1. 主要思想
從前一層的資料中取K個候選點(p1,p2,...pK),使用MLP(多層感覺器)來學習一個K×K 的變換矩陣(X-transformation,X變換)也就是說X=MLP(p1,p2,...pK),然後用它同時對輸入特征進行權重和置換,最後對經過變換的特征應用典型卷積。我們稱這個過程為X-Conv,它是PointCNN的基本構模組化塊。
從前一層中選取代表點集的方法,暫時的實作是:
- 對分類問題:随機下采樣。
- 對語義分割問題:最遠點采樣。
2. 與CNN的對比圖
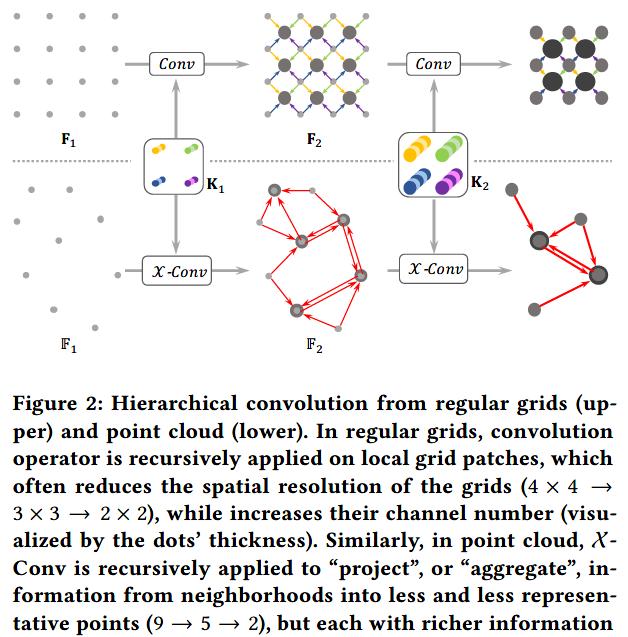
3. X-Conv卷積操作

- P'←P−p 将點集P變換到以p點為中心的局部坐标系
- Fδ←MLPδ(P') 逐點應用MLPδ,将P′從R3坐标空間映射到RCδ特征空間
- F∗←[Fδ,F] 把Fδ 和F拼接起來,F∗ 是一個 K×(Cδ+C1) 矩陣
- X←MLP(P') 用MLP學習P′獲得K×K的X變換矩陣
- FX←X×F∗ 應用X變換矩陣權重置換 F∗
- Fp←Conv(K,FX) 做卷積
首先将點轉換到代表點的局部坐标系,然後将每個點升到Cδ次元,再将提取特征和原來C1個特征融合進行融合。對于轉換後的點學習到X變換矩陣,對融合後的特征變換得到FX,再采用卷積處理
4. PointCNN架構
分類任務
在Fig4(a)中,我們展示了一個簡單的PointCNN,帶有兩個X-Conv層,逐漸将輸入點(帶有或不帶有特征)轉換為較少的代表點,但每個點都具有更豐富的特征。在第二個X-Conv層之後,隻剩下一個代表點,它從前一層的所有點接收資訊。
在PointCNN中,我們可以将每個代表點的感受野粗略地定義為比率K / N,其中K是相鄰點的數目,N是前一層中的點的數目。通過這個定義,最後一個剩下的點“看到”來自上一層的所有點,是以具有接受域1.0 – 它具有整個形狀的全局視圖,是以它的特征為形狀的語義了解提供了資訊。
我們可以在最後一個X -conv層輸出的頂部增加一些完全連接配接的層,然後是用于訓練網絡的損失。
請注意,Fig4(a)中PointCNN的頂層X-Conv層的訓練樣本數量迅速下降,使得徹底訓練頂層X-Conv層的效率很差。
為了解決這個問題,我們提出了Fig4(b)中的PointCNN,其中更多的代表點被保留在X-Conv層中。但是,我們希望保持網絡的深度,同時保持感受野的增長率,使得更深層的代表點“看到”整個形狀的越來越大的部分。我們通過将圖像CNN中的空洞卷積思想應用到PointCNN中來實作這一目标。我們可以不總是以K個鄰近點作為輸入,而是從K×D個鄰近點對K個輸入點進行均勻采樣,其中D是膨脹率。在這種情況下,感受野從K/N增加到(K×D)/N,而不增加實際相鄰點數量,也不增加核心大小。
在Fig4(b)中的PointCNN的第二個X-Conv層中,使用了膨脹率D = 2,是以剩下的所有四個代表點“看到”整個形狀,并且它們都适合做出預測。請注意,通過這種方式,與Fig4(a)的PointCNN相比,我們可以更徹底地訓練頂層X-Conv層,因為網絡涉及更多的連接配接。在測試時間内,多個代表點的輸出在sof tmax之前進行平均,以穩定預測結果。這種設計非常類似于網絡中[Lin et al]的網絡。我們的分類任務使用的是密度更高的PointCNN(Fig4(b))。
分割任務
對于分割任務,需要高分辨率逐點輸出,這可以通過在Conv-DeConv之後建構PointCNN來實作[Noh et al. 2015]架構,DeConv部分負責将全局資訊傳播到高分辨率預測中(見Fig4(c))。
請注意,PointCNN分段網絡中的“Conv”和“DeConv”都是相同的X-Conv算子。對于“DeConv”圖層,與“Conv”圖層唯一的差別在于,輸出中的點數比輸入點中的點數多,但特征通道少。“DeConv”層的更高分辨率點從早期的“Conv”層轉發,遵循U-Net的設計[Ronneberger et al.2015年]。
ELU [Clevert et al. 2016]是PointCNN中使用的非線性激活函數,因為我們發現它比ReLU更穩定并且性能更好些。在P′,Fp和FC層輸出(除了最後的FC層的輸出)上應用Batch Normalization [loffe和Szegedy 2015]以減少内部協變量偏移(Internal covariate shift)。要注意,Batch Normalization不應該應用于MLPδ和MLP,因為F∗和X,特别是X,對于特定代表點來說應該是的相當具體的。對于算法1第6行的Conv,可用分離卷積(Separable convolution )替代傳統卷積來減少參數數量和計算量。在PointCNN的訓練中,我們使用ADAM優化器,初始學習率為0.01。
