雲栖号資訊:【 點選檢視更多行業資訊】
在這裡您可以找到不同行業的第一手的上雲資訊,還在等什麼,快來!
之前有過一次面試,關于MySQL索引的原理及使用被面試官怼的體無完膚,立志要總結一番,然後一直沒有時間(其實是懶……),準備好了嗎?
索引是什麼?
資料庫索引,是資料庫管理系統(DBMS)中一個排序的資料結構,它可以對資料庫表中一列或多列的值進行排序,以協助更加快速的通路資料庫表中特定的資料。通俗的說,我們可以把資料庫索引比做是一本書前面的目錄,它能加快資料庫的查詢速度。
為什麼需要索引?
思考:如何在一個圖書館中找到一本書?設想一下,假如在圖書館中沒有其他輔助手段,隻能一條道走到黑,一本書一本書的找,經過3個小時的連續查找,終于找到了你需要看的那本書,但此時天都黑了。
為了避免這樣的事情,每個圖書館才都配備了一套圖書館管理系統,大家要找書籍的話,先在系統上查找到書籍所在的房屋編号、圖書架編号還有書在圖書架幾層的那個方位,然後就可以直接大搖大擺的去取書了,就可以很快速的找到我們所需要的書籍。索引就是這個原理,它可以幫助我們快速的檢索資料。
一般的應用系統對資料庫的操作,遇到最多、最容易出問題是一些複雜的查詢操作,當資料庫中資料量很大時,查找資料就會變得很慢,這樣就很影響整個應用系統的效率,我們就可以使用索引來提高資料庫的查詢效率。
B-Tree和B+Tree
目前大部分資料庫系統及檔案系統都采用B-Tree或其變種B+Tree作為索引結構, 我在這裡分别講一下。推薦看下:為什麼索引能提高查詢速度?
B-Tree
即B樹,注意(不是B減樹),B樹是一種多路搜尋樹。使用B-Tree結構可以顯著減少定位記錄時所經曆的中間過程,進而加快存取速度。
B-Tree有如下一些特征:
1.定義任意非葉子結點最多隻有M個子節點,且M>2。
2.根結點的兒子數為[2, M]。
3.除根結點以外的非葉子結點的兒子數為[M/2, M], 向上取整 。
4.每個結點存放至少M/2-1(取上整)和至多M-1個關鍵字;(至少2個關鍵字)。
5.非葉子結點的關鍵字個數=指向兒子的指針個數-1。
6.非葉子結點的關鍵字:K[1], K[2], …, K[M-1],且K[i] <= K[i+1]。
7.非葉子結點的指針:P[1], P[2], …,P[M](其中P[1]指向關鍵字小于K[1]的子樹,P[M]指向關鍵字大于K[M-1]的子樹,其它P[i]指向關鍵字屬于(K[i-1], K[i])的子樹)。
8.所有葉子結點位于同一層。
有關b樹的一些特性:
1.關鍵字集合分布在整顆樹的所有結點之中;
2.任何一個關鍵字出現且隻出現在一個結點中;
3.搜尋有可能在非葉子結點結束;
4.其搜尋性能等價于在關鍵字全集内做一次二分查找。
B樹的搜尋:從根結點開始,對結點内的關鍵字(有序)序列進行二分查找,如果命中則結束,否則進入查詢關鍵字所屬範圍的兒子結點;重複執行這個操作,直到所對應的節點指針為空,或者已經是是葉子結點。
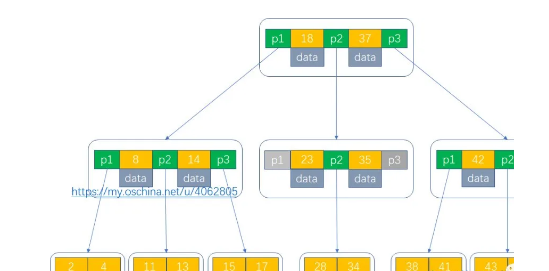
例如下面一個B樹,那麼查找元素43的過程如下:
根據根節點指針找到18、37所在節點,把此節點讀入記憶體,進行第一次磁盤IO,此時發現43>37,找到指針p3。
根據指針p3,找到42、51所在節點,把此節點讀入記憶體,進行第二次磁盤IO,此時發現42<43<51,找到指針p2。
根據指針p2,找到43、46所在節點,把此節點讀入記憶體,進行第三次磁盤IO,此時我們就已經查到了元素43。
在此過程總共進行了三次磁盤IO。
B+Tree
B+Tree屬于B-Tree的變種。與B-Tree相比,B+Tree有以下不同點:
1.有n棵子樹的非葉子結點中含有n個關鍵字(B樹是n-1個),即非葉子結點的子樹指針與關鍵字個數相同。這些關鍵字不儲存資料,隻用來索引,所有資料都儲存在葉子節點(B樹是每個關鍵字都儲存資料)。
2.所有的葉子結點中包含了全部關鍵字的資訊,及指向含這些關鍵字記錄的指針,且葉子結點本身依關鍵字的大小自小而大順序連結。
3.所有的非葉子結點可以看成是葉子節點的索引部分。
4.同一個數字會在不同節點中重複出現,根節點的最大元素就是b+樹的最大元素。

相對B樹,B+樹做索引的優勢
1.B+樹的磁盤IO代價更低:B+樹非葉子節點沒有指向資料行的指針,是以相同的磁盤容量存儲的節點數更多,相應的IO讀寫次數肯定減少了。
2.B+樹的查詢效率更加穩定:由于所有資料都存于葉子節點。所有關鍵字查詢的路徑長度相同,每一個資料的查詢效率相當。
3.所有的葉子節點形成了一個有序連結清單,更加便于查找。
關于MySQL的兩種常用存儲引擎MyISAM和InnoDB的索引均以B+樹作為資料結構,二者卻有不同(這裡隻說二者索引的差別)。推薦看下:InnoDB一棵B+樹可以存放多少行資料?
