為什麼需要值函數近似?
之前我們提到過各種計算值函數的方法,比如對于 MDP 已知的問題可以使用 Bellman 期望方程求得值函數;對于 MDP 未知的情況,可以通過 MC 以及 TD 方法來獲得值函數,為什麼需要再進行值函數近似呢?
其實到目前為止,我們介紹的值函數計算方法都是通過查表的方式擷取的:
- 表中每一個狀态 \(s\) 均對應一個 \(V(s)\)
- 或者每一個狀态-動作 <\(s, a\)>
但是對于大型 MDP 問題,上述方法會遇到瓶頸:
- 太多的 MDP 狀态、動作需要存儲
- 單獨計算每一個狀态的價值都非常的耗時
是以我們需要有一種能夠适用于解決大型 MDP 問題的通用方法,這就是本文介紹的值函數近似方法。即:
\[\hat{v}(s, \mathbf{w}) \approx v_{\pi}(s) \\
\text{or } \hat{q}(s, a, \mathbf{w}) \approx q_{\pi}(s, a)
\]
那麼為什麼值函數近似的方法可以求解大型 MDP 問題?
對于大型 MDP 問題而言,我們可以近似認為其所有的狀态和動作都被采樣和計算是不現實的,那麼我們一旦擷取了近似的值函數,我們就可以對于那些在曆史經驗或者采樣中沒有出現過的狀态和動作進行泛化(generalize)。
進行值函數近似的訓練方法有很多,比如:
- 線性回歸
- 神經網絡
- 決策樹
- ...
此外,針對 MDP 問題的特點,訓練函數必須可以适用于非靜态、非獨立同分布(non-i.i.d)的資料。
增量方法
梯度下降
梯度下降不再贅述,感興趣的可以參考之前的博文《梯度下降法的三種形式BGD、SGD以及MBGD》
通過随機梯度下降進行值函數近似
我們優化的目标函數是找到一組參數 \(\mathbf{w}\) 來最小化最小平方誤差(MSE),即:
\[J(\mathbf{w}) = E_{\pi}[(v_{\pi}(S) - \hat{v}(S, \mathbf{w}))^2]
通過梯度下降方法來尋優:
\[\begin{align}
\Delta\mathbf{w}
&=-\frac{1}{2}\alpha\triangledown_{\mathbf{w}}J(\mathbf{w})\\
&=\alpha E_{\pi}\Bigl[\Bigl(v_{\pi}(S) - \hat{v}(S, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}J(\mathbf{w})\Bigr]
\end{align}
對于随機梯度下降(Stochastic Gradient Descent,SGD),對應的梯度:
\[\Delta\mathbf{w} = \alpha\underbrace{\Bigl(v_{\pi}(S) - \hat{v}(S, \mathbf{w})\Bigr)}_{\text{error}}\underbrace{\triangledown_{\mathbf{w}}\hat{v}(S, \mathbf{w})}_{\text{gradient}}
值函數近似
上述公式中需要真實的政策價值函數 \(v_{\pi}(S)\) 作為學習的目标(supervisor),但是在RL中沒有真實的政策價值函數,隻有rewards。在實際應用中,我們用target來代替 \(v_{\pi}(S)\):
- 對于MC,target 為 return \(G_t\):
\[\Delta\mathbf{w}=\alpha\Bigl(G_t - \hat{v}(S_t, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}\hat{v}(S_t, \mathbf{w})
- 對于TD(0),target 為TD target \(R_{t+1}+\gamma\hat{v}(S_{t+1}, \mathbf{w})\):
\[\Delta\mathbf{w}=\alpha\Bigl(R_{t+1} + \gamma\hat{v}(S_{t+1}, \mathbf{w})- \hat{v}(S_t, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}\hat{v}(S_t, \mathbf{w})
- 對于TD(λ),target 為 TD λ-return \(G_t^{\lambda}\):
\[\Delta\mathbf{w}=\alpha\Bigl(G_t^{\lambda}- \hat{v}(S_t, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}\hat{v}(S_t, \mathbf{w})
