在今天的文章裡,我們來主要介紹一下Elasticsearch的refresh及flush兩種操作的差別。如果我們從字面的意思上講,好像都是重新整理的意思。但是在Elasticsearch中,這兩種操作是有非常大的差別的。本指南将有效解決兩者之間的差異。 我們還将介紹Lucene功能的基礎知識,例如重新打開(reopen)和送出(commit),這有助于了解refresh和flush操作。
Refresh及Flush
乍一看,Refresh和Flush操作的通用目的似乎是相同的。 兩者都用于使文檔在索引操作後立即可供搜尋。 在Elasticsearch中添加新文檔時,我們可以對索引調用_refresh或_flush操作,以使新文檔可用于搜尋。 要了解這些操作的工作方式,您必須熟悉Lucene中的Segments,Reopen和Commits。Apache Lucene是Elasticsearch中的基礎查詢引擎。
Lucene中的Segments
在Elasticsearch中,最基本的資料存儲機關是shard。 但是,通過Lucene鏡頭看,情況會有所不同。 在這裡,每個Elasticsearch分片都是一個Lucene索引(index),每個Lucene索引都包含幾個Lucene segments。 一個Segment包含映射到文檔裡的所有術語(terms)一個反向索引(inverted index)。
下圖顯示了段的概念及其如何應用于Elasticsearch索引及其分片:
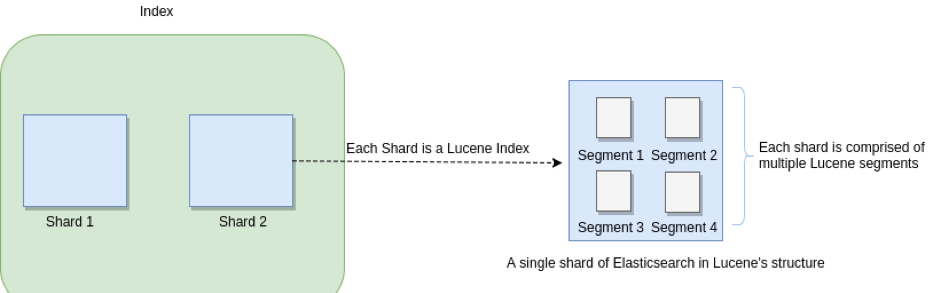
這種分Segment的概念是,每當建立新文檔時,它們就會被寫入新的Segment中。 每當建立新文檔時,它們都屬于一個新的Segment,并且無需修改前一個Segment。 如果必須删除文檔,則在其原始Segment中将其标記為已删除。 這意味着它永遠不會從Segement中實體删除。
與更新相同:文檔的先前版本在上一個Segment中被标記為已删除,更新後的版本保留在目前Segment中的同一文檔ID下。
Lucene中的Reopen
當調用Lucene Reopen時,将使累積的資料可用于搜尋。 盡管可以搜尋最新資料,但這不能保證資料的持久性或未将其寫入磁盤。 我們可以調用n次重新打開功能,并使最新資料可搜尋,但不能确定磁盤上是否存在資料。
Lucene中的Commits
Lucene送出使資料安全。 對于每次送出,來自不同段的資料将合并并推送到磁盤,進而使資料持久化。 盡管送出是持久儲存資料的理想方法,但問題是每個送出操作都占用大量資源。 每個送出操作都有其自己的内部 I/O 操作以及與其相關的讀/寫周期。 這就是為什麼我們希望在基于Lucene的系統中一次又一次地重新使用重新打開功能以使新資料可搜尋的确切原因。

Elasticsearch中的Translog
Elasticsearch采用另一種方法來解決持久性問題。 它在每個分片中引入一個事務日志(transaction log)。 已建立索引的新文檔将傳遞到此事務日志和記憶體緩沖區中。 下圖顯示了此過程:
Elasticsearch中的refresh
當我們把一條資料寫入到Elasticsearch中後,它并不能馬上被用于搜尋。新增的索引必須寫入到Segment後才能被搜尋到,是以我們把資料寫入到記憶體緩沖區之後并不能被搜尋到。新增了一條記錄時,Elasticsearch會把資料寫到translog和in-memory buffer(記憶體緩存區)中,如下圖所示:
我們可以看出來,在In-meomory buffer中,現在所有的東西都是空的,但是Translog裡還是有東西的。
refresh的開銷比較大,我在自己環境上測試10W條記錄的場景下refresh一次大概要14ms,是以在批量建構索引時可以把refresh間隔設定成-1來臨時關閉refresh,等到索引都送出完成之後再打開refresh,可以通過如下接口修改這個參數:
curl -XPUT 'localhost:9200/test/_settings' -d '{
"index" : {
"refresh_interval" : "-1"
}
}'
另外當你在做批量索引時,可以考慮把副本數設定成0,因為document從主分片(primary shard)複制到從分片(replica shard)時,從分片也要執行相同的分析、索引和合并過程,這樣的開銷比較大,你可以在建構索引之後再開啟副本,這樣隻需要把資料從主分片拷貝到從分片:
curl -XPUT 'localhost:9200/my_index/_settings' -d ' {
"index" : {
"number_of_replicas" : 0
}
}'
執行完批量索引之後,把重新整理間隔改回來:
curl -XPUT 'localhost:9200/my_index/_settings' -d '{
"index" : {
"refresh_interval" : "1s"
}
}'
你還可以強制執行一次refresh以及索引分段的合并:
curl -XPOST 'localhost:9200/my_index/_refresh'
curl -XPOST 'localhost:9200/my_index/_forcemerge?max_num_segments=5'
Translog及持久化存儲
但是,translog如何解決持久性問題? 每個Shard中都存在一個translog,這意味着它與實體磁盤記憶體有關。 它是同步且安全的,是以即使對于尚未送出的文檔,您也可以獲得持久性和持久性。 如果發生問題,可以還原事務日志。 同樣,在每個設定的時間間隔内,或在成功完成請求(索引,批量,删除或更新)後,将事務日志送出到磁盤。
Elasticsearch中的Flush
Flush實質上意味着将記憶體緩沖區中的所有文檔都寫入新的Lucene Segment,如下面的圖所示。 這些連同所有現有的記憶體段一起被送出到磁盤,該磁盤清除事務日志(參見圖4)。 此送出本質上是Lucene送出(commit)。