼接起來的特征向量的融合,比如通過1x1 group convolution。yolov5的融合采用的是一個普通的CBL(conv–bn–leakyrelu)。
2.CSP
yolov5的設計中有兩種CSP結構,一種是帶了resunit(2*CBL卷積+殘差),一種是用普通的CBL替換resunit。帶殘差的部分是用在backbone裡,不帶殘差的是用在backbone之外的地方。這裡應該是實驗的結果,backbone為較深的網絡,增加殘差結構可以增強層與層之間反向傳播的梯度值,避免因為加深而帶來的梯度消失,進而提取到更細粒度的特征而不必擔心網絡退化。同時,有些研究表明殘差結構可以看作非殘差的ensemble,進而增強部分的泛化能力。
當然以上都是理論上的分析,我之前在競賽中對于unet的encoder,bridge,decoder的部分都分别測試了殘差結構,也發現encoder的部分對于殘差結構是比較依賴的,但是bridge和decoder的殘差結構都沒有獲得精度上的提高。這裡隻是說一下我之前的實驗結果,供大家參考。
CSP結構的好處就是對比普通的CBL,它分為兩個支路,有支路就意味着特征的融合,而concat就可以更好的把不同支路的特征資訊保留下來,是以CSP的設計可以提取到更為豐富的特征資訊。
3.SPP
SPP這個結構就是通過不同kernel size的pooling抽取不同尺度特征,再進行疊加進行特征融合。在yolov5裡pooling的kernel size分别是11, 55, 99, 1313。
我在很多比賽中都測試過SPP和ASPP加在不同網絡的各種位置,其實就是為了找到适配資料的最佳感受野大小,但1其實這個過程是比較耗時的,因為對應的pooling kernel和dilation rate都是非常難以調整的。是以也可以使用可變形卷積讓網絡自動适配感受野。
4.PAN
FPN還是PAN或者後面的BiFPN都是類似的結構。FPN的理念就是增強不同層特征融合,在多尺度上進行預測。PAN在FPN的基礎上又加了從下到上的融合。
我們都知道,深層的feature map攜帶有更強的語義特征,較弱的定位資訊。而淺層的feature map攜帶有較強的位置資訊,和較弱的語義特征。FPN就是把深層的語義特征傳到淺層,進而增強多個尺度上的語義表達。而PAN則相反把淺層的定位資訊傳導到深層,增強多個尺度上的定位能力。
再聯想後來的BiFPN,語義特征和定位資訊在串聯的FPN/PAN結構中被像踢皮球一樣的“傳來傳去”…咳咳,都是玄學。
以上就是yolov5中的架構比較特殊的地方,具體我們還是在代碼中去識别他們。
二.yolov5 源碼剖析準備
源碼傳送門(pytorch實作)
我們在debug前先要保證把yolov5跑起來。安裝下面的步驟操作就可以跑通:
1.下載下傳yolov5源碼,安裝requirement.txt
需要注意python>=3.8,pytorch>=1.7。
$ git clone https://github.com/ultralytics/yolov5 # clone repo
$ cd yolov5
$ pip install -r requirements.txt # install dependencies
2.配置dataset的yaml檔案,準備資料
yolov5識别yaml配置檔案,是以自定義的資料集就要按照模闆去寫。我們以最簡單的coco128為例,coco128是coco資料集的前128張組成的小型資料集,用來驗證流程。位址在yolov5/data檔案夾裡,coco128.yaml。我們來看下coco128.yaml的内容:
# COCO 2017 dataset http://cocodataset.org - first 128 training images
# Train command: python train.py --data coco128.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /coco128
# /yolov5
# download command/URL (optional)
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../coco128/images/train2017/ # 128 images
val: ../coco128/images/train2017/ # 128 images
# number of classes
nc: 80
# class names
names: [ 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush' ]
可見定義資料集的配置檔案需要可以包含三個部分内容:
- download:下載下傳位址(可選的)
- train/val:train資料集和val資料集的相對路徑
- nc:類别數
- names:類别的具體名字
我們先手動下載下傳coco128資料集,并放在yolov5的同一級目錄裡:
coco128下載下傳連結
如上圖所示放在同一級目錄。
images不用多說,就是訓練圖檔,而labels需要注意下格式,自己标注的也要注意轉換為yolo格式。
每一個圖檔的label單獨存放在一個txt檔案裡,每一個框單獨占一行。如下圖所示:
坐标需要做歸一化,如下圖:
如上圖所示,yolo的标簽資料為[class, x_center, Y_center, width, height]的格式,要注意class是從0開始計算的。四個坐标則都需要歸一化到0-1之間,也就是如果你的資料是pixel的,那麼需要對應除以寬高。
最後檔案夾相應位置如下圖所示對齊:
如果準備好了coco128資料,就可以測試了。
3.準備好模型檔案
模型預設有yolov5s、m、l、x四種,參數量從小到大。大家在官網下載下傳好對應的模型。
模型下載下傳位址
我這邊下載下傳一個yolov5s做示範。下載下傳好放到weights檔案夾下:
$ python train.py --img 640 --batch 16 --epochs 5 --data coco128.yaml --weights yolov5s.pt
執行上述代碼進行測試,可以看到訓練開始。
Epoch gpu_mem box obj cls total targets img_size
0/4 0G 0.0492 0.0805 0.03435 0.1641 35 640: 16%|██████▋
4.wandb*
yolov5可以配置wandb,一個動态展示訓練狀态的web portal,用以觀察loss和裝置情況。
以上我們就成功跑通了yolov5,為我們後面開始debug源碼做好了準備。請大家移步到下一篇讓我們共同探索yolov5的源碼吧!
下一篇傳送門