監控視訊中的現實世界異常檢測,代碼位址https://paperswithcode.com/paper/real-world-anomaly-detection-in-surveillance。
摘要
監控視訊能夠捕捉到各種現實的異常現象。在本文中,我們建議通過利用正常和異常視訊來學習異常。為了避免注釋訓練視訊中的異常片段或剪輯,這是非常耗時的,我們建議利用弱标記的排名架構通過深度多執行個體訓練視訊來訓練異常,即訓練标簽(異常或正常)是在視訊級而不是剪輯級。在我們的方法中,我們将正常視訊和異常視訊作為包和視訊片段作為多執行個體學習(MIL)的執行個體,并自動學習一個深度異常排名模型,該模型預測異常視訊片段的高異常分數。此外,我們在排序損失函數中引入了稀疏性和時間平滑性限制,以更好地在訓練過程中定位異常。
我們還介紹了一個新的第一個大規模的128小時的視訊資料集。它由1900時長且未經修改的真實監控視訊組成,其中有13個現實的異常現象,如戰鬥、道路事故、盜竊、搶劫等,當然還包括正常的活動。這個資料集可以用于兩個任務。第一,用于一組所有異常和另一組所有正常活動的一般異常檢測。第二,用來識别13種異常活動中的每一種。實驗結果表明,與現有的方法相比,我們的MIL方法在異常檢測性能方面取得了顯著的提高。我們提供了最近幾個關于異常活動識别的深度學習基線的結果。這些基線的低識别性能表明,我們的資料集非常具有挑戰性,并為未來的工作提供了更多的機會。該資料集可在:https://webpages.uncc.edu/cchen62/dataset.html上獲得。
1.介紹
監控錄影機被越來越多地用于公共場所。街道、十字路口、銀行、購物中心等。以增加公共安全。但是,執法機構的監測能力并沒有跟上其步伐。其結果是,監控攝像頭的使用明顯不足,而且攝像頭與人類監控器的比例不可行。視訊監控的一項關鍵任務是檢測交通事故等異常事件、犯罪或非法活動。一般來說,與正常活動相比,異常事件很少發生。是以,為了減少人工和時間的浪費,迫切需要開發自動檢測的智能計算機視覺算法。一個實際的異常檢測系統的目标是及時發出偏離正常模式的活動的信号,并識别所發生的異常的時間窗。是以,異常檢測可以看作是粗糙層次的視訊了解,它可以過濾掉正常模式中的異常。一旦檢測到異常,可以使用分類技術将其歸為特定活動之一。
解決異常檢測的一個小步驟是開發檢測特定異常事件的算法,例如暴力檢測器[30]和交通事故檢測器[23,34]。然而,很明顯,這種解決方案不能推廣到檢測其他異常事件,是以它們在實踐中的應用有限。
現實世界中的反常事件是複雜而多樣化的。很難列出所有可能的反常事件。是以,希望異常檢測算法不依賴于關于事件的任何先驗資訊。換句話說,異常檢測應在最低限度的監督下進行。基于稀疏編碼的方法[28,41]被認為是實作最先進的異常檢測結果的代表性方法。這些方法假設視訊的一小部分初始部分包含正常事件,是以初始部分用于建構正常事件字典。那麼,異常檢測的主要思想是異常事件不能準确地從正常事件字典中重構。然而,由于監控錄影機捕捉到的環境可能會随着時間的推移而發生巨大的變化。在一天的不同時間),這些方法對不同的正常行為産生高假警率。
動機和貢獻。雖然上述方法很吸引人,但它們是基于這樣的假設,即任何偏離學習到的正常模式的模式都将被視為異常。然而,這個假設可能不成立,因為很難或不可能定義一個将所有可能的正常模式/行為考慮到正常模式/行為的正常事件。更重要的是,正常行為和異常行為之間的邊界往往是模糊的。此外,在現實條件下,相同的行為可能是不同條件下的正常或異常行為。是以,我們認為正常事件和異常事件的訓練資料可以幫助異常檢測系統更好地學習。本文提出了一種利用弱标記訓練視訊進行檢測的異常檢測算法。也就是說,我們隻知道視訊級别的标簽,即一個視訊是正常的或在某些地方包含異常的,但我們不知道在哪裡。這很有趣,因為我們可以通過隻配置設定視訊級的标簽來很容易地注釋大量的視訊。為了建立一種弱監督學習方法,我們求助于多執行個體學習(MIL)[12,4]。具體來說,我們建議通過深度MIL架構來學習異常,将正常和異常的監控視訊作為包,将每個視訊的短片段/剪輯作為包中的執行個體。基于訓練視訊,我們自動學習一個異常排名模型,預測視訊中異常片段的高異常分數。在測試過程中,一個長時間未修剪的視訊被分成多個片段,并輸入我們的深度網絡,該網絡為每個視訊片段配置設定異常分數,這樣就可以檢測到異常。綜上所述,本文做出了以下貢獻。
