
本文從常見的推薦系統方法(基于内容、協同過濾等近鄰算法、基于知識等)講起,一直覆寫到前沿的新式推薦系統,不僅詳細講解原理,還手把手教大家如何用代碼實作。

💡 作者:韓信子@ShowMeAI
📘 深度學習實戰系列:https://www.showmeai.tech/tutorials/42
📘 TensorFlow 實戰系列:https://www.showmeai.tech/tutorials/43
📘 本文位址:https://www.showmeai.tech/article-detail/310
📢 聲明:版權所有,轉載請聯系平台與作者并注明出處
📢 收藏ShowMeAI檢視更多精彩内容
推薦系統是預測使用者對多種産品的偏好的模型,網際網路時代,它在各種領域大放異彩,從視訊音樂多媒體推薦、到電商購物推薦、社交關系推薦,無處不在地提升使用者體驗。
最常見的推薦系統方法包括:基于産品特征(基于内容)、使用者相似性(協同過濾等近鄰算法)、個人資訊(基于知識)。當然,随着神經網絡的日益普及,很多公司的業務中使用到的推薦算法已經是上述所有方法結合的混合推薦系統。
在本篇内容中,ShowMeAI 将給大家一一道來,從傳統推薦系統算法到前沿的新式推薦系統,講解原理并手把手教大家如何用代碼實作。
本篇内容使用到的 🏆MovieLens 電影推薦資料集,大家可以在 ShowMeAI 的百度網盤位址下載下傳。
🏆 實戰資料集下載下傳(百度網盤):公衆号『ShowMeAI研究中心』回複『實戰』,或者點選 這裡 擷取本文 [19]基于TensorFlow搭建混合神經網絡推薦系統 『MovieLens 電影推薦資料集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub
資料集包含觀衆對電影的評分結果,有不同規模的資料集大小,我們本篇内容中的代碼通用,大家可以根據自己的計算資源情況選擇合适的資料集。
- 小資料集為 600 名觀衆對 9000部電影的 10w 個打分,也包括電影标簽特征。
- 大資料集為 280000 名觀衆對 110w 部電影的 2700w 評分。
本文涉及的内容闆塊如下:
- 基本設定&資料預處理
- 冷啟動問題&處理
- 基于内容的方法(tensorflow 和 numpy實作)
- 傳統協同過濾和神經協同過濾模型(tensorflow/keras 實作)
- 混合模型模型(上下文感覺,tensorflow/keras 實作)
💡 基本設定&資料預處理
📌 工具庫導入
首先,我們導入所需工具庫:
# 資料讀取與處理
import pandas as pd
import numpy as np
import re
from datetime import datetime
# 繪圖
import matplotlib.pyplot as plt
import seaborn as sns
# 評估與預處理
from sklearn import metrics, preprocessing
# 深度學習
from tensorflow.keras import models, layers, utils #(2.6.0)
📌 讀取資料
接下來我們讀取資料。
dtf_products = pd.read_csv("movie.csv")
movie電影檔案中,每一行代表一部電影,右側的兩列包含其特征(标題與題材)。讓我們讀取使用者資料:
dtf_users = pd.read_csv("ratings.csv").head(10000)
這個ratings表的每一行都是觀衆電影對,并顯示觀衆對電影的評分(即目标變量)。當然啦,并不是每個觀衆都看過所有的電影,是以我們可以給他們推薦沒有看過的電影。這裡的一種思路就是預估觀衆對于沒有看過的電影的評分,再基于評分高低進行推薦。
📌 資料分析&特征工程
在實際挖掘與模組化之前,我們先做一些資料清理和特征工程的工作,讓資料更幹淨和适合模組化使用。
資料分析部分涉及的工具庫,大家可以參考ShowMeAI制作的工具庫速查表和教程進行學習和快速使用。
📘資料科學工具庫速查表 | Pandas 速查表
📘圖解資料分析:從入門到精通系列教程
# 電影資料處理
# 題材字段缺失處理
dtf_products = dtf_products[~dtf_products["genres"].isna()]
dtf_products["product"] = range(0,len(dtf_products))
# 電影名稱處理
dtf_products["name"] = dtf_products["title"].apply(lambda x: re.sub("[([].*?[)]]", "", x).strip())
# 日期
dtf_products["date"] = dtf_products["title"].apply(lambda x: int(x.split("(")[-1].replace(")","").strip())
if "(" in x else np.nan)
dtf_products["date"] = dtf_products["date"].fillna(9999)
