此文是對 Spark on MR3 資料的翻譯
原文連結:
https://www.datamonad.com/post/2021-08-18-spark-mr3/ 代碼連結: https://github.com/mr3project/spark-mr3
MR3 是一個通用的執行引擎,原生支援 Hadoop 和 Kubernetes。雖然 Hive on MR3 是主要應用,但 MR3 也可以輕松執行 MapReduce/Tez 作業。例如,Hive on MR3 可以不依賴 MapReduce 進行壓縮,因為執行壓縮的 MapReduce 作業會被直接發送到 MR3。
随着 MR3 1.3 的釋出,開發團隊引入了另一個主要應用 – Spark on MR3。簡而言之,就是使用 MR3 作為執行後端的 Apache Spark。MR3 上的 Spark 是作為 Spark 的附加元件實作的,它利用 MR3 來實作 Spark 的排程後端。是以,在 MR3 上運作 Spark 不需要對 Spark 進行任何更改,并且使用者在 MR3 上安裝 Spark 時可以使用 Spark Binary Distribution。
在詳細介紹 Spark on MR3 之前,應該回答一個關鍵問題——為什麼我們需要一個替代的 Spark 執行後端? 畢竟 Spark 是一個成熟的系統,已經為 Hadoop 和 Kubernetes 提供了原生支援,是以 Spark on MR3 似乎沒有帶來額外的優勢。然而,Spark on MR3 不僅僅是為了展示 MR3 作為執行引擎的能力。相反,它解決了 Apache Spark 的一個重要架構限制。
動機
在 MR3 上開發 Spark 的主要動機是允許多個 Spark 應用程式共享計算資源,例如 Yarn 容器或 Kubernetes Pod。 對于普通 Spark,不同的 Spark 應用程式必須維護自己的一組 executor,因為 Spark 缺乏在 Spark 應用程式之間回收計算資源的功能。相反,Spark 依靠資料總管(例如 Yarn 和 Kubernetes)來配置設定計算資源。請注意,Apache Livy 不是這裡的解決方案,因為它隻允許多個使用者通過 REST API 共享 Spark 應用程式。
對于 Spark on MR3,MR3 DAGAppMaster 的單執行個體管理 Spark 應用程式之間共享的所有計算資源。下圖說明了在 Kubernetes 上運作的 Spark on MR3,其中四個 Spark driver 共享一個公共 DAGAppMaster Pod。當 Spark driver 終止時,其執行程式 Pod 不會立即釋放回 Kubernetes。相反,DAGAppMaster 嘗試通過将空閑 Pod 重新配置設定給那些請求更多計算資源的 Spark driver 或将它們保留在備用池中以備将來使用。
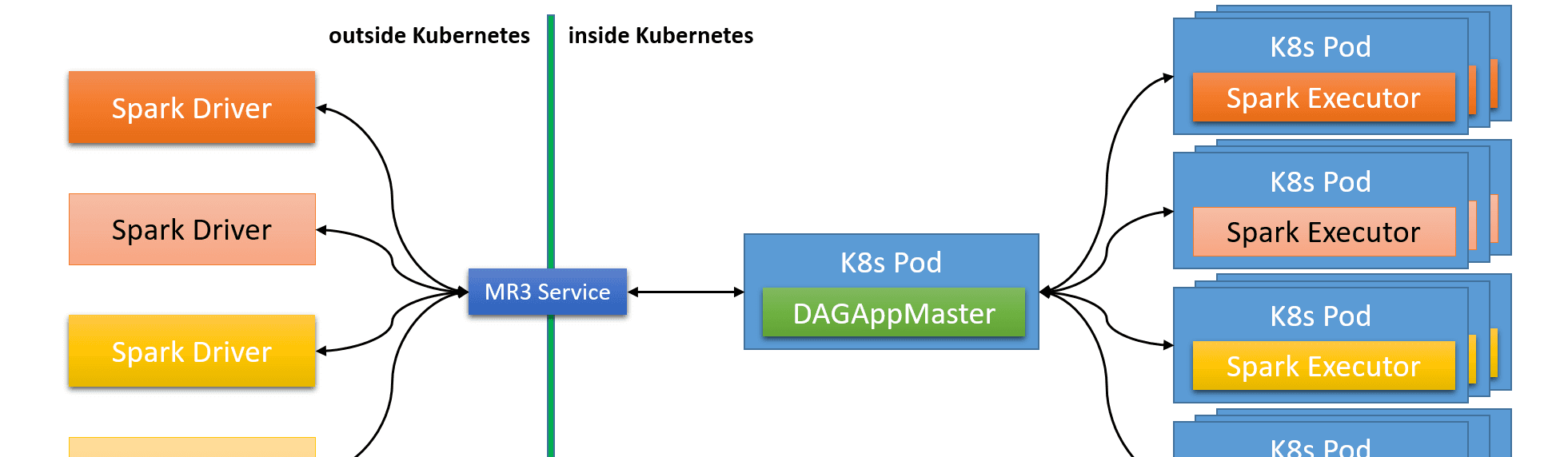
是以,當多個 Spark 應用程式并發運作時,Spark on MR3 減少了擷取和釋放計算資源的開銷。由于 MR3 使用 Java 虛拟機(JVM),回收計算資源也轉化為減少 JVM 預熱開銷。此外,Spark on MR3 将自身與資料總管的排程政策分離。例如,無論資料總管的排程政策如何,我們都可以在 Spark 應用程式之間強制執行公平排程。
Spark on MR3 在頻繁建立和銷毀 Spark 應用程式的雲環境中特别有用。在雲環境中,配置計算資源的開銷遠非可以忽略不計。例如,在 Amazon EKS 上預置新的 Kubernetes 節點可能需要幾分鐘時間。通過允許 DAGAppMaster 保留計算資源的備用池,Spark on MR3 可以有效地最小化計算資源的開銷。因為 Spark 作業在送出後立即執行,它可以實作雲成本的降低以及使用者體驗的改進。