MyISAM索引和Innodb索引的差別
MyISAM使用B+樹作為索引結構,葉節點葉節點的data域儲存的是存儲資料的位址,主鍵索引key值唯一,輔助索引key可以重複,二者在結構上相同。關注微信公衆号:網際網路架構師,在背景回複:2T,可以擷取我整理的架構師全套教程,都是幹貨。
是以,MyISAM中索引檢索的算法為首先按照B+Tree搜尋算法搜尋索引,如果要找的Key存在,則取出其data域的值,然後以data域的值為位址,去讀取相應資料記錄 。是以,索引檔案和資料檔案是分開的,從索引中檢索到的是資料的位址,而不是資料。
Innodb也是用B+樹作為索引結構,但具體實作方式卻與MyISAM截然不同,首先,資料表本身就是按照b+樹組織,是以資料檔案本身就是主鍵索引檔案。葉節點key值為資料表的主鍵,data域為完整的資料記錄。
是以InnoDB表資料檔案本身就是主鍵索引(這也就是MyISAM可以允許沒有主鍵,但是Innodb必須有主鍵的原因)。第二個與MyISAM索引的不同是InnoDB的輔助索引的data域存儲相應資料記錄的主鍵值而不是位址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域。
索引類型
普通索引:(由關鍵字KEY或INDEX定義的索引)的唯一任務是加快對資料的通路速度。
唯一索引:普通索引允許被索引的資料列包含重複的值,而唯一索引不允許,但是可以為null。是以任務是保證通路速度和避免資料出現重複。
主鍵索引:在主鍵字段建立的索引,一張表隻有一個主鍵索引。
組合索引:多列值組成一個索引,專門用于組合搜尋。
全文索引:對文本的内容進行分詞,進行搜尋。(MySQL5.6及以後的版本,MyISAM和InnoDB存儲引擎均支援全文索引。)推薦看下:MySQL 索引B+樹原理,以及建索引的幾大原則。
索引的使用政策及優缺點
使用索引
主鍵自動建立唯一索引。
經常作為查詢條件在WHERE或者ORDER BY 語句中出現的列要建立索引。
查詢中與其他表關聯的字段,外鍵關系建立索引。
經常用于聚合函數的列要建立索引,如min(),max()等的聚合函數。
不使用索引
經常增删改的列不要建立索引。
有大量重複的列不建立索引。
表記錄太少不要建立索引,因為資料較少,可能查詢全部資料花費的時間比周遊索引的時間還要短,索引就可能不會産生優化效果 。
最左比對原則
建立聯合索引的時候都會預設從最左邊開始,是以索引列的順序很重要,建立索引的時候就應該把最常用的放在左邊,使用select的時候也是這樣,從最左邊的開始,依次比對右邊的。
優點
可以保證資料庫表中每一行的資料的唯一性。
可以大大加快資料的索引速度。
加速表與表之間的連接配接。
可以顯著的減少查詢中分組和排序的時間。
缺點
建立索引和維護索引要耗費時間,這種時間随着資料量的增加而增加。
索引需要占實體空間,除了資料表占用資料空間之外,每一個索引還要占用一定的實體空間,如果需要建立聚簇索引,那麼需要占用的空間會更大,其實建立索引就是以空間換時間。
表中的資料進行增、删、改的時候,索引也要動态的維護,這就降低了維護效率。
驗證索引是否能夠提升查詢性能
建立測試表index_test
最後,感謝女朋友在生活中,工作上的包容、了解與支援 !
【雲栖号線上課堂】每天都有産品技術專家分享!
課程位址:
https://yqh.aliyun.com/zhibo立即加入社群,與專家面對面,及時了解課程最新動态!
【雲栖号線上課堂 社群】
https://c.tb.cn/F3.Z8gvnK
原文釋出時間:2020-05-29
本文作者: 網際網路架構師
本文來自:“
網際網路架構師 微信公衆号”,了解相關資訊可以關注“
網際網路架構師”