摘要:
我們解決了在許多裝置和資源限制(尤其是在邊緣裝置)上進行有效推理的挑戰性問題。正常方法要麼手動設計,要麼使用神經體系結構搜尋(NAS)來找到專門的神經網絡,并針對每種情況從頭開始對其進行訓練,這在計算上是禁止的(導緻CO2排放量長達5輛汽車的使用壽命),是以無法擴充。在這項工作中,我們建議通過分離訓練和搜尋來訓練一個支援所有人的(OFA)網絡,以支援各種體系結構設定,以降低成本。通過從OFA網絡中進行選擇,我們可以快速獲得專門的子網,而無需額外的教育訓練。為了有效地訓練OFA網絡,我們還提出了一種新穎的漸進式收縮算法,這是一種通用的修剪方法,與修剪(深度,寬度,核心大小和分辨率)相比,該方法可以在更多元度上減小模型大小。它可以獲得數量驚人的子網(> 1019),可以适應不同的硬體平台和延遲限制,同時保持與獨立訓練相同的準确性。在各種邊緣裝置上,OFA始終優于最先進的(SOTA)NAS方法(與MobileNetV3相比,ImageNet top1的精度提高了4.0%,或相同的精度,但比MobileNetV3快1.5倍,比EfficientNet快2.6倍,測得的延遲時間) ),同時減少了多個數量級的GPU小時和二氧化碳排放量。特别是,在移動設定(<600M MAC)下,OFA達到了新的SOTA 80.0%ImageNet top-1精度。 OFA是第三屆低功耗計算機視覺挑戰賽(LPCVC),DSP分類軌道和第四屆LPCVC(分類軌道和檢測軌道)的獲獎解決方案。
1. 簡介
深度神經網絡(DNN)可在許多機器學習應用程式中提供最先進的準确性。 然而,模型尺寸和計算成本的爆炸性增長帶來了新的挑戰,關于如何在各種硬體平台上有效部署這些深度學習模型的說明,因為它們必須滿足不同的硬體效率限制(例如,延遲,能耗)。 例如,一部手機App Store上的應用程式必須支援各種硬體裝置,從帶有專用神經網絡加速器的高端三星Note10到5年前的三星s6。 使用不同的硬體資源(例如片上存儲器大小,#計算單元),最佳的神經網絡架構差異很大。 即使在相同的硬體上運作在不同的電池條件或工作負載下,最佳模型架構也相差很多。
考慮到不同的硬體平台和效率限制(定義為部署方案),研究人員要麼設計專門用于移動的緊湊模型(Howard等人,2017; Sandler等人,2018; Zhang等人,2018),要麼通過加速現有模型 壓縮(Han等人,2016; Heet等人,2018)以實作高效部署。 但是,使用基于人的方法或NAS來為每種情況設計專用DNN都是工程師昂貴且計算量很大的。由于此類方法需要重複網絡設計過程并針對每種情況從頭開始重新訓練設計的網絡。 随着部署方案數量的增加,它們的總成本呈線性增長,這将導緻過多的能源消耗和CO2排放(Strubell et al。,2019),這使他們無法處理大量的硬體裝置(231.4億個IoT裝置直到2018年)
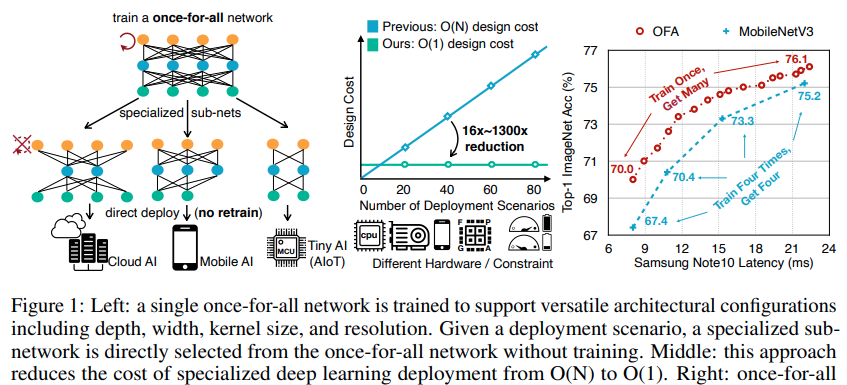