在最後完全連接配接的層之前施加Dropout以減少過拟合。我們還采用了Qi等人的“子體積監督(Subvolume supervision)”理念來解決過拟合問題。在最後的X-Conv層中,感受野 被設定為小于1,使得最後的X-Conv層中的代表點僅“看到”部分資訊。在訓練時促使網絡更加深入了解局部資訊,并在測試時表現更好。
在本文中,PointCNN用分類任務的簡單前饋網絡和簡單的前饋圖層以及分割網絡中的跳躍連結來示範。然而,由于暴露于其輸入和輸出層的接口X-Conv與Conv非常相似,我們認為許多來自圖像CNN的先進神經網絡技術可以用于X-Conv,比如說循環PointCNN。我們将在未來的工作中沿着這些方向展開探索
資料增強
對于X-Conv中的參數的訓練,顯然,如果相鄰點對于特定代表點始終是相同順序的相同集合,是很不利的。為了提高可推廣性,我們提出随機抽樣和縮減輸入點,使得相鄰點集和順序可能因批次不同而不同。為了訓練以N個點為輸入的模型,應有N(N,(N/8)2)個點用于訓練,其中N表示高斯分布。我們發現這一政策對于PointCNN的訓練至關重要。
5. 未來與未來工作展望(4.4 部分的翻譯)
1. X-變換的進一步了解
雖然X-Conv是被設計用來進行在三維點雲上進行卷積,并且它在實驗中展示了最新水準的結果,但是我們對它背後的理論方法仍然知之甚少,尤其是當它被用于深層神經網絡上時,我們的了解還十分的有限。
PointCNN采取了最簡單也是最直接的方式來學習X-Conv——用MLP學習變換矩陣。雖然一般的矩陣可以用來實作權值和順序變換,但是這種方法是否是實作目标的最簡形式仍然是不得而知的。實際上,相比于此前的其他方法,PointCNN的參數更少,但還是在部分小規模的資料上表現出了過拟合的問題。X-Conv在帶來強大的表征能力的同時,也可能攜帶了大量額外的自由度,能否找到一種比一般的矩陣更加精煉的可以學習的表達形式,或許是X-Conv發展的方向。
2. PointCNN對形狀分析的應用
文章中說明了PointCNN對分類和圖像分割問題的特征學習的有效性。我們認為PointCNN學習的特征可以在多種形狀分析任務中超過手工設計的特征,例如關鍵點比對,形狀檢索等任務。
全卷積的PointCNN
在原本的CNN中運用了全卷積的思想來處理不同大小的圖像,PointCNN也應該實作全卷積的方法來處理不同尺度的點雲。這篇論文使用了對全卷積方法的幾乎最暴力的近似方法,在之後的擴充中,需要更有效的點雲索引和記憶體管理來實作全卷積的X-Conv操作。
3. PointCNN還是CNN?
由于X-Conv是卷積的一種推廣,是以,對于相同的資料(但是表達形式不同),PointCNN應該至少不比CNN要差,甚至要更好。為了證明這一點,論文中将PointCNN運用到了MNIST和CIFAR10的點雲形式上。在MNIST資料集上,PointCNN達到了所有比較的方法中的最好的效果,而對于沒有太多形狀資訊的CIFAR10資料集上,PointCNN從RGB特征的空間局部相關性中提取特征并且達到了還算不錯的效果,但它和基于圖檔的CNN差距還很大。
從CIFAR10實驗來看。在一般的圖像上, CNN仍然是比PointCNN更好的選擇。而PointCNN的優勢在資料越稀疏的時候越能展現出來。目前并沒有一個科學的準則判斷是應該将資料表達為規則形式進而應用CNN,還是應該将資料表達為點雲形式進而應用PointCNN。有意思的是,部分密集的資料也許可以被稀疏的表達,例如視訊通常被表現為密集的三維資料,但是通常在視訊幀裡面隻有少量的像素是逐幀變化的。 PointCNN加上稀疏但不規則表達的視訊資料也是一個有趣的方向。
4. PointCNN和CNN的結合
由于三維擷取技術的高速發展,越來越多的采集的資料同時具有三維點雲和圖像,在這種情況下獨立運用PointCNN和CNN分别來處理點雲和圖像資料,再将結果合并用于最後的推理也許是一種方法,但或許可以在更早期将這兩種資料融合起來處理。
https://baijiahao.baidu.com/s?id=1591175293564503054&wfr=spider&for=pc
https://blog.csdn.net/qq_15602569/article/details/79560614
https://blog.csdn.net/elliottzheng/article/details/80568154