我們提出了一種僅利用弱标記的訓練視訊進行異常檢測的MIL解決方案。我們提出了一種對深度學習網絡具有稀疏性和平滑性限制的MIL排序損失來學習視訊片段的異常分數。據我們所知,我們是第一個在MIL的背景下制定視訊異常檢測問題。
我們介紹了一個大規模的視訊異常檢測資料集,由1900個13個不同異常事件的真實監控視訊組成。它是迄今為止最大的資料集,視訊比現有的異常資料集超過15倍,總共有128小時的視訊。
在新資料集上的實驗結果表明,該方法比最先進的異常檢測方法取得了優越的性能。由于活動的複雜性和巨大的類内變化。
我們的資料集也為未修剪視訊的活動識别提供了一個具有挑戰性的基準。在識别13種不同的異常活動上,我們提供了基線方法,C3D[36]和TCNN[21]。
2.相關工作
異常檢測 異常檢測是計算機視覺[39,38,7,10,5,20,43,27,26,28,42,18,26]中最具挑戰性和長期存在的問題之一。對于視訊監控應用程式,有幾次嘗試來檢測視訊中的暴力或攻擊性[15,25,11,30]。Datta等人。建議通過利用人的運動和肢體取向來檢測人類暴力。Kooij等人。[25]利用視訊和音頻資料來檢測監控視訊中的攻擊性行為。高等人提出了用暴力流動描述來檢測人群視訊中的暴力行為。最近,Mohammadi等人。[30]提出了一種新的基于行為啟發式的暴力和非暴力視訊分類方法。
除了暴力和非暴力模式的區分,[38,7]的作者還提出使用跟蹤來模組化人的正常運動,并将偏離正常運動的偏差作為異常來檢測。由于難以獲得可靠的軌迹,有幾種方法避免通過基于直方圖的方法來跟蹤和學習全局運動模式[10],主題模組化[20],運動模式[31],社會力量模型[29],動态紋理模型[27]的混合物,隐馬爾可夫模型(HMM)在局部時空體積[26],和上下文驅動的方法[43]。給定正态行為的訓練視訊,這些方法學習正态運動模式的分布,并檢測低可能的模式為異常。
随着稀疏表示和字典學習方法在幾個計算機視覺問題上的成功發展,[28,42]中的研究人員使用稀疏表示來學習正常行為的字典。在測試過程中,重構誤差較大的模式被視為異常行為。由于深度學習在圖像分類中的成功示範,人們提出了幾種用于視訊動作分類[24,36]的方法。然而,擷取關于教育訓練的注釋是不同的和費力的,特别是對于視訊。
近年來,[18,39]使用基于深度學習的自動編碼器來學習正常行為模型,并利用重構損失來檢測異常。我們的方法不僅考慮正常行為,而且考慮異常檢測的異常行為,隻使用弱标記的訓練資料。
排序 學習排序是機器學習中一個活躍的研究領域。這些方法主要集中于提高項目的相對分數,而不是獨立的分數。喬阿奇姆斯 (Joachims)等人[22]提出了rank-SVM來提高搜尋引擎的檢索品質。 (Bergeron)伯格登等人,[8]提出了一種利用連續線性規劃求解多執行個體排序問題的算法,示範了其在計算化學中的氫抽象問題中的應用。近年來,深度排序網絡已被應用于一些計算機視覺應用,并顯示出最先進的性能。它們已被用于特征學習[37]、高亮檢測[40]、圖形交換格式(GIF)生成[17]、人臉檢測和驗證[32]、人重新識别[13]、位置識别[6]、度量學習和圖像檢索[16]。所有的深度排序方法都需要大量的正樣本和負樣本的注釋。
與現有的方法相比,我們利用正常和異常資料将異常檢測作為排序架構中的回歸問題。為了減少獲得精确的段級标簽的困難。為了進行訓練,我們利用了依賴于弱标記資料的多執行個體學習。視訊級标簽-正常或異常,比時間注釋更容易獲得,學習異常模型并檢測視訊片段級異常。
3.提出的異常檢測方法
所提出的方法(如圖1所總結)從在訓練期間将監控視訊分成固定數量的片段開始。這些片段在一個包中制作執行個體。同時使用正(異常)和負(正常)包,我們使用所提出的深度多執行個體排序損失來訓練異常檢測模型。