本文介紹了一種新的解決方案來應對這一挑戰,設計一個可以在各種架構配置下直接部署的千篇一律的網絡,進而分攤了教育訓練成本。這 通過僅選擇一次全部網絡的一部分來執行推理。它可以靈活地支援不同的深度,寬度,核心大小和分辨率,而無需重新訓練。千篇一律的簡單示例(OFA)如圖1所示(左)。具體來說,我們将模型訓練階段與神經體系結構搜尋階段解耦。在模型訓練階段,我們專注于提高通過選擇一次性網絡的不同部分而派生的所有子網的準确性。在模型搜尋階段,我們對子網的一個子集進行采樣,以訓練準确性預測器和等待時間預測器。給定目标硬體和限制條件,進行了以預測器為導向的架構搜尋(Liu等人,2018)以擷取專門的子網,并且成本可以忽略不計。是以,我們将專用神經網絡設計的總成本從O(N)降低到O(1)(圖1中間)
但是,訓練“一勞永逸”的網絡并非易事,因為它需要對權重進行聯合優化以維持大量子網的準确性(在我們的實驗中超過1019個)。在計算上禁止枚舉所有子網以在每個更新步驟中獲得準确的梯度,而在每個步驟中随機采樣幾個子網會導緻準确性顯着下降。挑戰在于,不同的子網之間會互相幹擾,進而使整個“一勞永逸”網絡的訓練過程效率低下。為了解決這一挑戰,我們提出了一種漸進式收縮算法,用于訓練“千篇一律”網絡。我們建議先訓練具有最大深度,寬度和核大小的最大神經網絡,然後再逐漸微調一次性網絡以支援較小的子網絡,而不是從頭開始直接優化一次性網絡。與較大的網絡共享權重的網絡。這樣,它通過選擇較大子網的最重要權重來提供更好的初始化,并有機會提取較小子網的機會,進而大大提高了訓練效率。從這個角度來看,漸進式收縮可以看作是一種通用的網絡修剪方法,它可以縮小整個網絡的多個次元(深度,寬度,核心大小和分辨率),而不僅僅是寬度次元。此外,它的目标是保持所有子網的準确性,而不是單個子網的準确性修剪的網絡。
這是首次在Imagenet的移動設定下的精度首次達到80%。

2. 相關工作
-
高效的神經網絡
提出了SqueezeNet,MobileNets,ShuffleNets等
-
神經網絡搜尋
早期在不考慮硬體效率的情況下搜尋高精度架構。 是以,産生的架構(例如,NASNet,AmoebaNet)不能有效地進行推理。 最新的可感覺硬體的NAS方法(Cai等人,2019; Tan等人,2019; Wu等人,2019)直接合并了硬體 回報給架構搜尋。 硬體-DNN協同設計技術(Jiang等,2019b; a; Hao等,2019)共同優化了神經網絡架構和硬體架構。 結果,它們可以提高推理效率。 但是,在給定新的推理硬體平台的情況下,這些方法需要重複架構搜尋過程并重新訓練模型,進而導緻開發成本過高。 GPU小時,美元和二氧化碳排放量。 它們不能擴充到大量的部署方案。 單獨訓練的模型不承擔任何責任,進而導緻較大的模型總尺寸和較高的下載下傳帶寬
- 動态神經網絡
3. 方法
3.1 問題
Wo表示“統一的網絡”,archi表示第i個子網絡的結構配置,C(Wo, archi)表示采用一種“政策”從Wo中選擇一部分組成一個子網絡。訓練的目标是:從Wo中選擇優化的子網絡和archi配置的網絡能保持同樣精度。
3.2 網絡結構空間
我們的千篇一律的網絡提供了一種模型,但支援許多不同大小的子網,涵蓋了卷積神經網絡(CNN)體系結構的四個重要次元,即深度,寬度,核心大小和分辨率。 遵循許多CNN模型的正常做法(He等人,2016; Sandler等人,2018; Huang等人,2017),我們将CNN模型劃分為一系列單元,這些單元具有逐漸減小的特征圖大小和增加的通道 數。 每個單元由一系列層組成,其中隻有第一層的步幅為2如果特征尺度需要減小。其他網絡層的stride都是1.
