=======================================================
在pytorch中有幾個關于顯存的關鍵詞:
在pytorch中顯存為緩存和變量配置設定的空間之和叫做reserved_memory,為變量配置設定的顯存叫做memory_allocated,由此可知reserved_memory一定大于等于memory_allocated,但是pytorch獲得總顯存要比reserved_memory要大,pytorch獲得的總顯存空間為reserved_memory+PyTorch context。
在不同顯示卡和驅動下PyTorch context的大小是不同的,如:
https://zhuanlan.zhihu.com/p/424512257
所述,RTX 3090的context 開銷。其中3090用的CUDA 11.3,開銷為1639MB。
執行代碼:
import torch
temp = torch.tensor([1.0]).cuda() NVIDIA顯存消耗:
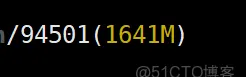
其中:

我們知道memory_reserved大小為2MB,那麼context大小大約為1639MB。
給出
https://zhuanlan.zhihu.com/p/424512257
圖檔:
可以知道,pytorch并沒有直接采用作業系統的顯存管理機制而是自己又寫了一個顯存管理機制,使用這種層級的管理機制在cache中申請顯存不需要向OS申請而是在自己的顯存管理程式中進行調配,如果自己的cache中顯存空間不夠再會通過OS來申請顯存,通過這種方法可以進一步提升顯存的申請速度和減少顯存碎片,當然這樣也有不好的地方,那就是多人使用共享顯示卡的話容易導緻一方一直不釋放顯存而另一方無法獲得足夠顯存,當然pytorch也給出了一些顯存配置設定的配置方法,但是主要還是為了減少顯存碎片的。
對 https://zhuanlan.zhihu.com/p/424512257 中代碼進行一定修改:
import torch
s = 0
# 模型初始化
linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # + 4194304
s = s+4194304
print(torch.cuda.memory_allocated(), s)
linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # + 4096
s+=4096
print(torch.cuda.memory_allocated(), s)
# 輸入定義
inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304
s+=4194304
print(torch.cuda.memory_allocated(), s)
# 前向傳播
s=s+4194304+512
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512
print(torch.cuda.memory_allocated(), s)
# 後向傳播
loss.backward() # memory - 4194304 + 4194304 + 4096
s = s-4194304+4194304+4096
print(torch.cuda.memory_allocated(), s)
# 再來一次~
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512沒了,因為loss的ref還在)
s+=4194304
print(torch.cuda.memory_allocated(), s)
loss.backward() # memory - 4194304
s-=4194304
print(torch.cuda.memory_allocated(), s) ============================================
=================================================
修改代碼:
import torch
s = 0
# 模型初始化
linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # + 4194304
s = s+4194304
print(torch.cuda.memory_allocated(), s)
linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # + 4096
s+=4096
print(torch.cuda.memory_allocated(), s)
# 輸入定義
inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304
s+=4194304
print(torch.cuda.memory_allocated(), s)
# 前向傳播
s=s+4194304+512
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512
print(torch.cuda.memory_allocated(), s)
# 後向傳播
loss.backward() # memory - 4194304 + 4194304 + 4096
s = s-4194304+4194304+4096
print(torch.cuda.memory_allocated(), s)
# 再來一次~
for _ in range(10000):
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512沒了,因為loss的ref還在)
loss.backward() # memory - 4194304
print(torch.cuda.max_memory_reserved()/1024/1024, "MB")
print(torch.cuda.max_memory_allocated()/1024/1024, "MB")
print(torch.cuda.max_memory_cached()/1024/1024, "MB")
print(torch.cuda.memory_summary()) View Code
那麼問題來了,問了保證這個程式完整運作下來的顯存量是多少呢???