3.1.Multiple Instance Learning
在使用支援向量機的标準監督分類問題中,所有的正和負例子的标簽都是可用的,并使用以下優化函數學習分類器:
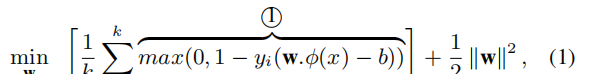
其中①為hinge loss,yi表示每個示例的标簽,φ(x)表示圖像更新檔或視訊片段的特征表示,b為偏置,k為訓練示例的總數,w為要學習的分類器。為了學習一個魯棒的分類器,需要對正的和負的例子進行準确的注釋。在監督異常檢測的背景下,分類器需要對視訊中的每個片段進行時間注釋。然而,擷取視訊的時間注釋是費時費力的。
MIL放寬了具有這些準确的時間注釋的假設。在MIL中,視訊中異常事件的精确時間位置是未知的。相反,隻需要視訊級的标簽來顯示整個視訊中存在異常。包含異常的視訊被标記為正,沒有任何異常的視訊被标記為負。然後,我們将一個積極的視訊表示為一個積極的包Ba,其中不同的時間段在包中生成單獨的執行個體,(p1,p2,…,pm),其中m是包中的執行個體數。我們假設這些執行個體中至少有一個包含異常。類似地,負的視訊用一個負的包Bn表示,其中這個包中的時間段形成負的執行個體(n1,n2,…,nm)。在負的包中,沒有一個執行個體包含異常。由于正執行個體的确切資訊(即執行個體級标簽)未知,是以可以根據每個包[4]中的最大分數執行個體來優化目标函數:

其中YBj表示包級标簽,z為包的總數,其他所有變量都與等式1中相同
3.2Deep MIL Ranking Model
異常行為很難準确定義[9],因為它是相當主觀的,可能有很大的差異。此外,如何為異常情況配置設定1/0的标簽并不明顯。此外,由于沒有足夠的異常例子,異常檢測通常被視為低可能性模式檢測,而不是分類問題[10,5,20,26,28,42,18,26]。
在我們提出的方法中,我們将異常檢測作為一個回歸問題。我們希望異常視訊片段比正常片段有更高的異常分數。直接的方法将是使用一個排序損失(rank loss),這鼓勵了異常視訊片段比正常片段的高分,例如:
其中,Va和Vn表示異常和正常的視訊片段,f(Va)和f(Vn)分别表示相應的預測分數。如果在訓練中知道視訊片段的注釋,上述rank函數應該很良好。
然而,在沒有視訊片段注釋的情況下,不可能使用等式3.相反,我們提出了以下多執行個體排序目标函數:
其中max是在每個包中的所有視訊片段。我們不是要在包的每個執行個體上執行排名,而是隻要在正包和負包中異常得分最高的兩個執行個體上執行排名。正包中最高異常得分對應的段最有可能是真正的陽性執行個體。與負包中最高的異常得分對應的段看起來最像一個異常段,但實際上是一個正常的執行個體。這個負的執行個體被認為是一個困難的執行個體,它可能會在異常檢測中産生錯誤,變成陽性。通過使用方程式4,我們想把正執行個體和負執行個體區分開。是以,我們在hinge loss公式中的排序損失如下:
上述損失的一個局限性是,它忽略了異常視訊的潛在時間結構。首先,在現實場景中,異常通常隻發生很短的時間。在這種情況下,異常包中的執行個體(段)的分數應該是稀疏的,這表明隻有少數段可能包含異常。第二,由于視訊是一系列片段,異常分數應該在視訊片段之間平滑地變化。是以,我們通過最小化相鄰視訊片段的分數差異來加強時間相鄰視訊片段的異常分數之間的時間平滑性。通過結合對執行個體分數的稀疏性和平滑性限制,損失函數成為
其中,①表示時間平滑度項,②表示稀疏性項。在這個MIL的ranking loss中,該loss從正包和負包的最大分數視訊片段反向傳播。通過對大量的正包和負包進行訓練,我們希望讓網絡将學習一個廣義模型來預測正包中異常片段的高分(見圖8)。最後,我們完整的目标函數是
其中,W表示模型的權重。
标簽形式。我們将每個視訊分成等數量的不重疊的時間段,并使用這些視訊段作為包執行個體。給定每個視訊片段,我們提取三維卷積特征[36]。我們使用這種特征表示是由于它的計算能力強,在視訊動作識别中有明顯的捕捉外觀和動作動力學的能力。