對于“統一的網絡”中,每個單元可采用變化的網絡層數,對每個層采用可變的通道數和可變的卷積核尺寸,支援不同大小的網絡輸入。例如:對于once-for-all,我們假設輸入尺寸在:[128,224] stride為4;每個單元的深度為{2,3,4};每層的寬度擴充為:{3,4,6};核尺寸為:{3,5,7};網絡有5個單元。則網絡結構的搜尋空間為:((3×3)2 + (3×3)3 + (3×3)4)5 ×25(不同的輸入)
3.3 train once-for-all network
訓練“一勞永逸”的網絡可以看作是一個多目标問題,其中每個目标都對應一個子網。 從這個角度出發,一種幼稚的訓練方法是使用總體目标的精确梯度從頭開始直接優化一次性網絡,這是通過枚舉每個更新步驟中的所有子網得出的,如等式所示。 。 (1)。 這種方法的成本與子網數量成線性關系。 是以,它僅适用于支援有限數量的子網的情況(Yu et al。,2019),而在我們的情況下,采用這種方法在計算上是禁止的
另一種幼稚的教育訓練方法是在每個更新步驟中對幾個子網進行采樣,而不是對所有子網進行枚舉,這樣就不會出現成本過高的問題。 但是,由于大量子網共享權重,是以互相幹擾,會造成網絡精度的下降。
- 漸進式搜尋
一次性網絡包括許多大小不同的子網,其中小子網嵌套在大子網中。為了防止子網之間的幹擾,我們建議以逐漸的方式執行從大型子網到小型子網的訓練順序。我們将此教育訓練方案稱為漸進收縮(PS)。圖3和圖4提供了使用PS訓練過程的示例,其中我們從訓練具有最大核尺寸(例如7),深度(例如4)和寬度(例如6)的最大神經網絡開始。 )。接下來,我們通過逐漸将其逐漸添加到采樣空間中來逐漸調整網絡以支援較小的子網(也可以對較大的子網進行采樣)。具體來說,在訓練了最大的網絡之後,我們首先支援彈性核心大小,該大小可以在每一層的{3,5,7}中進行選擇,而深度和寬度則保持最大值。然後,我們依次支援彈性深度和彈性寬度,如圖3所示。在整個訓練過程中,分辨率都是彈性的,這是通過為每批訓練資料采樣不同的圖像大小來實作的。在訓練了最大的神經網絡後,我們還使用了知識蒸餾技術(Hinton等人,2015; Ashok等人,2018; Yu&Huang,2019b)。它使用最大神經網絡給出的軟标簽和真實标簽來組合兩個損失項。
與幼稚的方法相比,PS可以防止小型子網幹擾大型子網,因為在微調一次性網絡以支援小型子網時,大型子網已經經過了良好的訓練。 關于小型子網,它們與大型子網共享權重。 是以,PS允許使用訓練有素的大型子網的最重要權重來初始化小型子網,進而加快了訓練過程(@@這個不知道是不是正确的)。 與網絡修剪(圖4)相比,PS還從訓練完整模型開始,但它不僅縮小了整個模型的寬度尺寸,而且縮小了整個模型的深度,核心尺寸和分辨率尺寸。 此外,PS可以微調大型和小型子網,而不是單個修剪的網絡。 結果,與網絡修剪相比,PS提供了更強大的“一勞永逸”網絡,可以适應各種硬體平台和效率限制。 我們描述PS教育訓練流程的細節如下:
- 彈性核尺寸
我們讓7x7卷積核心的中心也用作5x5核心,其中心也可以是3x3核心。 是以,卷積核大小變得有彈性。 挑戰在于居中的子核心(例如3x3和5x5)是共享的,并且需要扮演多個角色(獨立核心和大核心的一部分)。 作為不同角色,居中子核心的權重可能需要具有不同的分布或大小。 強制它們相同會降低某些子網的性能。 是以,我們在共享核心權重時引入了核心變換矩陣。 我們将不同的核心轉換矩陣用于不同的層。 在每一層中,核心轉換矩陣在不同通道之間共享。 這樣,我們隻需要額外的25×25 + 9×9 = 706個參數就可以在每層中存儲核心轉換矩陣,這可以忽略不計。
就是小卷積核的預訓練權重不是直接copy自大卷積核,而是采用了一個線性變換
- 彈性深度
為了得出一個在最初具有N層的單元中具有D層的子網,我們保留前D層并跳過最後N-D層,而不是像目前的NAS方法那樣保留任何D層(Cai等人 (2019年; Wu等人,2019年)。 這樣,一個深度設定僅對應于一層的組合。 最後,第一個D層的權重在大型模型和小型模型之間共享。
- 彈性寬度
寬度是指通道數。 我們為每一層提供了選擇不同通道擴充率的靈活性。 按照漸進式收縮方案,我們首先訓練一個全寬模型。 然後,我們介紹一種通道排序操作以支援部分寬度。 它根據管道的重要性重新組織管道,重要性是根據管道權重的L1規範計算得出的。 L1規範越大意味着越重要。 例如,當從4通道層縮小到3通道層時,我們選擇最大的3個通道,其權重與4通道層共享(圖6左和中)。 這樣,較小的子網就可以通過一次性網絡上最重要的通道進行初始化。訓練有素。 此通道分類操作保留了較大子網的準确性。
3.4 面向所有人的網絡的專用模型部署
4. 實驗
- 訓練細節 1200個小時,我2張卡的話需要訓練25天。别人1.5天完成。。。
【論文】——Once-for-All: Train One Network and Specialize it for Efficient Deployment閱讀
5. 總結
- 看到訓練用的GPU就直接勸退了,但是不知道小模型單獨抽離出來之後能否還保持比mobilenetv3更好的效果