原文連結 :http://tecdat.cn/?p=3433
原文出處:拓端資料部落公衆号
本文我們讨論期望最大化理論,應用和評估基于期望最大化的聚類。
軟體包
資料
我們将使用mclust軟體包附帶的“糖尿病”資料。
data(diabetes)
summary(diabetes)
## class glucose insulin sspg## Chemical:36 Min. : 70 Min. : 45.0 Min. : 10.0## Normal :76 1st Qu.: 90 1st Qu.: 352.0 1st Qu.:118.0## Overt :33 Median : 97 Median : 403.0 Median :156.0## Mean :122 Mean : 540.8 Mean :186.1## 3rd Qu.:112 3rd Qu.: 558.0 3rd Qu.:221.0## Max. :353 Max. :1568.0 Max. :748.0
期望最大化(EM)
期望最大化(EM)算法是用于找到最大似然的或在統計模型參數,其中該模型依賴于未觀察到的潛變量最大後驗(MAP)估計的疊代方法。期望最大化(EM)可能是無監督學習最常用的算法。
似然函數
似然函數找到給定資料的最佳模型。
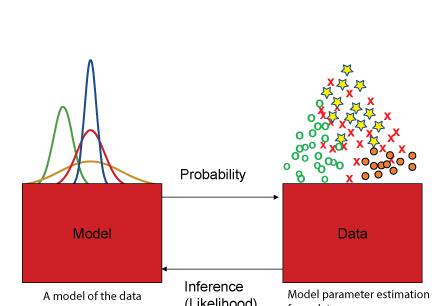
期望最大化(EM)算法
假設我們翻轉硬币并得到以下内容 - 0,1,1,0,0,1,1,0,0,1。我們可以選擇伯努利分布
或者,如果我們有以厘米為機關的人的身高(男性和女性)的資料。高度遵循正常的分布,但男性(平均)比女性高,是以這表明兩個高斯分布的混合模型。

貝葉斯資訊準則(BIC)
以糖尿病資料為例
EM叢集與糖尿病資料使用mclust。
log.likelihood:這是BIC值的對數似然值
n:這是X點的數量
df:這是自由度
BIC:這是貝葉斯資訊标準; 低是好的
ICL:綜合完整X可能性 - BIC的分類版本。
clPairs(X,class.d)
EM的繪圖指令會生成以下四個繪圖:
BIC值用于選擇簇的數量
聚類圖
分類不确定性的圖表
簇的軌道圖
參考文獻
1.R語言k-Shape算法股票價格時間序列聚類
2.R語言中不同類型的聚類方法比較
3.R語言對用電負荷時間序列資料進行K-medoids聚類模組化和GAM回歸
4.r語言鸢尾花iris資料集的層次聚類
5.Python Monte Carlo K-Means聚類實戰
6.用R進行網站評論文本挖掘聚類
7.用于NLP的Python:使用Keras的多标簽文本LSTM神經網絡
8.R語言對MNIST資料集分析 探索手寫數字分類資料
9.R語言基于Keras的小資料集深度學習圖像分類