預設情況下,大多數字段都已編入索引,這使它們可搜尋。 但是,腳本中的排序,聚合和通路字段值需要與搜尋不同的通路模式。
搜尋需要回答“哪個文檔包含該術語?”這個問題,而排序和彙總則需要回答一個不同的問題:“此字段對該文檔的值是什麼?”。
大多數字段可以将索引時生産的磁盤doc_values(https://www.elastic.co/guide/en/elasticsearch/reference/current/doc-values.html)用于此資料通路模式,但是文本(text)字段不支援doc_values。
替代的方案,文本(text)字段使用查詢時記憶體中的資料結構,稱為fielddata。 當我們首次将該字段用于聚合,排序或在腳本中使用時,将按需建構此資料結構。 它是通過從磁盤讀取每個段的整個反向索引,反轉術語↔︎文檔關系并将結果存儲在JVM堆中的記憶體中來建構的。
Fielddata針對text字段在預設時是禁用的
Fielddata會占用大量堆空間,尤其是在加載大量的文本字段時。 一旦将字段資料加載到堆中,它在該段的生命周期内将一直保留在那裡。 同樣,加載字段資料是一個昂貴的過程,可能導緻使用者遇到延遲的情況。 這就是預設情況下禁用字段資料的原因。
假如我們建立一個如下的myindex的索引:
PUT myindex
{
"mappings": {
"properties": {
"address": {
"type": "text"
}
}
}
}
PUT myindex/_doc/1
{
"address": "New York"
}
如果您嘗試對文本字段中的腳本進行排序,彙總或通路值:
GET myindex/_search
{
"size": 20,
"aggs": {
"aggr_mame": {
"terms": {
"field": "address",
"size": 5
}
}
}
}
則會看到以下異常:
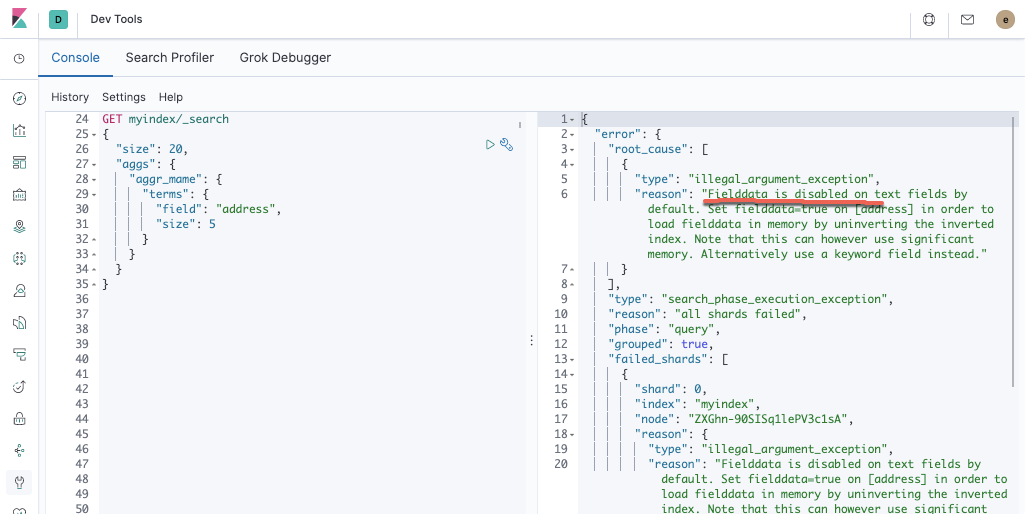
顯然,我們不能對text字段進行聚合處理。那麼我們該如何處理這個問題呢?
我們的一種方法就是在配置mapping的時候加入"fielddata"=true這個選項。我們來重新對我們的myindex的mapping進行配置:
DELETE myindex
PUT myindex
{
"mappings": {
"properties": {
"address": {
"type": "text",
"fielddata": true
}
}
}
}
PUT myindex/_doc/1
{
"address": "New York"
}
GET myindex/_search
{
"size": 0,
"aggs": {
"aggr_mame": {
"terms": {
"field": "address",
"size": 5
}
}
}
}
在這裡,我們盡管還是把address這個字段設定為text,但是由于我們加入了"fielddata"=true,那麼我們,我們就可以對這個項進行統計了。

與簡單的搜尋操作不同,排序和聚合需要能夠發現在特定文檔的特定字段中可以找到哪些術語。 對于這些任務和其他任務,必須具有與Elasticsearch(反向)索引相反的資料結構。 這就是fielddata的目的。
細心的開發者,如果這個時候去Kibana建立一個以myindex為索引的index pattern,我們可以發現:
我們的address字段變為aggregatable,也就是說我們可以對它進行做聚合分析盡管它沒有doc_values。
在啟動fielddata之前
在啟用fielddata之前,請考慮為什麼将文本字段用于聚合,排序或在腳本中使用。 這樣做通常沒有任何意義。
在索引之前會分析文本字段,以便可以通過搜尋new或york來找到類似New York的值。 當您可能想要一個名為New York的存儲桶時,此字段上的術語彙總将傳回一個叫做new存儲桶和一個叫做york存儲桶。
DELETE myindex
PUT myindex
{
"mappings": {
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}