# 判斷老電影
dtf_products["old"] = dtf_products["date"].apply(lambda x: 1 if x < 2000 else 0)
# 觀衆/使用者資料處理
dtf_users["user"] = dtf_users["userId"].apply(lambda x: x-1)
dtf_users["timestamp"] = dtf_users["timestamp"].apply(lambda x: datetime.fromtimestamp(x))
# 白天時段
dtf_users["daytime"] = dtf_users["timestamp"].apply(lambda x: 1 if 6<int(x.strftime("%H"))<20 else 0)
# 周末
dtf_users["weekend"] = dtf_users["timestamp"].apply(lambda x: 1 if x.weekday() in [5,6] else 0)
# 電影與使用者表合并
dtf_users = dtf_users.merge(dtf_products[["movieId","product"]], how="left")
dtf_users = dtf_users.rename(columns={"rating":"y"})
# 清洗資料
dtf_products = dtf_products[["product","name","old","genres"]].set_index("product")
dtf_users = dtf_users[["user","product","daytime","weekend","y"]]
上述過程中有一些很貼合場景的特征工程和資料生成工作,比如我們從時間戳中生成了2個新的字段: 『是否白天』 和 『是否周末』 。
dtf_context = dtf_users[["user","product","daytime","weekend"]]
下一步我們建構 Moives-Features 矩陣:
# 電影題材候選統計
tags = [i.split("|") for i in dtf_products["genres"].unique()]
columns = list(set([i for lst in tags for i in lst]))
columns.remove('(no genres listed)')
# 題材可能有多個,切分出來作為标簽
for col in columns:
dtf_products[col] = dtf_products["genres"].apply(lambda x: 1 if col in x else 0)
我們得到的這個『電影-題材』矩陣是稀疏的(很好了解,一般一部電影隻歸屬于有限的幾個題材)。我們做一點可視化以更好地了解情況,代碼如下:
# 建構熱力圖并可視化
fig, ax = plt.subplots(figsize=(20,5))
sns.heatmap(dtf_products==0, vmin=0, vmax=1, cbar=False, ax=ax).set_title("Products x Features")
plt.show()
下面是我們的 『觀衆/使用者-電影』 評分矩陣,我們發現它更為稀疏(每位使用者實際隻看過幾部電影,但總電影量很大)
tmp = dtf_users.copy()
dtf_users = tmp.pivot_table(index="user", columns="product", values="y")
missing_cols = list(set(dtf_products.index) - set(dtf_users.columns))
for col in missing_cols:
dtf_users[col] = np.nan
dtf_users = dtf_users[sorted(dtf_users.columns)]
同樣的熱力圖結果如下:
在特征工程部分,我們需要做一些典型的資料預處理過程,比如我們會在後續用到神經網絡模型,而這種計算型模型,我們對資料做幅度縮放是非常必要的。
關于機器學習特征工程,大家可以參考 ShowMeAI 整理的特征工程最全解讀教程。
📘機器學習實戰 | 機器學習特征工程最全解讀
# 資料幅度縮放
dtf_users = pd.DataFrame(preprocessing.MinMaxScaler(feature_range=(0.5,1)).fit_transform(dtf_users.values),
columns=dtf_users.columns, index=dtf_users.index)
📌 資料切分
簡單處理完資料之後,就像任何典型的機器學習任務一樣,我們需要對資料進行劃分,在這裡劃分為訓練集和測試集。如果結合上述『使用者-電影』矩陣,我們會做類似下圖的垂直切分,這樣訓練集和測試集都會盡量覆寫所有使用者:
# 資料切分
split = int(0.8*dtf_users.shape[1])