應用
Spark on MR3 是作為 Spark 的附加元件實作的。Spark-MR3 作為外部叢集管理器,提供 Spark 排程後端的實作。Spark-MR3 嵌入在 Spark driver中,并在 Spark driver 和 MR3 之間傳輸消息。在内部,它提供了 Spark TaskScheduler 和 SchedulerBackend 的實作,并建立了 MR3Client 以便與 MR3 進行通信。當 Spark DAGScheduler 想要執行新的 Spark stage 時,Spark-MR3 将 stage 的格式轉換為 DAG,然後發送到 MR3 DAGAppMaster。DAG 由運作在 ContainerWorkers 内的 Spark executor 執行,并将結果發送回 Spark。

由于 Spark-MR3 将所有來自 Spark 的請求發送到 MR3,是以從 Spark 的角度來看,MR3 是類似于 Yarn 和 Kubernetes 的資料總管。這是有效的,因為 Spark 與底層叢集管理器無關,而 MR3 能夠在與真正的資料總管通信後提供計算資源。由于 Spark 使用 Java ServiceLoader 機制加載外部叢集管理器,是以在 MR3 上運作 Spark 不需要對 Spark 進行任何更改。
實驗
現在開發團隊展示實驗結果來證明 Spark on MR3 的性能。除了任務排程和資源管理,Spark on MR3 的行為方式與普通 Spark 相同。首先,開發團隊展示了 Spark on MR3 在單個 Spark 應用程式上與普通 Spark 表現一緻。接下來,開發團隊将展示當多個 Spark 應用程式同時運作時,Spark on MR3 的運作時間大幅減少。
在實驗中,開發團隊使用兩個運作 HDP(Hortonworks Data Platform)3.1.4 的叢集。每個工作節點運作一個 ContainerWorker,或者說是一個 Spark executor。
- Gold 叢集,由 2 個主節點、34 個工作節點(每個節點具有 24 個核心和 96 GB 記憶體)和十千兆網絡組成。
- Grey 叢集,1 個主節點,9 個工作節點(每個節點有 12 個核心和 48 GB 記憶體)和一千兆網絡。慢網絡使得 Grey 叢集适合評估普通 Spark 和 Spark on MR3 中延遲排程的有效性。
開發團隊使用 Spark 多使用者基準測試作為工作負載。Spark 應用程式中的每個線程都送出相同的 8 個 TPC-DS 基準查詢序列(#19、#42、#52、#55、#63、#68、#73、#98)。開發團隊使用的比例因子為 100(大約相當于 100GB),它可以保持每個工作節點處于忙碌狀态,也可以清楚地突出回收 ContainerWorkers 的效果。開發團隊以文本格式存儲資料集而不進行壓縮。
單個 Spark 應用程式
Spark on MR3 提供了兩種任務排程政策——FIFO 排程和公平排程,它們規定如何在同一個 Spark 應用程式中配置設定 Spark 作業。Spark on MR3 也以類似于普通 Spark 的方式實作延遲排程。對于單個 Spark 應用程式的測試,開發團隊使用 1 秒延遲進行延遲排程(例如,設定普通 Spark 的參數
spark.locality.wait
為 1 秒 )。
