本文作者 李超 阿裡雲智能 資深技術專家
編者按
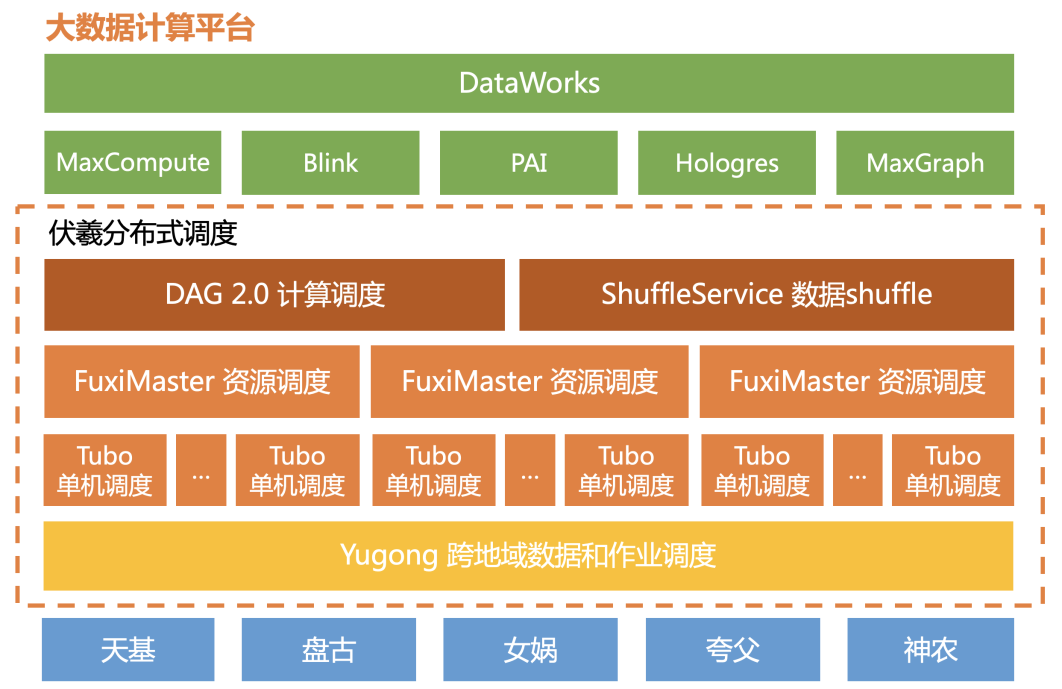
伏羲(Fuxi)是十年前最初創立飛天平台時的三大服務之一(分布式存儲 Pangu,分布式計算 MaxCompute,分布式排程 Fuxi),當時的設計初衷是為了解決大規模分布式資源的排程問題(本質上是多目标的最優比對問題)。
随阿裡經濟體和阿裡雲豐富的業務需求(尤其是雙十一)和磨練,伏羲的内涵不斷擴大,從單一的資源排程器(對标開源系統的YARN)擴充成大資料的核心排程服務,覆寫資料排程(Data Placement)、資源排程(Resouce Management)、計算排程(Application Manager)、和本地微(自治)排程(即正文中的單機排程)等多個領域,并在每一個細分領域緻力于打造超越業界主流的差異化能力。
過去十年來,伏羲在技術能力上每年都有一定的進展和突破(如2013年的5K,15年的Sortbenchmark世界冠軍,17年的超大規模離在/在離混布能力,2019年的 Yugong 釋出并論文被VLDB接受等等)。本文試從面向大資料/雲計算的排程挑戰出發,介紹各個子領域的關鍵進展,并回答什麼是“伏羲 2.0”。
1. 引言
過去10年,是雲計算的10年,伴随雲計算的爆炸式增長,大資料行業的工作方式也發生了很大的變化:從傳統的自建自運維hadoop叢集,變成更多的依賴雲上的彈性低成本計算資源。海量大資料客戶的信任和托付,對阿裡大資料系統來說,是很大的責任,但也催生出了大規模、多場景、低成本、免運維的MaxCompute通用計算系統。
同樣的10年,伴随着阿裡年年雙11,MaxCompute同樣支撐了阿裡内部大資料的蓬勃發展,從原來的幾百台,到現在的10萬台實體機規模。
雙線需求,殊途同歸,海量資源池,如何自動比對到大量不同需求的異地客戶計算需求上,需要排程系統的工作。本文主要介紹阿裡大資料的排程系統FUXI往2.0的演進。先給大家介紹幾個概念:
- 首先,資料從哪裡來?資料往往伴随着線上業務系統産生。而線上系統,出于延遲和容災的考慮,往往遍布北京、上海、深圳等多個地域,如果是跨國企業,還可能遍布歐美等多個大陸的機房。這也造成了我們的資料天然分散的形态。而計算,也可能發生在任意一個地域和機房。可是網絡,是他們中間的瓶頸,跨地域的網絡,在延遲和帶寬上,遠遠無法滿足大資料計算的需求。如何平衡計算資源、資料存儲、跨域網絡這幾點之間的平衡,需要做好“資料排程”。