圖1 所提出的異常檢測方法的流程圖。給定正(包含某個地方的異常)和負(不包含異常)的視訊,我們将它們分成多個時間視訊片段。然後,每個視訊被表示為一個包,每個時間段代表包中的一個執行個體。在提取視訊片段的C3D特征[36]後,我們利用一種新的排序損失函數(ranking loss)訓練一個全連接配接的神經網絡,該函數計算正包中得分最高的執行個體(紅色)之間的排序損失。
4.資料集
4.1.以前的資料集
我們簡要回顧了現有的視訊異常檢測資料集。UMN資料集[2]由五個不同的階段性視訊組成,人們在那裡四處走動,一段時間後開始向不同的方向運作。異常的特征是隻有運作的動作。UCSDPed1和Ped2資料集[27]分别包含70個和28個監控視訊。這些視訊隻在一個地點拍攝。視訊中的異常很簡單,并不能反映視訊監控中的實際異常。人們走過人行道上,沒有行人(溜冰者、騎自行車者和輪椅)。Avenue資料集[28]由37個視訊組成。雖然它包含更多的異常,但它們是在一個位置上捕獲的。與[27]類似,這個資料集中的視訊很短,而且一些異常是不現實的,例如:扔紙)。Subway Exit and Subway Entrance 資料集每個視訊都包含一個長長的監控視訊。這兩個視訊捕捉到了一些簡單的異常情況,比如走向錯誤的方向和跳過付款。BOSS[1]資料集是從安裝在火車上的監控攝像頭中收集的。它包含騷擾、患者、恐慌症以及正常視訊。所有的異常都由行為者執行的。總的來說,以前的視訊異常檢測資料集在視訊數量或視訊長度方面都很小。異常情況的變化也很有限。此外,有些異常現象是不現實的。
4.2.我們的資料集
由于以往資料集的局限性,我們建構了一個新的大規模資料集來評估我們的方法。它由長時間未修改的監控視訊組成,涵蓋了13個現實世界的異常情況,包括虐待、逮捕、縱火、襲擊、事故、盜竊、爆炸、戰鬥、搶劫、槍擊、偷店行竊和破壞。之是以選擇這些異常現象,是因為它們對公共安全有重大影響。我們将我們的資料集與表1中以前的異常檢測資料集進行了比較。
視訊收集。為了確定我們的資料集的品質,我們訓練了10個資料标注者(具有不同層次的計算機視覺專業知識)來收集資料集。我們在YouTube1和LiveLeak2上使用每個異常現象的文本搜尋查詢(有輕微的變化,如“車禍”、“交通事故”)來搜尋視訊。為了檢索盡可能多的視訊,我們還使用不同語言(如法語、俄語、漢語等)的文本查詢。對于每一個異常現象,請感謝谷歌翻譯器。我們删除了屬于以下任何情況之一的視訊:手動編輯,惡作劇視訊,不是被閉路電視攝像頭拍攝的,拍攝新聞,使用手持相機拍攝的,并包含編譯的。我們也丢棄了其中異常情況尚不清楚的視訊。在上述視訊剪枝限制下,收集了950個未經編輯的真實世界中有明顯異常的監控視訊。使用相同的限制條件,收集了950個正常視訊,導緻我們的資料集中共有1900個視訊。在圖2中,我們展示了來自每個異常的四幀示例視訊。
注釋。對于我們的異常檢測方法,隻需要視訊級的标簽來進行訓練。然而,為了評估其在測試視訊上的性能,我們需要知道時間的注釋,即每個測試異常視訊中的異常事件的開始和結束幀。為此,我們将相同的視訊配置設定給多個注釋者,以标記每個異常的時間範圍。最終的時間注釋是通過平均不同注釋器的注釋來獲得的。經過幾個月的艱苦努力,完整的資料集最終确定。
Training and testing 資料集。我們将資料集分為兩部分:訓練集包括800個正常視訊和810個異常視訊(詳情見表2所示),測試集包括其餘150個正常視訊和140個異常視訊。訓練集和測試集都包含了視訊中不同時間位置的所有13個異常。此外,其中一些視訊有多種異常現象。訓練視訊在長度(分鐘)的分布如圖3所示。每個測試視訊中的幀數和異常百分比分别如圖4和圖5所示。
5.實驗
5.1.實施細節
我們從C3D網絡[36]的全連接配接(FC)層FC6中提取視覺特征。在計算特性之前,我們将每個視訊幀重新調整為240×320像素,并将幀率固定為30fps。我們計算每16幀視訊剪輯的C3D特征,然後進行l2歸一化。為了獲得一個視訊片段的特征,我們取該片段内所有16幀剪輯特征的平均值。我們将這些特征(4096D)輸入到一個3層的FC神經網絡中。第一個FC層有512個單元,然後是32個單元和1個單元的FC層。在FC層之間使用60%的dropout正則化[33]。我們用更深層次的網絡進行實驗,但沒有觀察到更好的檢測精度。我們在第一FC層和最後一層分别使用ReLU[19]激活和Sigmoid激活,并使用Adagrad[14]優化器,初始學習率為0.001。将MIL ranking loss中的稀疏性和平滑性限制參數設定為λ1=λ2=8×10−5,以獲得最佳性能。