下圖顯示了在 Gold 叢集中使用普通 Spark 和 Spark on MR3 運作單個 Spark 應用程式的結果。Spark driver 建立八個線程,每個線程送出相同的八個 TPC-DS 查詢序列。(是以它總共送出了 $8 \times 8 = 64$ 個 Spark 作業。)開發團隊觀察到,在 FIFO 排程下,Spark on MR3 的運作速度與普通 Spark 一樣快,但在公平排程下,速度稍慢。
Grey 叢集測試結果完全不同。開發團隊觀察到,Spark on MR3 比普通 Spark 執行 Spark 作業的完成速度要快得多,FIFO 排程為 3034 s 與 8042 s,公平排程為 3583 s 與 8017 s。
運作時間的巨大差異是由于任務排程的不同,特别是延遲排程在普通 Spark 和 Spark on MR3 中是如何工作的。下圖顯示了沒有比對機器的 Spark 任務的百分比。例如,一個帶有 grey1 和 grey2 位置标簽的 Spark 任務,如果在 grey3 上執行,則沒有比對到機器上。開發團隊觀察到,普通 Spark 的百分比要高得多,FIFO 排程為 1.8% 與 22.7%,公平排程為 7.2% 與 26.8%。結合使用慢速(1 Gb)網絡,高百分比會産生許多落後的任務,進而顯着增加運作時間。
多個 Spark 應用程式
獨立于任務排程政策,Spark on MR3 提供了兩個政策——FIFO 排程和公平排程,指定如何在多個 Spark 應用程式之間配置設定 ContainerWorkers(即計算資源)。為了測試多個應用程式,開發團隊禁用延遲排程。
下圖顯示了在使用 Yarn 公平排程的 Gold 叢集中使用普通 Spark 運作 12 個相同的 Spark 應用程式的結果。豎條顯示在相應工作節點上運作的 Spark executor 的進度,其顔色表示擁有 Spark executor 的 Spark 應用程式。可以觀察到,盡管使用了公平排程,但 Spark 應用程式在 Yarn 配置設定的計算資源總量方面存在很大差異。我們還看到豎線之間的許多間隙,它們表示 Spark executor 終止後和另一個 Spark executor 啟動之前的空閑時間。
下圖顯示了在 Gold 叢集中使用公平排程在 Spark on MR3 運作相同的 12 個 Spark 應用程式的結果。 順便說一句,資料總管本身的排程政策對實驗來說并不重要。可以觀察到,Spark on MR3 通過回收 ContainerWorkers 快速實作了 Spark executor 之間工作節點的公平配置設定。 請注意,Spark on MR3 不會在垂直條之間産生間隙,因為在整個實驗過程中,每個工作節點上都會回收一個 ContainerWorker。 在我們的實驗中,與普通 Spark 相比,Spark on MR3 将運作時間減少了 25.6%(從 907.7s 到 674.6s)。
下圖顯示了當 Yarn 和 Spark on MR3 都使用 FIFO 排程時 Gold 叢集中的結果。開發團隊以 60 秒的間隔送出每個 Spark 應用程式。普通 Spark 和 Spark on MR3 都一次運作一個 Spark 應用程式,并按照送出的順序完成所有 Spark 應用程式。 請注意,一旦第一個 Spark 應用程式終止,Spark on MR3 就會更快地完成剩餘的 Spark 應用程式,因為 JVM 已經預熱。 在實驗中,與普通 Spark 相比,Spark on MR3 将運作時間減少了 36.3%(從 797.3s 到 1144.5s)。
總結
Spark on MR3 易于使用在 Hadoop 和 Kubernetes 上,因為它與 Apache Spark 的不同之處僅在于任務排程和資源管理。 除了在 Spark 應用程式中回收 ContainerWorkers 之外,使用者還可以利用 MR3 的容錯、推測執行和自動縮放等特性。