dtf_train = dtf_users.loc[:, :split-1]
dtf_test = dtf_users.loc[:, split:]
💡 冷啟動問題&處理
📌 冷啟動問題
想象一下,類似于『抖音』這樣的應用,對于新使用者提供推薦,其實是不太準确的(隻能基于一些政策,如熱度排行等進行推薦),我們對使用者的資訊積累太少,使用者畫像的工作無法進行。這就是任何一個推薦系統産品都會遇到的冷啟動問題(即因為沒有足夠的曆史資料,系統無法在使用者和産品之間建立任何關聯)。
📌 冷啟動處理方法
針對冷啟動問題,有一些典型的處理方式,例如基于知識的方法:在初次進入APP時詢問使用者的偏好,建構基本資訊與知識,再基于知識進行推薦(比如不同『年齡段』和『性别』喜愛的媒體産品等)。
另外一種處理方法是基于内容的方法。即基于産品的屬性(比如我們目前的場景下,電影的題材、演員、主題等)進行比對推薦。
💡 基于内容的推薦方法
📌 核心思想
我們來介紹一下基于内容的方法。
這個方法是基于産品屬性進行關聯和推薦的,例如,如果『使用者A喜歡産品1』,并且『産品2與産品1從屬性上看相似』,那麼『使用者A可能也會喜歡産品2』。簡單地說,這個想法是『使用者實際上對産品的功能/屬性而不是産品本身進行評分』。
換句話說,如果我喜歡與音樂和藝術相關的産品,那是因為我喜歡那些功能/屬性(音樂和藝術)。我們可以基于這個資訊做推薦。
| 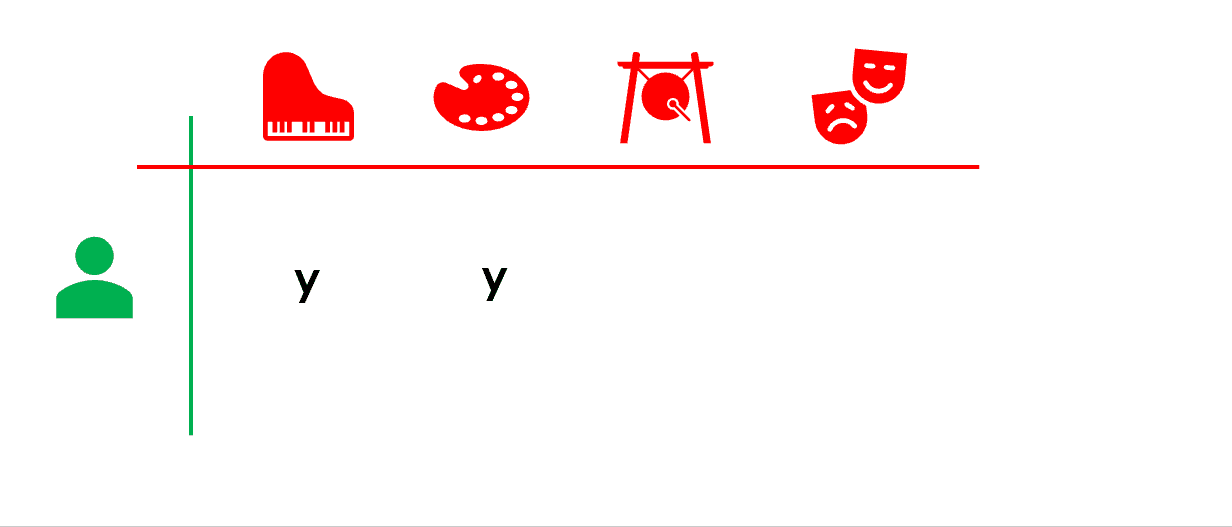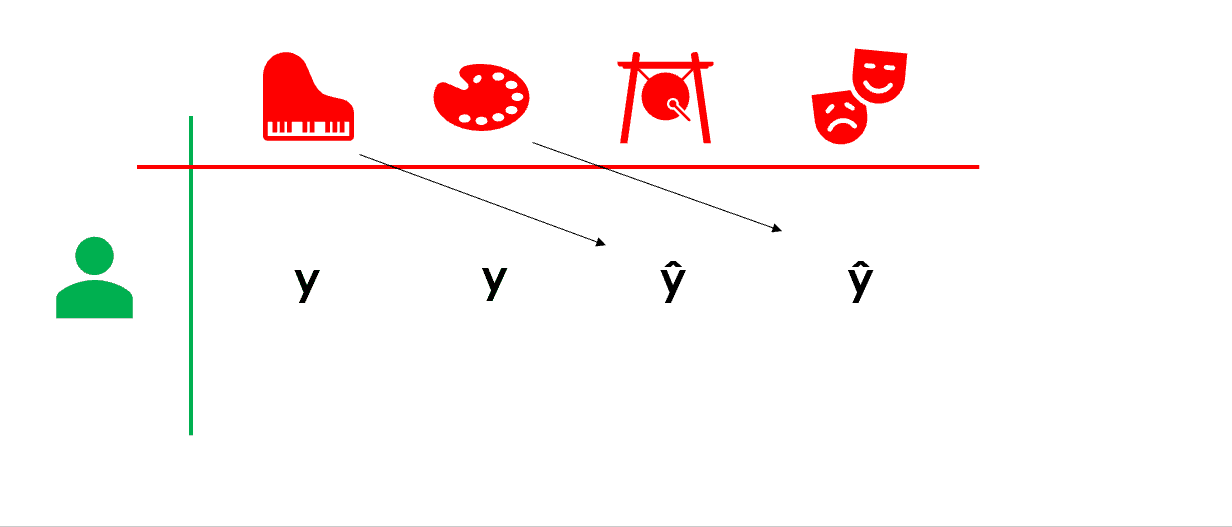 |
📌 代碼實作
我們随機從資料中挑選一個『觀衆/使用者』作為我們的新使用者的示例,該訂閱者現在已經使用了足夠多的産品,讓我們建立訓練和測試向量。
# 選一個user
i = 1
train = dtf_train.iloc[i].to_frame(name="y")
test = dtf_test.iloc[i].to_frame(name="y")
# 把所有測試集的電影評厘清空後拼接
tmp = test.copy()
tmp["y"] = np.nan
train = train.append(tmp)
下面我們估測『觀衆/使用者』對每個特征的權重,回到我們前面整理完的 User-Products 矩陣和 Products-Features 矩陣。
# 資料次元
usr = train[["y"]].fillna(0).values.T
prd = dtf_products.drop(["name","genres"],axis=1).values
print("Users", usr.shape, " x Products", prd.shape)
我們把這 2 個矩陣相乘,我們獲得了一個『使用者-特征』矩陣,它包含這個使用者對每個特征的估計權重。我們進而把這些權重應重新應用于『産品-特征』矩陣就可以獲得測試集結果。
# usr_ft(users,fatures) = usr(users,products) x prd(products,features)
usr_ft = np.dot(usr, prd)
# 歸一化
weights = usr_ft / usr_ft.sum()
# 預估打分 rating(users,products) = weights(users,fatures) x prd.T(features,products)
pred = np.dot(weights, prd.T)
test = test.merge(pd.DataFrame(pred[0], columns=["yhat"]), how="left", left_index=True, right_index=True).reset_index()
test = test[~test["y"].isna()]
test
上面是一個非常非常簡單的思路,我們用 numpy 對它進行了實作。其實這個過程也可以在原始資料張量上進行:
# 基于tensorflow更高效的實作
import tensorflow as tf
# usr_ft(users,fatures) = usr(users,products) x prd(products,features)
usr_ft = tf.matmul(usr, prd)
# normalize
weights = usr_ft / tf.reduce_sum(usr_ft, axis=1, keepdims=True)
# rating(users,products) = weights(users,fatures) x prd.T(features,products)
pred = tf.matmul(weights, prd.T)
僅僅完成預估步驟還不夠,我們需要對預測推薦進行有效評估,怎麼做呢,在目前這個推薦場景下,我們可以使用準确性和平均倒數排名(MRR,一種針對排序效果的統計度量)。
# 評估名額
def mean_reciprocal_rank(y_test, predicted):
score = []
for product in y_test:
