在 DataFlux 的日常開發中,我們也會遇到其他開發者都會遇到的問題:怎麼監控我們⾃己寫的程式呢?
DataFlux ⼤概的子產品如下:
名額集名稱 标簽列列表 名額列列表 時間戳 比如:
其中,标簽清單是相對固定的屬性,如體檢資料中的姓名和性别。而名額清單則是⼀些相對比較動态的屬性,它們會随着時間推移而變化。最後就是以納秒為機關的 Unix 時間戳。
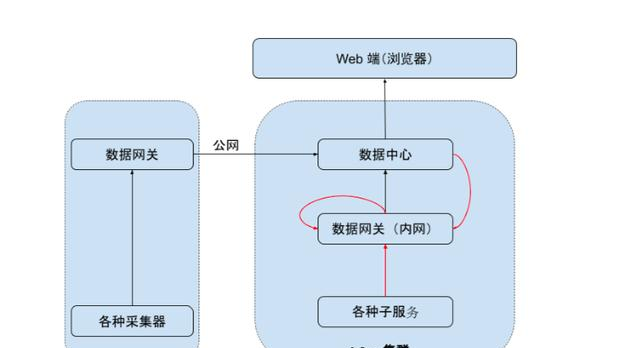
在上圖中,為了采集 k8s 叢集内各個服務的名額資料,有兩種⽅方式:
- 開發專⽤的采集器,采集各個服務的資料,然後上報給資料網關
- 各個服務⾃己報告⾃己感興趣的名額,上報給資料⽹關

「DataFlux」基于行協定實作軟體自監控
第⼀種方式實作不太方便,首先,各個服務需要開放資料采集接口,然後還要單獨開發采集器調用接口來采集運行⽇志,通常情況下,這些資料都是⾼度定制的,不太能使用現有的工具來采集。
第二種⽅式就很靈活,得益于行協定的簡單設計,各個子服務隻需要将⾃己感興趣的運行名額,以行協定的方式上報給資料⽹關即可,⽆無需在采用其它的⼯具來收集運⾏⽇志。
下⾯是⼀段示例代碼:查詢 InfluxDB 時,我們希望能監控一些較慢(響應時間大于 1 秒)的查詢:
start := time.Now()
sql := `SELECT * FROM "體檢資料"` influx.Query(sql)
elapsed := time.Since(start)
if elapsed.Seconds() > 1.0 {
event := fmt.Sprintf(`influx_slow_query,叢集ID=%s,DB=%s sql="%s",cost=%f %d`, influx.InstanceID,
influx.DB,
sql,
elapsed.Seconds(),
time.Now().Nanosecond())
dataway.Send(event)
} 這樣一來,一旦有一個慢查詢,就能在 Web 上看到這個慢查詢記錄,我們可以輕松定位是哪個查詢語句、 在哪個實例上出現了慢查詢。進一步通過對 SQL 以及 InfluxDB 本身的監控分析,我們就能确定,是 SQL 編寫的問題(這里明顯是因為沒有 LIMIT 資料條數,資料量太大導緻的),還是叢集負載過高的問題。
通過這種⽅式,我們能收集資料中心、資料網關自身以及叢集内其它子服務的運行日志(如上圖中紅線箭頭所示),甚至,通過 Telegraf、Prometheus 等開源⼯具,我們還能将 k8s 叢集本身的資料,通過資料網關彙聚,進而實作對它們的統一監控。