在《分類:基于規則的分類技術》中已經比較詳細的介紹了基于規則的分類方法,RIPPER算法則是其中一種具體構造基于規則的分類器的方法。在RIPPER算法中,有幾個點是算法的重要構成部分,需要強調一下
- 規則排序方式
RIPPER算法中采用的仍然是基于類的規則排序方式,不過獨特的地方是,它先将各個類按頻率(即類中包含的樣本占總樣本數的比例)從低到高排序,設
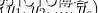
是排序後的類,

是最不頻繁的類,
是最頻繁的類,按照《分類:基于規則的分類技術》中介紹的規則生成方法,生成類
的規則,直至剩下類
,然後類
作為預設類,這樣做的好處是減少資料在作類預測時的比較次數,因為機率最大的類是預設類,這樣多數資料隻需要做少量的規則比較。
- 規則的增長
RIPPER算法使用FOIL資訊增益來選擇最有的合取項來添加到規則前件中,當規則開始覆寫反例時即停止添加合取項,此時采用IREP剪枝方法,将規則在驗證集上剪枝,是否剪枝則需要依據如下度量參數來決定
其中
、
分别表示規則在驗證集上所覆寫的正例和反例個數,若剪枝後改度量增大,則保留剪枝結果,否則不進行剪枝。剪枝時,從規則末尾的合取項開始。盡管剪枝前規則隻覆寫正例,但剪枝後的規則可能會覆寫訓練集中部分反例。
- 建立規則集
一條規則生成後,是否能夠添加到規則集中還需要經過兩個條件判斷,首先,該規則不違反最小描述長度原則(MDL);其次,規則在驗證集上的錯誤率不超過50%。關于最小描述長度原則,這裡稍微說明一下。根據維基百科中的解釋,最小描述長度原則是奧卡姆剃刀原則形式化後的描述,當,其背後的思想是:在任一給定的資料集内的任何規律性都可用來壓縮,也即是在描述資料時,與逐字逐句來描述資料的方式相比,能使用比所需還少的符号,既然如此,總有一種描述方式長度最小,這裡長度用計算機中二進制的比特位(bit)來表示。
不違反最小描述長度原則,指的是在添加規則後,整個規則集的長度增加不超過一定比特位數,預設是64位。