雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
光動嘴不用出聲,AI自動給你合成語音。
這就是來自印度資訊技術研究所(IIIT)的黑科技——一個名為Lip2Wav的AI程式。
Lip2Wav可以學習個體的說話方式,并且實作準确的唇語合成。
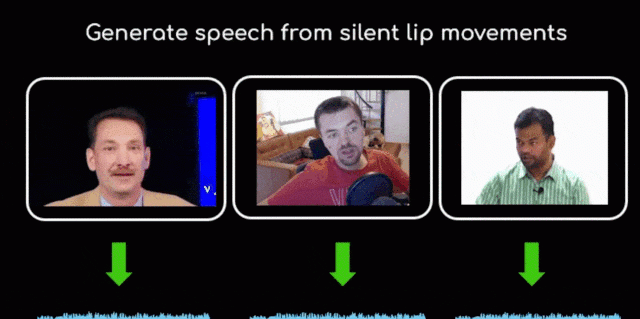
△示例
值得注意的是,Lip2Wav和B站那些機械風格的鬼畜調音不一樣。
這個AI效果炸裂,你幾乎感覺不到是機器配音,就像人類在發言一樣。
真實效果可以參見他們釋出在油管的視訊。
畢竟涉及到語音效果,光看文字是感覺不完整的。
另外,不要用來做壞事喲。
這是怎麼實作的?
目前工業界普遍使用的唇語到語音/文本的資料集有兩種。
一種是小規模的、受限制的詞彙資料集,如GRID和TCD-TIMIT資料集,還有一種是無限制、開源的多人詞彙資料集,如LRS2、LRW和LRS3資料集。
這些資料集前者存在數量不足,不足以模拟真實環境的問題,後者問題在于适用對象過于寬泛,個性化特征不夠鮮明。
基于上述問題,作者提出新的思路,步驟如下:
1、準備資料。
準備針對個人的語音、視訊大量資料,這是Lip2Wav的第一個顯著特點,增加資料量來增強模型的拟合效果。

△5個演講者
作者為Lip2Wav準備的資料集包含了5位演講者的演說視訊,這些視訊包括國際象棋分析、化學課程、深度學習課程等類型。
每個演講者都有大約20個小時的YouTube視訊内容,作者使用了5個人、共計100+小時的資料,跨越5000+的豐富詞彙量,基本涵蓋日常英語詞彙。
2、面部識别中得到唇部動作編碼。
在整理好資料後,作者的思路是學習精确的個體說話風格,換言之追求對個體風格的極緻模拟,而非普遍适用的通用模型。
△訓練流程
這個示例針對的是國際象棋分析,訓練AI去分析演講者的面部表情動作,并進行特征編碼。
當然,作者沒有重複造輪子,而是利用face_alignment模型上二次開發,修改為一次分批提取人臉。
face_alignment模型對3D人臉識别效果良好,在GitHub有3.9k Star。
△face_alignment模型對人臉進行3D模組化
3、使用LSTM根據唇部動作進行文字生成。
在得到人臉特征後,研究者要做的是把唇部動作和語音文字結合起來。
△訓練示例
在數輪3D卷積神經網絡訓練後,研究者使用LSTM進行文字生成,以期比對先前的唇語動作。
4、評估結果。
在得到訓練結果後,研究者使用另外兩份資料集進行驗證,檢測Lip2Wav模型的泛化能力。
他們使用了GRID和TCD-TIMIT資料集,其中的WER列為錯誤率❌的衡量參數。
根據比較結果,和現有模型相比,Lip2Wav模型得分最低,效果最好。
而更有創意的是,研究者為彌補他們資料集過于針對個人風格的特點,還設計了人類評估的步驟。
讓人類志願者進行客觀評估。
他們要求志願者手動識别并報告A,錯誤發音的百分比,B,單詞跳字的百分比(單詞跳讀是指由于噪聲或語調不清而完全無法了解的單詞數量。),以及C,同音字的百分比。
△人類客觀評估平均數
上圖是從Lip2Wav資料集中的每個演講者的未讀測試分詞中選取10個預測的結果。
個人風格過強的問題
作者釋出之後,引起Reddit的熱議。
但吃瓜群衆的疑問在于,他們的模型是否能夠針對普通人進行語音合成。
沒想到模型作者現身說法,明确表示暫時還不行,隻有針對訓練的特定個人才能有效拟合資料。
而作者還在評論區回應,他們未來會增加視訊字幕生成的能力,類似于YouTube的字幕生成功能,期待項目的進一步發展。
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/live立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-06-06
本文作者:梅甯航
本文來自:“
量子位公衆号”,了解相關資訊可以關注“公衆号QbitAI”