已經知道最大的reserved_memory 為 22MB,那麼保證該程式運作的最大顯存空間為reserved_memory+context_memory,
這裡我們是使用1060G顯示卡運作,先對一下context_memory:
執行代碼:
import torch
temp = torch.tensor([1.0]).cuda() NVIDIA顯存消耗:
是以context_memory為681MB-2MB=679MB
由于max_reserved_memory=22MB,是以該程式完整運作下來最高需要679+22=701MB,驗證一下:
再次運作代碼:
import torch
import time
s = 0
# 模型初始化
linear1 = torch.nn.Linear(1024,1024, bias=False).cuda() # + 4194304
s = s+4194304
print(torch.cuda.memory_allocated(), s)
linear2 = torch.nn.Linear(1024, 1, bias=False).cuda() # + 4096
s+=4096
print(torch.cuda.memory_allocated(), s)
# 輸入定義
inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304
s+=4194304
print(torch.cuda.memory_allocated(), s)
# 前向傳播
s=s+4194304+512
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512
print(torch.cuda.memory_allocated(), s)
# 後向傳播
loss.backward() # memory - 4194304 + 4194304 + 4096
s = s-4194304+4194304+4096
print(torch.cuda.memory_allocated(), s)
# 再來一次~
for _ in range(10000):
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512沒了,因為loss的ref還在)
loss.backward() # memory - 4194304
print(torch.cuda.max_memory_reserved()/1024/1024, "MB")
print(torch.cuda.max_memory_allocated()/1024/1024, "MB")
print(torch.cuda.max_memory_cached()/1024/1024, "MB")
print(torch.cuda.memory_summary())
time.sleep(60) View Code
發現 803-701=102MB,這中間差的數值無法解釋,隻能說memory_context可以随着程式不同數值也不同,不同程式引入的pytorch函數不同導緻context_memory也不同,這裡我們按照這個想法反推,context_memory在這裡為803-22=781MB,為了驗證我們修改代碼:
修改代碼:
import torch
import time
s = 0
# 模型初始化
linear1 = torch.nn.Linear(1024,1024*2, bias=False).cuda() # + 4194304
s = s+4194304
print(torch.cuda.memory_allocated(), s)
linear2 = torch.nn.Linear(1024*2, 1, bias=False).cuda() # + 4096
s+=4096
print(torch.cuda.memory_allocated(), s)
# 輸入定義
inputs = torch.tensor([[1.0]*1024]*1024).cuda() # shape = (1024,1024) # + 4194304
s+=4194304
print(torch.cuda.memory_allocated(), s)
# 前向傳播
s=s+4194304+512
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 + 512
print(torch.cuda.memory_allocated(), s)
# 後向傳播
loss.backward() # memory - 4194304 + 4194304 + 4096
s = s-4194304+4194304+4096
print(torch.cuda.memory_allocated(), s)
# 再來一次~
for _ in range(100):
loss = sum(linear2(linear1(inputs))) # shape = (1) # memory + 4194304 (512沒了,因為loss的ref還在)
loss.backward() # memory - 4194304
print(torch.cuda.max_memory_reserved()/1024/1024, "MB")
print(torch.cuda.max_memory_allocated()/1024/1024, "MB")
print(torch.cuda.max_memory_cached()/1024/1024, "MB")
print(torch.cuda.memory_summary())
time.sleep(60) View Code
運作結果:
那麼該代碼完整運作需要的顯存空間為:781+42=823MB
參考NVIDIA顯示卡的顯存消耗:
發現支援剛才的猜想,也就是說不同的pytorch函數,顯示卡型号,驅動,作業系統,cuda版本都是會影響context_memory大小的。
其中最為難以測定的就是pytorch函數,因為你可能一直在同一個平台上跑代碼但是不太可能一直都用相同的pytorch函數,是以一個程式跑完最低需要的顯存空間的測定其實是需要完整跑一次網絡的反傳才可以測定的。
我這裡采用的測定最低需要的顯存空間的方法是不考慮context_memory而去直接考慮一次反傳後最大需要的顯存,此時我們可以一次反傳後把程式挂住,如sleep一下,然後看下NVIDIA顯示卡一共消耗了多少顯存。而且由上面的資訊可知context_memory的測定是與具體使用的函數相關的,是以最穩妥的方法就是使用NVIDIA-smi監測一次完整反傳後最大顯存的消耗。