參考連結
官網:http://www.cvlibs.net/datasets/kitti/index.php
傳感器介紹:http://www.cvlibs.net/datasets/kitti/setup.php
相機内外參簡介:https://www.cnblogs.com/wangguchangqing/p/8126333.html
好-KITTI資料集–參數+原文翻譯:https://www.pianshen.com/article/7493742838/
好-kitti資料集在3D目标檢測中的入門:https://www.pianshen.com/article/97781400793/
kitti可視化工具:https://github.com/kuixu/kitti_object_vis
mmdet3d可視化代碼:mmdet3d/core/visualizer/image_vis.py
3D資料集轉換腳本:https://github.com/open-mmlab/mmdetection3d/tree/master/tools/data_converter # kitti waymo, nuscenes等
看論文永遠是你的第一選擇
-
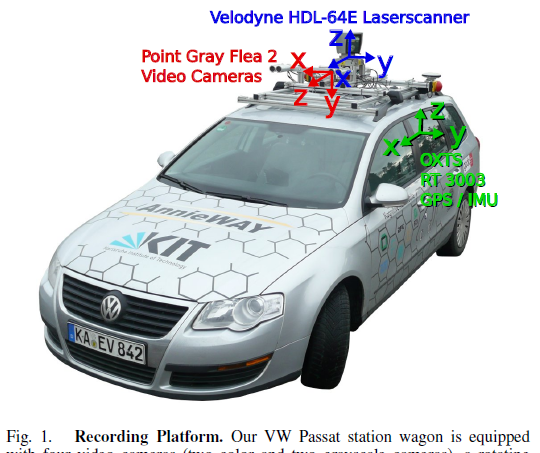
相機
2個灰階相機(P0, P1)
2個彩色相機(P2, P3)
- GPS / IMU (定位資訊 + 加速度/加加速度)
-
Lidar
64線,Velodyne HDL-64E
每秒 10 幀的速度旋轉,每周期捕獲10萬個點,垂直分辨率64?
相機由雷射掃描器(面向前方時)以每秒 10 幀的速度觸發,快門時間動态調整(最大快門時間:2 毫秒)
- 圖像:采用8bit PNG格式儲存。裁剪掉了原始圖像的引擎蓋和天空部分,并且根據相機參數進行了畸變矯正,最終圖檔為50萬像素左右。
- 雷射:逆時針旋轉,采用浮點數二進制檔案儲存。儲存了雷射點(x,y,z)坐标和反射率r資訊,每一幀平均12萬個雷射點。
- 圖像和雷射同步:相機曝光時機是由雷射控制的,當雷射掃描到正前方(即相機朝向角度)時,會觸發相機快門,KITTI會記錄雷射3個時間戳,旋轉起始和結束的時刻,以及觸發相機曝光的時刻。
傳感器車身排布如下圖所示:

點雲velodyne檔案
xxx.bin就是,就是存儲xyzr(點雲坐标+反射強度)的檔案
上圖這個效果咋出來的??
3D檢測
簡介
3D檢測較經典的資料集,入坑必會的資料集之一。除了3D檢測,還有2D檢測,flow,segmentation,depth等标注。
類别
有這些類别
總共有9類,分别是:Car、Van、Truck、Pedestrian、Person_sitting、Cyclist、Tram、Misc、DontCare。其中DontCare标簽表示該區域沒有被标注,比如由于目标物體距離雷射雷達太遠。為了防止在評估過程中(主要是計算precision),将本來是目标物體但是因為某些原因而沒有标注的區域統計為假陽性(false positives),評估腳本會自動忽略DontCare區域的預測結果。
但是榜單上隻顯示了3個大類…
另外,mmdet3d資料集中的pkl檔案,裡面是否做了類别合并???需要去check一下
資料量
- 訓練集:7481;驗證集:3768;測試集:7518
- 8W+目标(感覺還是比較少???,訓出來的模型名額差異可能會比較大)
PS:做mono3d,通常用P2 (左彩) 相機作為輸入。
标注
第1列(字元串):代表物體類别(type)
分别是:Car、Van、Truck、Pedestrian、Person_sitting、Cyclist、Tram、Misc、DontCare。
- 第2列(浮點數):代表物體是否被截斷(truncated) 數值在0(非截斷)到1(截斷)之間浮動,數字表示指離開圖像邊界對象的程度。
- 第3列(整數):代表物體是否被遮擋(occluded) 整數0、1、2、3分别表示被遮擋的程度。0:完全可見 1:部分遮擋 2:大部分遮擋 3:未知。在mmdet3d中有-1,表示ignore。
- 第4列(弧度數):物體的觀察角度(alpha) 取值範圍為:-pi ~ pi(機關:rad),它表示在相機坐标系下,以相機原點為中心,相機原點到物體中心的連線為半徑,将物體繞相機y軸旋轉至相機z軸,此時物體方向與相機x軸的夾角,如圖1所示。
- 第5~8列(浮點數):物體的2D邊界框大小(bbox) 四個數分别是xmin、ymin、xmax、ymax(機關:pixel),表示2維邊界框的左上角和右下角的坐标。
- 第9~11列(浮點數):3D物體的尺寸(dimensions)分别是高、寬、長 (HWL)(機關:米),mmdet3d中轉為了LHW?因為送出過程做了LHW到HWL的轉換
- 第12-14列(整數):3D物體的位置(location)分别是x、y、z(機關:米),特别注意的是,這裡的xyz是在相機坐标系下3D物體的中心點位置。
- 第15列(弧度數):3D物體的空間方向(rotation_y)取值範圍為:-pi ~ pi(機關:rad),它表示,在照相機坐标系下,物體的全局方向角(物體前進方向與相機坐标系x軸的夾角),逆時針為負,順時針為正,如下圖所示。
- 第16列(整數):檢測的置信度(score)要特别注意的是,這個資料隻在測試集的資料中有,評測的時候網絡輸出。
校準檔案
評測名額
使用PASCAL VOC的标注來對3D檢測進行評估,也是用AP。幾點注意:
- 太遠的物體會被忽略(圖像平面上bbox heigth太小),也就是’DontCare’這個類别?
- 點雲中的3D物體隻有在圖像平面中才會被标記,其他區域不會被考慮。
- cars,要求3D IOU=0.7,對于pedestrians and cyclists ,要求3D IOU=0.5
- Easy, Moderate, Hard定義如下
Easy: Min. bounding box height: 40 Px, Max. occlusion level: Fully visible, Max. truncation: 15 %
Moderate: Min. bounding box height: 25 Px, Max. occlusion level: Partly occluded, Max. truncation: 30 %
Hard: Min. bounding box height: 25 Px, Max. occlusion level: Difficult to see, Max. truncation: 50 %
三種難度根據1、物體大小;2、遮擋occlusion;3、階段truncation;來區分的。
榜單上的結果按照Moderate名額進行排名:All methods are ranked based on the moderately difficult results.
- update 08.10.2019,根據論文《Disentangling Monocular 3D Object Detection》的建議,評測由之前recall軸上取11點轉為取40點。
下面這句話不了解??
We note that the evaluation does not take care of ignoring detections that are not visible on the image plane — these detections might give rise to false positives.
榜單
連結:http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
-
基于lidar的方法
名額都巨高,SOTA算法,Car大概84+;Pedestrian大概48+;Cyclist大概72+;
-
基于視覺的方法
名額差很多,Car大概17+就可以了??
注意事項
- 啊
- 啊
- 啊