mrr = 1 / (list(predicted).index(product) + 1) if product
in predicted else 0
score.append(mrr)
return np.mean(score)
有時候,在全部排序結果清單上評估,效果一般且計算量太大,我們可以選擇标準答案的 top k 進行評估(下面代碼中 k 取值為 5)。
print("--- user", i, "---")
top = 5
y_test = test.sort_values("y", ascending=False)["product"].values[:top]
print("y_test:", y_test)
predicted = test.sort_values("yhat", ascending=False)["product"].values[:top]
print("predicted:", predicted)
true_positive = len(list(set(y_test) & set(predicted)))
print("true positive:", true_positive, "("+str(round(true_positive/top*100,1))+"%)")
print("accuracy:", str(round(metrics.accuracy_score(y_test,predicted)*100,1))+"%")
print("mrr:", mean_reciprocal_rank(y_test, predicted))
上圖顯示在 user1 上,我們預估結果和 top5 真實結果,有 4 個結果是重疊的。(不過因為我們預估結果的序并不完全和标準答案一樣,是以名額上看 accuracy 和 mrr 會低一點)
# 檢視預估結果細節
test.merge(
dtf_products[["name","old","genres"]], left_on="product",
right_index=True
).sort_values("yhat", ascending=False)
💡 協同過濾推薦算法
📌 核心思想
協同過濾是一類典型的『近鄰』推薦算法,基于使用者和使用者的相似性,或者産品和産品的相似性來建構推薦。比如 user-based collaborative filtering(基于使用者的協同過濾)中,我們認為『使用者A喜歡産品1』,而基于使用者行為計算判定『使用者B和使用者A相似』,那麼『使用者B可能也會喜歡産品1』。
注意到協同過濾算法中,很重要的步驟是我們需要基于使用者曆史的行為來建構相似度度量(user-user 或 item-item 相似度)。
| 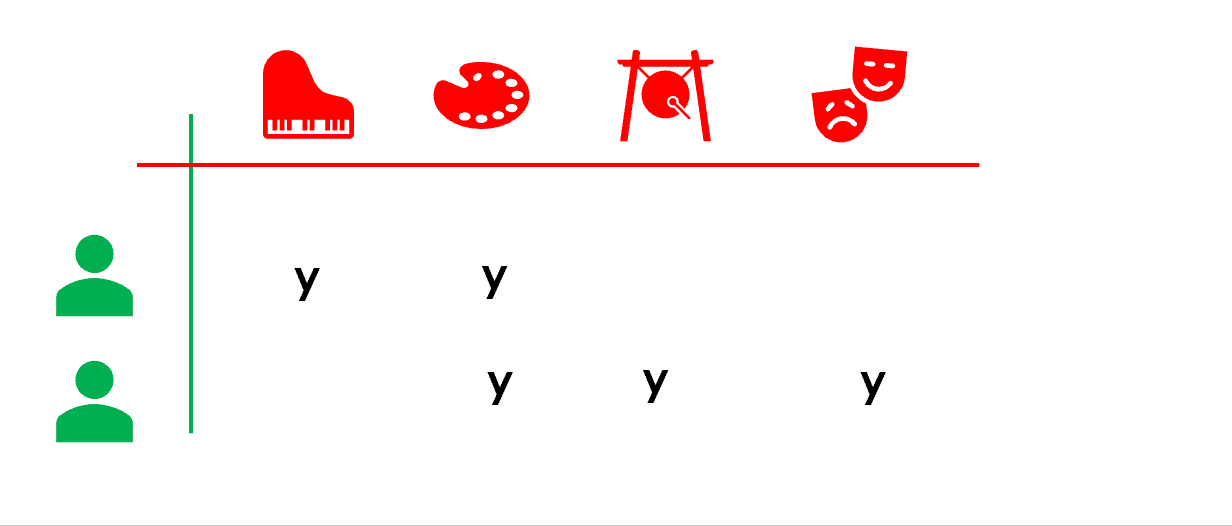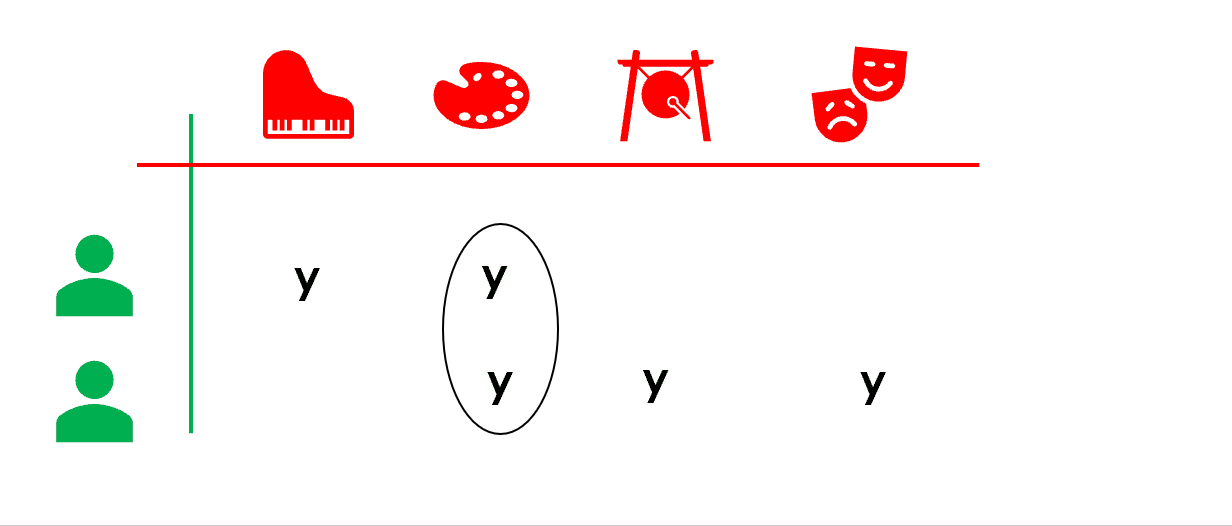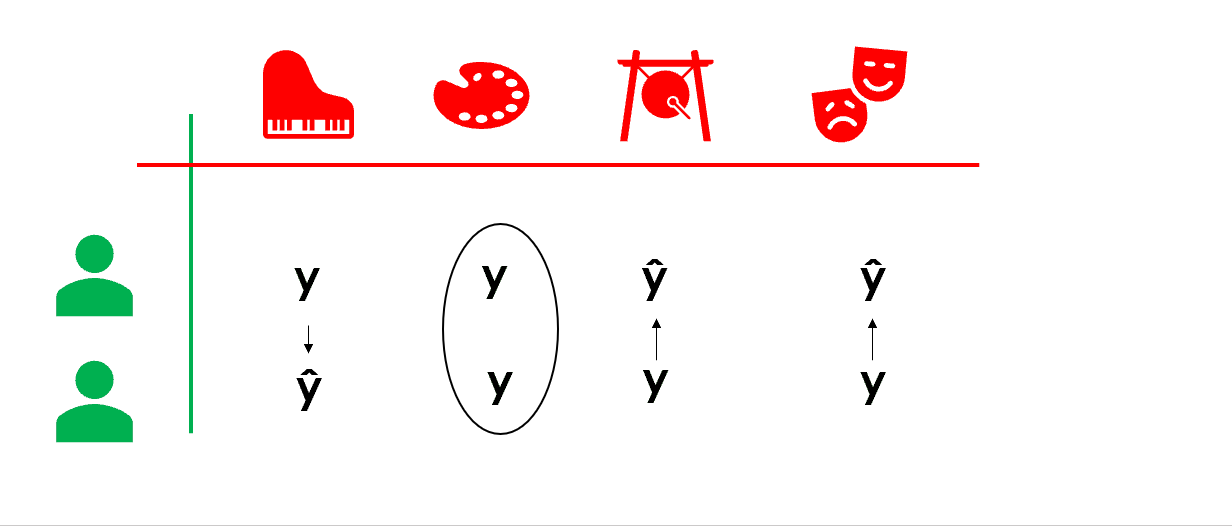 |
協同過濾和上面提到的基于内容的推薦算法不同,我們不需要産品屬性來模組化,而是基于大量使用者的曆史行為來計算和建構相似度量(例如在本例中,我們可以基于不同的觀衆曆史上在一批電影上的評分相似度來建構)。
📌 基礎協同過濾算法
協同過濾是『基于使用者行為』的推薦算法,我們會『通過群體的行為來找到某種相似性』(使用者之間的相似性或者物品之間的相似性),通過相似性來為使用者做決策和推薦。協同過濾細分一下,有以下基于鄰域的、基于隐語義模型2大類方法。
基于近鄰的協同過濾
基于近鄰的協同過濾包含 user-based cf(基于使用者的協同過濾)和 item-based cf(基于物品的協同過濾)兩種方式,核心思想如下圖所示:
核心步驟為以下3步:
① 根據曆史資料收集使用者偏好(比如本例中的打分,比如)。
② 找到相似的使用者(基于使用者)或物品(基于物品)。
③ 基于相似性計算和推薦。
其中的 similarity 相似度計算部分,可以基于一些度量準則來完成,比如最常用到的相似度度量是餘弦相似度:
\[\text{cosine similarity}=S_{C}(A, B):=\cos (\theta)=\frac{A \cdot \mathbf{B}}{\|\mathbf{A}\|\|\mathbf{B}\|}=\frac{\sum_{i=1}^{n} A_{i} B_{i}}{\sqrt{\sum_{i=1}^{n} A_{i}^{2} \sqrt{\sum_{i=1}^{n} B_{i}^{2}}}}
\]
在本例中A和B可以是兩個使用者的共同電影對應的打分向量,或者兩部電影的共同打分使用者的打分向量,也就是打分矩陣中的兩行或者兩列。
當然,我們也可以基于聚類等其他方法來發現相似使用者和物品。
基于隐語義模型的協同過濾
協同過濾的另外一種實作,是基于矩陣分解的方法,在本例中通過這個方法可以預測使用者對某個産品的評價,矩陣分解方法将大的『使用者-物品 』打分矩陣分成兩個較小的因子矩陣,分别是『使用者-因子』矩陣和『産品-因子』矩陣,再基于這兩個矩陣對于未打分的『使用者-物品』對打分。