我們将每個視訊分成32個不重疊的片段,并将每個視訊片段作為包的一個執行個體。32是依靠經驗設定的。我們還實驗了多尺度重疊的時間段,但不影響檢測精度。我們随機選擇30個陽性包和30個陰性包作為一個小批次。我們利用Theano[35]在計算圖上通過反向模式自動微分來計算梯度。具體來說,我們确定了損失所依賴的變量集,計算了每個變量的梯度,并通過計算圖上的鍊規則得到了最終的梯度。每個視訊通過網絡,我們得到其每個時間段的分數。然後我們計算損失,如等式6和等式7、并反向傳播整個批次的損失。
評估度量。
在之前對異常檢測[27]的研究之後,我們使用(ROC)曲線和曲線下相應的面積(AUC)來評價我們的方法的性能。我們不使用等錯誤率(EER)[27],因為它不能正确測量異常,特别是當長視訊的一小部分包含異常行為時。
表1 異常資料集的比較。我們的資料集包含更多的更長的監控視訊和更現實的異常。
圖2 我們資料集中訓練和測試視訊的不同異常的例子。
5.2.與最先進的技術進行比較
我們比較了我們的方法與兩種最先進的異常檢測方法。陸等人[28]提出了基于字典的正常行為學習方法,并利用重構誤差來檢測異常。根據它們的代碼,我們從每個正常的訓練視訊中提取7000個長方體,并計算每個卷中基于梯度的特征。在使用主成分分析減少特征維數後,我們使用稀疏表示法學習字典。哈桑等人[18]提出了一種基于完全卷積前饋深度自動編碼器的學習局部特征和分類器的方法。利用他們的實作方法,我們在正常視訊上進行訓練網絡,并使用40幀的時間視窗。與[28]類似,我們使用重建誤差來測量異常情況。我們還使用一個二進制SVM分類器作為基線方法。具體來說,我們将所有異常視訊視為一個類,而将正常視訊視為另一個類。計算每個視訊的C3D特征,用線性核訓練一個二進制類符。對于測試,該分類器提供了每個視訊片段是異常的機率。我們還比較我們有和沒有平滑性和稀疏性限制方法的結果。結果表明,該方法的性能明顯優于現有的方法。特别是,我們的方法在低假陽性機率下比其他方法獲得了更高的真陽性機率。
二值分類器的結果表明,傳統的動作識别方法不能用于現實監控視訊中的異常檢測。這是因為我們的資料集包含長時間的未修剪的視訊,其中異常大多發生在短時間内。是以,從這些未修剪的訓練視訊中提取的特征對于異常事件沒有足夠的差別性。在實驗中,二進制分類器對幾乎所有的測試視訊産生非常低的異常分數。由[28]學習的字典不夠健壯,不足以區分正常模式和異常模式。除了對視訊的正常部分産生低重建誤差外,對異常部分也産生低重建誤差。哈桑等人。[18]學習正常模式。然而,即使是對于新的正常模式,它也往往會産生很高的異常分數。我們的方法表現明顯優于[18],證明了其有效性,并強調了使用異常和正常視訊的訓練對于魯棒的異常檢測系統是必不可少的。
圖7 該方法對視訊測試的定性結果。彩色視窗顯示ground truth異常區域。(a)、(b)、©和(d)分别顯示包含虐待動物(毆打狗)、爆炸、交通事故和槍擊事件的視訊。(e)和(f)顯示正常視訊,無異常。(g)和(h)提出了我們的異常檢測方法的兩種故障案例。
在圖7中,我們在8個視訊上展示了我們的方法的定性結果。(a)-(d)顯示四個具有異常事件的視訊。我們的方法通過為異常幀産生高異常分數,提供了成功和及時地檢測這些異常。(e)和(f)是兩個正常的視訊。我們的方法在整個視訊中産生較低的異常分數(接近0),對兩個正常視訊産生零誤警。我們還說明了(g)和(h)中的兩個故障情況。具體來說,(g)是包含入室盜竊事件(人通過視窗進入辦公室)的異常視訊。由于場景的黑暗(夜間視訊),我們的方法未能檢測到異常部分。此外,它産生的假警主要是由于在鏡頭前被飛蟲遮擋。在(h)中,我們的方法會由于人們突然聚集(在街道上觀看接力賽)而産生假警。換句話說,它不能識别正常的群體活動。