在擷取了值函數近似後就可以進行控制了,具體示意圖如下:
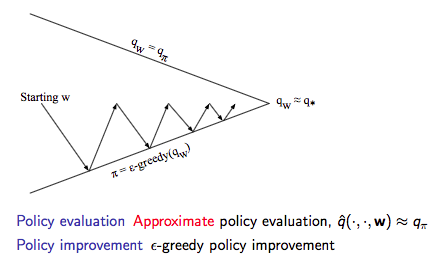
動作價值函數近似
動作價值函數近似:
\[\hat{q}(S, A, \mathbf{w})\approx q_{\pi}(S, A)
優化目标:最小化MSE
\[J(\mathbf{w}) = E_{\pi}[(q_{\pi}(S, A) - \hat{q}(S, A, \mathbf{w}))^2]
使用SGD尋優:
&=\alpha\Bigl(q_{\pi}(S, A)-\hat{q}_{\pi}(S, A, \mathbf{w})\Bigr) \triangledown_{\mathbf{w}}\hat{q}_{\pi}(S, A, \mathbf{w})
\end{align}\]
收斂性分析
略,感興趣的可以參考David的課件。
批量方法
随機梯度下降SGD簡單,但是批量的方法可以根據agent的經驗來更好的拟合價值函數。
優化目标:批量方法解決的問題同樣是 \(\hat{v}(s, \mathbf{w})\approx v_{\pi}(s)\)
經驗集合 \(D\) 包含了一系列的 <state, value> pair:
\[D=\{<s_1, v_1^{\pi}>, <s_2, v_2^{\pi}>, ..., <s_T, v_T^{\pi}>\}
根據最小化平方誤差之和來拟合 \(\hat{v}(s, \mathbf{w})\) 和 \(v_{\pi}(s)\),即:
LS(w)
&= \sum_{t=1}^{T}(v_{t}^{\pi}-\hat{v}(s_t, \mathbf{w}))^2\\
&= E_{D}[(v^{\pi}-\hat{v}(s, \mathbf{w}))^2]
經驗回放(Experience Replay):
給定經驗集合:
Repeat:
\[\mathbf{w}^{\pi}=\arg\min_{\mathbf{w}}LS(\mathbf{w})
- 從經驗集合中采樣狀态和價值:\(<s, v^{\pi}>\sim D\)
使用SGD進行更新:\(\Delta\mathbf{w}=\alpha\Bigl(v^{\pi}-\hat{v}(s, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}\hat{v}(s, \mathbf{w})\)
通過上述經驗回放,獲得最小化平方誤差的參數值:
我們經常聽到的 DQN 算法就使用了經驗回放的手段,這個後續會在《深度強化學習》中整理。
通過上述經驗回放和不斷的疊代可以擷取最小平方誤差的參數值,然後就可以通過 greedy 的政策進行政策提升,具體如下圖所示:
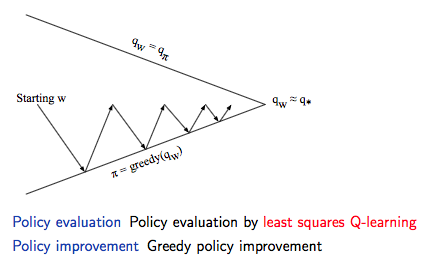
同樣的套路:
- 優化目标:\(\hat{q}(s, a, \mathbf{w})\approx q_{\pi}(s, a)\)
- 采取包含 <state, action, value> 的經驗集合 \(D\)
- 通過最小化平方誤差來拟合
對于控制環節,我們采取與Q-Learning一樣的思路:
- 利用之前政策的經驗
- 但是考慮另一個後繼動作 \(A'=\pi_{\text{new}}(S_{t+1})\)
- 朝着另一個後繼動作的方向去更新 \(\hat{q}(S_t, A_t, \mathbf{w})\),即
\[\delta = R_{t+1} + \gamma\hat{q}(S_{t+1}, \pi{S_{t+1}, \mathbf{\pi}}) - \hat{q}(S_t, A_t, \mathbf{w})
- 梯度:線性拟合情況,\(\Delta\mathbf{w}=\alpha\delta\mathbf{x}(S_t, A_t)\)
Reference
[1] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto, 2018
[2] David Silver's Homepage
作者:Poll的筆記
部落格出處:http://www.cnblogs.com/maybe2030/
本文版權歸作者和部落格園所有,歡迎轉載,轉載請标明出處。
<如果你覺得本文還不錯,對你的學習帶來了些許幫助,請幫忙點選右下角的推薦>
![算法導論8-5思考題-平均排序-average sorting[圖]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACwAAAAAAQABAAACAkQBADs=)