具體來說,每個因子可能代表某一個屬性次元的程度,如下如,我們如果确定2個屬性『年齡段』『題材娛樂性』,那我們可以基于打分矩陣對這兩個次元進行分解。
代碼實作
在 Python 中,要實作上述提到的2類協同過濾算法,最友善的工具庫之一是 📘scikit-surprise(從名字大家可以看出,它借助了 scikit-learn 的一些底層算法來實作上層的協同過濾)。它包含了上述提到的基于近鄰的協同過濾和基于隐語義模型的協同過濾。
不過矩陣實作方法也是各種深度學習模型所擅長的,我們在這裡使用tensorflow/keras來做一點實作。
我們先準備好『使用者-物品』資料(本例中的使用者是觀衆,物品是電影):
train = dtf_train.stack(dropna=True).reset_index().rename(columns={0:"y"})
train.head()
我們會利用神經網絡的嵌入層來建立『使用者-因子』和『産品-因子』矩陣,這裡特别适合用神經網絡的 embedding 層來完成映射矩陣建構,我們為使用者和産品分别建構 embedding 矩陣。Embedding 矩陣的次元就是我們這個地方設定的因子的個數。下面我們使用 tensorflow 來完成這個過程。
embeddings_size = 50
usr, prd = dtf_users.shape[0], dtf_users.shape[1]
# 使用者 Users 次元(1,embedding_size)
xusers_in = layers.Input(name="xusers_in", shape=(1,))
xusers_emb = layers.Embedding(name="xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
xusers = layers.Reshape(name='xusers', target_shape=(embeddings_size,))(xusers_emb)
# 産品 Products 次元(1,embedding_size)
xproducts_in = layers.Input(name="xproducts_in", shape=(1,))
xproducts_emb = layers.Embedding(name="xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
xproducts = layers.Reshape(name='xproducts', target_shape=(embeddings_size,))(xproducts_emb)
# 矩陣乘法,即我們我們上面提到的因子矩陣相乘 次元(1)
xx = layers.Dot(name='xx', normalize=True, axes=1)([xusers, xproducts])
# 預測得分 次元(1)
y_out = layers.Dense(name="y_out", units=1, activation='linear')(xx)
# 編譯
model = models.Model(inputs=[xusers_in,xproducts_in], outputs=y_out, name="CollaborativeFiltering")
model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])
在本例中呢,因為我們最終是對電影的評分去做預測,是以我們把這個問題視作一個回歸的問題使用模型來解決,我們會使用平均絕對誤差作為最終的損失函數。當然我們實際在解決推薦這個問題的時候,可能并不需要得到精确的得分,而是希望基于這些得分去完成一個排序和最終的推薦。
我們把建構出來的模型示意圖和中間層的次元列印一下,友善大家檢視,如下
utils.plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)
接下來我們就可以在我們的資料上去訓練、評估和測試我們的模型了。
# 訓練
training = model.fit(x=[train["user"], train["product"]], y=train["y"], epochs=100, batch_size=128, shuffle=True, verbose=0, validation_split=0.3)
model = training.model
# 測試
test["yhat"] = model.predict([test["user"], test["product"]])
test
在這個模型最終的預估結果上,大家可以看到模型已經能夠對沒有見過的新的電影進行打分的預測了。我們可以基于這個得分進行排序和完成最終的推薦。以我們第1個使用者為例,我們可以看到對于他進行基于預測得分的推薦,評估結果如下。
📌 神經協同過濾算法
模型介紹