5.3.提出的方法分析
圖8 訓練視訊分數的演變。彩色視窗表示ground truth(異常區域)。随着疊代的增加,我們的方法在異常視訊片段上産生高異常分數,在正常片段上得分低。
模型訓練。該方法的基本假設是,給定大量帶有視訊級标簽的正面和負面視訊,網絡可以自動學習預測視訊中異常的位置。為了實作這一目标,網絡應該學習在訓練疊代過程中給異常視訊片段産生高分。圖8顯示了一個訓練異常例子在疊代中的異常分數的演變。在1000次疊代中,該網絡預測異常視訊片段和正常視訊片段都有高分。經過3000次疊代後,網絡開始對正常段産生低分數,并保持異常段的高分數。随着疊代次數的增加和網絡看到更多的視訊,它會自動學習精确定位異常。請注意,雖然我們不使用任何段級别的注釋,但該網絡能夠根據異常分數來預測異常的時間位置。
表4 在正常測試視訊上的誤報率比較
假警率。在現實世界中,監控視訊的一個大部分是正常的。魯棒的異常檢測方法在正常視訊上應具有較低的假警率。是以,我們隻評估了我們的方法和其他方法在正常視訊上的性能。表4列出了不同方法在50%門檻值下的假警率。我們的方法的假警率率要與其他方法相比低得多,表明了一種更魯棒的異常檢測系統。這驗證了同時使用異常和正常視訊進行訓練有助于我們的深度MIL排序模型學習正常模式。
5.4.異常活動識别實驗
我們的資料集可以作為異常活動識别基準,因為我們在資料收集過程中有異常視訊的事件标簽,但不用于我們上面讨論的異常檢測方法。對于活動識别,我們使用來自每個事件的50個視訊,并将它們分成75 :25的比例進行訓練和測試3。基于4倍交叉驗證,我們在我們的資料集上提供了兩個活動識别的基線結果。
圖9 (a)和(b)顯示我們資料集上使用C3D[36]和TCNN[21]的活動識别的混淆矩陣。
表5 C3D[36]和TCNN[21]的活性識别結果。
對于第一個基線,我們通過平均每個16幀剪輯的C3D[36]特征,然後進行l2标準化,建構一個4096維的特征向量。該特征向量被用作對最近鄰分類器的輸入。第二個基線是管卷積神經網絡(TCNN)[21],它引入了感興趣的管道(ToI)池化層來取代C3D管道中的第5個三維最大池化層。ToI池化層聚合了所有剪輯的特征,并為整個視訊輸出一個特征向量。是以,它是一種基于端到端深度學習的視訊識别方法。定量的結果,即混淆矩陣和準确性如圖9和表5所示。這些最先進的動作識别方法在這個資料集上表現較差。這是因為這些視訊是長期未修剪的低分辨率的監控視訊。此外,由于錄影機視點和照明的變化,以及背景噪聲的變化,存在很大的類内變化。是以,我們的資料集是一個獨特的和具有挑戰性的異常活動識别資料集。
6.結論
我們提出了一種深度學習方法來檢測監控視訊中的現實世界異常。由于這些現實異常的複雜性,僅使用正常資料可能不是異常檢測的最佳方法。我們試圖同時利用正常和異常的監控視訊。為了避免訓練視訊中異常片段注釋耗費大量精力、時間,我們學習了一個使用具有弱标記資料的深度多執行個體排序架構進行異常檢測的通用模型。為了驗證該方法,本文引入了一種新的由各種真實世界中的異常組成的大規模異常資料集。在該資料集上的實驗結果表明,我們提出的異常檢測方法明顯優于基線方法。此外,我們還證明了我們的資料集對異常活動識别的第二個任務的有效性。
7.Acknowledgement
該項目由 Award No. 2015-R2-CXK025支援,由 the National Institute of Justice, Of-
fice of Justice Programs, U.S. Department of Justice贊助。本出版物中所表達的意見、調查結果、結論或建議是作者的意見,并不一定反映司法部的意見。
References
[1] http://www.multitel.be/image/researchdevelopment/research-projects/boss.php.
[2] Unusual crowd activity dataset of university of minnesota. In http://mha.cs.umn.edu/movies/crowdactivity-all.avi.
[3] A. Adam, E. Rivlin, I. Shimshoni, and D. Reinitz. Robust real-time unusual event detection using multiple fixedlocation monitors. TPAMI, 2008.
[4] S. Andrews, I. Tsochantaridis, and T. Hofmann. Support vector machines for multiple-instance learning. In NIPS, pages 577–584, Cambridge, MA, USA, 2002. MIT Press.
[5] B. Anti and B. Ommer. Video parsing for abnormality detection. In ICCV, 2011.
[6] R. Arandjelovi´c, P. Gronat, A. Torii, T. Pajdla, and J. Sivic.NetVLAD: CNN architecture for weakly supervised place recognition. In CVPR, 2016.
[7] A. Basharat, A. Gritai, and M. Shah. Learning object motion patterns for anomaly detection and improved object detection. In CVPR, 2008.
[8] C. Bergeron, J. Zaretzki, C. Breneman, and K. P. Bennett.Multiple instance ranking. In ICML, 2008.
[9] V. Chandola, A. Banerjee, and V. Kumar. Anomaly detection: A survey. ACM Comput. Surv., 2009.
[10] X. Cui, Q. Liu, M. Gao, and D. N. Metaxas. Abnormal detection using interaction energy potentials. In CVPR, 2011.
[11] A. Datta, M. Shah, and N. Da Vitoria Lobo. Person-onperson violence detection in video data. In ICPR, 2002.
[12] T. G. Dietterich, R. H. Lathrop, and T. Lozano-P´erez. Solving the multiple instance problem with axis-parallel rectangles. Artificial Intelligence, 89(1):31–71, 1997.
[13] S. Ding, L. Lin, G. Wang, and H. Chao. Deep feature learning with relative distance comparison for person re-identification. Pattern Recognition, 48(10):2993–3003,2015.
[14] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. J.Mach. Learn. Res., 2011.
[15] Y. Gao, H. Liu, X. Sun, C. Wang, and Y. Liu. Violence detection using oriented violent flows. Image and Vision Computing, 2016.