大家在前面看到的協同過濾模型,學習能力相對比較弱,對于我們的資訊做的是初步的挖掘,而現代的很多新的推薦系統實際上都使用了深度學習。也可以把深度學習和協同過濾結合,例如 Neural Collaborative Filtering (2017) 結合了來自神經網絡的非線性和矩陣分解。該模型旨在充分利用嵌入空間,不僅将其用于傳統的協同過濾,還用于完全連接配接的深度神經網絡,新添加的模型組成部分會捕獲矩陣分解可能遺漏的模式和特征,如下圖所示:
代碼實作
下面我們來實作一下這個模型的一個簡易版本:
# 使用者與産品的embedding次元,相當于協同過濾中的因子數
embeddings_size = 50
usr, prd = dtf_users.shape[0], dtf_users.shape[1]
# 輸入層
xusers_in = layers.Input(name="xusers_in", shape=(1,))
xproducts_in = layers.Input(name="xproducts_in", shape=(1,))
# A) 模型左側:Matrix Factorization 矩陣分解
# embeddings 與 reshape
cf_xusers_emb = layers.Embedding(name="cf_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
cf_xusers = layers.Reshape(name='cf_xusers', target_shape=(embeddings_size,))(cf_xusers_emb)
# embeddings 與 reshape
cf_xproducts_emb = layers.Embedding(name="cf_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
cf_xproducts = layers.Reshape(name='cf_xproducts', target_shape=(embeddings_size,))(cf_xproducts_emb)
# 産品 product
cf_xx = layers.Dot(name='cf_xx', normalize=True, axes=1)([cf_xusers, cf_xproducts])
# B) 模型右側:Neural Network 神經網絡
# embeddings 與 reshape
nn_xusers_emb = layers.Embedding(name="nn_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
nn_xusers = layers.Reshape(name='nn_xusers', target_shape=(embeddings_size,))(nn_xusers_emb)
# embeddings 與 reshape
nn_xproducts_emb = layers.Embedding(name="nn_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
nn_xproducts = layers.Reshape(name='nn_xproducts', target_shape=(embeddings_size,))(nn_xproducts_emb)
# 拼接與全連接配接處理
nn_xx = layers.Concatenate()([nn_xusers, nn_xproducts])
nn_xx = layers.Dense(name="nn_xx", units=int(embeddings_size/2), activation='relu')(nn_xx)
# 合并A和B
y_out = layers.Concatenate()([cf_xx, nn_xx])
y_out = layers.Dense(name="y_out", units=1, activation='linear')(y_out)
# 編譯
model = models.Model(inputs=[xusers_in,xproducts_in], outputs=y_out, name="Neural_CollaborativeFiltering")
model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])
我們也同樣可以對模型進行結構的繪制,如下所示。
utils.plot_model(model, to_file=’model.png’, show_shapes=True, show_layer_names=True)
我們再基于現在這個神經網絡的模型,去對我們最終的電影打評分進行預測,并且根據預測的得分進行排序和推薦,那評估的結果如下所示。
💡 混合網絡模型
📌 模型介紹
我們在前面展示了如何結合我們的使用者和産品(在目前場景下是電影推薦的場景)的打分資料來建構協同過濾算法和基礎的神經網絡算法,完成最終打分的預測和推薦,但實際我們的資料當中有着更豐富的資訊。
- 使用者行為 : 目前場景下是電影的打分,它是一種顯式使用者回報;有些場景下我們會使用隐式的使用者回報,比如說使用者的點選或者深度浏覽和完播等行為。
- 産品資訊 : 産品的标簽和描述(這裡的電影題材、标題等),主要用于基于内容的方法。
- 使用者資訊 : 人口統計學資訊(即性别和年齡)或行為(即偏好、螢幕上的平均時間、最頻繁的使用時間),主要用于基于知識的推薦。
- 上下文 : 關于評分情況的附加資訊(如何時、何地、搜尋曆史),通常也包含在基于知識的推薦中。
現代推薦系統為了更精準的給大家進行推薦,會盡量的結合所有我們能夠收集到的資訊。大家日常使用的抖音或者B站,它們在給大家推薦視訊類的内容的時候,會更加全面的使用我們上面提及到的所有的資訊,甚至包含APP能采集到的更豐富的資訊。
📌 代碼實作
下面結合本例,我們也把這些更豐富的資訊(主要是上下文資訊)結合到網絡中來建構一個混合模型,以完成更精準的預估和推薦。
# 基礎特征
features = dtf_products.drop(["genres","name"], axis=1).columns
print(features)
# 上下文特征(時間段、工作日、周末等)
context = dtf_context.drop(["user","product"], axis=1).columns
print(context)
基礎特征和上下文特征如下
接下來我們把這些額外資訊添加到訓練集中:
train = dtf_train.stack(dropna=True).reset_index().rename(columns={0:"y"})
# 添加特征
train = train.merge(dtf_products[features], how="left", left_on="product", right_index=True)
# 添加上下文資訊
train = train.merge(dtf_context, how="left")
注意我們這裡并沒有對測試集直接去執行相同的操作,因為實際的生産環境當中,我們可能沒有辦法提前的去獲知一些上下文的資訊,是以我們會為上下文的資訊去插入一個靜态的值去做填充。
當然我們在實際預估的時候,是可以比較準确的去做填充的。比如我們在星期一晚上為我們平台的使用者進行預測,則上下文變量應為
和daytime=0
。week=0
下面我們來建構上下文感覺混合模型,神經網絡的結構非常靈活,我們可以在網絡中添加任何我們想要補充的資訊,我們把上下文等額外資訊也通過網絡元件的形式補充到神經協同過濾網絡結構中,如下所示。
這個過程就相當于在剛才的神經協同過濾模型基礎上,添加一些新的組塊。下列實作代碼看起來比較龐大,但實際上它隻是在之前的實作基礎上添加了一些行而已:
embeddings_size = 50
usr, prd = dtf_users.shape[0], dtf_users.shape[1]
feat = len(features)
ctx = len(context)
################## 神經協同過濾 ########################
# 輸入層
xusers_in = layers.Input(name="xusers_in", shape=(1,))
xproducts_in = layers.Input(name="xproducts_in", shape=(1,))
# A) 模型左側:Matrix Factorization 矩陣分解
# embeddings 與 reshape
cf_xusers_emb = layers.Embedding(name="cf_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
cf_xusers = layers.Reshape(name='cf_xusers', target_shape=(embeddings_size,))(cf_xusers_emb)
# embeddings 與 reshape
cf_xproducts_emb = layers.Embedding(name="cf_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
cf_xproducts = layers.Reshape(name='cf_xproducts', target_shape=(embeddings_size,))(cf_xproducts_emb)
# 産品 product
cf_xx = layers.Dot(name='cf_xx', normalize=True, axes=1)([cf_xusers, cf_xproducts])
# B) 模型右側:Neural Network 神經網絡
# embeddings 與 reshape
nn_xusers_emb = layers.Embedding(name="nn_xusers_emb", input_dim=usr, output_dim=embeddings_size)(xusers_in)
nn_xusers = layers.Reshape(name='nn_xusers', target_shape=(embeddings_size,))(nn_xusers_emb)