[16] A. Gordo, J. Almaz´an, J. Revaud, and D. Larlus. Deep image retrieval: Learning global representations for image search.In ECCV, 2016.
[17] M. Gygli, Y. Song, and L. Cao. Video2gif: Automatic generation of animated gifs from video. In CVPR, June 2016.
[18] M. Hasan, J. Choi, J. Neumann, A. K. Roy-Chowdhury,and L. S. Davis. Learning temporal regularity in video sequences. In CVPR, June 2016.
[19] G. E. Hinton. Rectified linear units improve restricted boltzmann machines vinod nair. In ICML, 2010.
[20] T. Hospedales, S. Gong, and T. Xiang. A markov clustering topic model for mining behaviour in video. In ICCV, 2009.
[21] R. Hou, C. Chen, and M. Shah. Tube convolutional neural network (t-cnn) for action detection in videos. In ICCV,2017.
[22] T. Joachims. Optimizing search engines using clickthrough data. In ACM SIGKDD, 2002.
[23] S. Kamijo, Y. Matsushita, K. Ikeuchi, and M. Sakauchi.Traffic monitoring and accident detection at intersections.IEEE Transactions on Intelligent Transportation Systems,1(2):108–118, 2000.
[24] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar,and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, 2014.
[25] J. Kooij, M. Liem, J. Krijnders, T. Andringa, and D. Gavrila.Multi-modal human aggression detection. Computer Vision and Image Understanding, 2016.
[26] L. Kratz and K. Nishino. Anomaly detection in extremely crowded scenes using spatio-temporal motion pattern models. In CVPR, 2009.
[27] W. Li, V. Mahadevan, and N. Vasconcelos. Anomaly detection and localization in crowded scenes. TPAMI, 2014.
[28] C. Lu, J. Shi, and J. Jia. Abnormal event detection at 150 fps in matlab. In ICCV, 2013.
[29] R. Mehran, A. Oyama, and M. Shah. Abnormal crowd behavior detection using social force model. In CVPR, 2009.
[30] S. Mohammadi, A. Perina, H. Kiani, and M. Vittorio. Angry crowds: Detecting violent events in videos. In ECCV, 2016.
[31] I. Saleemi, K. Shafique, and M. Shah. Probabilistic modeling of scene dynamics for applications in visual surveillance.TPAMI, 31(8):1472–1485, 2009.
[32] A. Sankaranarayanan, S. Alavi and R. Chellappa. Triplet similarity embedding for face verification. arXiv preprint arXiv:1602.03418, 2016.
[33] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res., 2014.
[34] W. Sultani and J. Y. Choi. Abnormal traffic detection using intelligent driver model. In ICPR, 2010.
[35] Theano Development Team. Theano: A Python framework for fast computation of mathematical expressions. arXiv preprint arXiv:1605.02688, 2016.
[36] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri.Learning spatiotemporal features with 3d convolutional networks. In ICCV, 2015.
[37] J. Wang, Y. Song, T. Leung, C. Rosenberg, J. Wang,J. Philbin, B. Chen, and Y. Wu. Learning fine-grained image similarity with deep ranking. In CVPR, 2014.
[38] S. Wu, B. E. Moore, and M. Shah. Chaotic invariants of lagrangian particle trajectories for anomaly detection in crowded scenes. In CVPR, 2010.
[39] D. Xu, E. Ricci, Y. Yan, J. Song, and N. Sebe. Learning deep representations of appearance and motion for anomalous event detection. In BMVC, 2015.
[40] T. Yao, T. Mei, and Y. Rui. Highlight detection with pairwise deep ranking for first-person video summarization. In CVPR,June 2016.
[41] B. Zhao, L. Fei-Fei, and E. P. Xing. Online detection of unusual events in videos via dynamic sparse coding. In CVPR,pages 3313–3320, 2011.
[42] B. Zhao, L. Fei-Fei, and E. P. Xing. Online detection of unusual events in videos via dynamic sparse coding. In CVPR,2011.
[43] Y. Zhu, I. M. Nayak, and A. K. Roy-Chowdhury. Contextaware activity recognition and anomaly detection in video. In IEEE Journal of Selected Topics in Signal Processing, 2013.