# embeddings 與 reshape
nn_xproducts_emb = layers.Embedding(name="nn_xproducts_emb", input_dim=prd, output_dim=embeddings_size)(xproducts_in)
nn_xproducts = layers.Reshape(name='nn_xproducts', target_shape=(embeddings_size,))(nn_xproducts_emb)
# 拼接與全連接配接處理
nn_xx = layers.Concatenate()([nn_xusers, nn_xproducts])
nn_xx = layers.Dense(name="nn_xx", units=int(embeddings_size/2), activation='relu')(nn_xx)
######################## 基礎資訊 ############################
# 電影特征
features_in = layers.Input(name="features_in", shape=(feat,))
features_x = layers.Dense(name="features_x", units=feat, activation='relu')(features_in)
####################### 上下文特征 ###########################
# 上下文特征
contexts_in = layers.Input(name="contexts_in", shape=(ctx,))
context_x = layers.Dense(name="context_x", units=ctx, activation='relu')(contexts_in)
######################### 輸出 ##################################
# 合并所有資訊
y_out = layers.Concatenate()([cf_xx, nn_xx, features_x, context_x])
y_out = layers.Dense(name="y_out", units=1, activation='linear')(y_out)
# 編譯
model = models.Model(inputs=[xusers_in,xproducts_in, features_in, contexts_in], outputs=y_out, name="Hybrid_Model")
model.compile(optimizer='adam', loss='mean_absolute_error', metrics=['mean_absolute_percentage_error'])
我們也繪制一下整個模型的結構
utils.plot_model(model, to_file='model.png', show_shapes=True, show_layer_names=True)
混合模型的輸入資料源更多,實際訓練時我們要把這些資料都送入模型:
# 訓練
training = model.fit(x=[train["user"], train["product"], train[features], train[context]], y=train["y"],
epochs=100, batch_size=128, shuffle=True, verbose=0, validation_split=0.3)
model = training.model
# 預測
test["yhat"] = model.predict([test["user"], test["product"], test[features], test[context]])
最終基于混合模型的預測得分進行推薦,評估名額如下:
我們單獨看 user1 這個使用者,混合模型在多種資訊的支撐下,獲得了最高的準确度。
💡 結論
本文講解了推薦系統的基礎知識,以及不同的推薦系統搭建方法,我們對各種方法進行了實作和效果改進,包括基于内容的推薦實作,基于協同過濾的推薦實作,我們把更豐富的産品資訊和上下文資訊加入網絡實作了混合網絡模型。大家可以參考實作流程應用在自己的場景中。
參考資料
- 📘 資料科學工具庫速查表 | Pandas 速查表:https://www.showmeai.tech/article-detail/101
- 📘 圖解資料分析:從入門到精通系列教程:https://www.showmeai.tech/tutorials/33
- 📘 機器學習實戰 | 機器學習特征工程最全解讀:https://www.showmeai.tech/article-detail/208
- 📘 scikit-surprise:https://pypi.org/project/scikit-surprise/