- 其次,有了資料,計算還需要CPU,記憶體,甚至GPU等資源,當不同的公司,或者單個公司内部不同的部門,同時需要計算資源,而計算資源緊張時,如何平衡不同的使用者,不同的作業?作業也可能長短不一,重要程度不盡相同,今天和明天的需求也大相徑庭。除了使用者和作業,計算資源本身可能面臨硬體故障,但使用者不想受影響。所有這些,都需要“資源排程”。
- 有了資料和計算資源,如何完成使用者的計算任務,比如一個SQL query?這需要将一個大任務,分成幾個步驟,每個步驟又切分成成千上萬個小任務,并行同時計算,才能展現出分布式系統的加速優勢。但小任務切粗切細,在不同的機器上有快有慢,上下步驟如何交接資料,同時避開各自故障和長尾,這些都需要“計算排程”。
- 很多不同使用者的不同小任務,經過層層排程,最後彙集到同一台實體機上,如何避免單機上真正運作時,對硬體資源使用的各種不公平,避免老實人吃虧。避免重要關鍵任務受普通任務影響,這都需要核心層面的隔離保障機制。同時還要兼顧隔離性和性能、成本的折中考慮。這都需要“單機排程”。
2013年,伏羲在飛天5K項目中對系統架構進行了第一次大重構,解決了規模、性能、使用率、容錯等線上問題,并取得世界排序大賽Sortbenchmark四項冠軍,這标志着Fuxi 1.0的成熟。
2019年,伏羲再次出發,從技術上對系統進行了第二次重構,釋出Fuxi 2.0版本:阿裡自研的新一代高性能、分布式的資料、資源、計算、單機排程系統。Fuxi 2.0進行了全面的技術更新,在全區域資料排布、去中心化排程、線上離線混合部署、動态計算等方面全方位滿足新業務場景下的排程需求。
伏羲2.0成果概覽
• 業内首創跨地域多資料中心的資料排程方案-Yugong,通過3%的備援存儲,節省80%的跨地域網絡帶寬
• 業内領先的去中心化資源排程架構,單叢集支援10萬伺服器*10萬并發job的高頻排程
• 動态DAG闖入傳統SQL優化盲區,TPC-DS性能提升27%,conditional join性能提升3X。
• 創新性的資料動态shuffle和全局跨級優化,取代業界磁盤shuffle;線上千萬job,整體性能提升20%,成本下降15%,出錯率降低一個數量級
• 線上離線規模化混合部署,線上叢集使用率由10%提升到40%,雙十一大促節省4200台F53資源,且同時保障線上離線業務穩定。
2. 資料排程2.0 - 跨地域的資料排程
阿裡巴巴在全球都建有資料中心,每個地區每天會産生一份當地的交易訂單資訊,存在就近的資料中心。北京的資料中心,每天會運作一個定時任務來統計當天全球所有的訂單資訊,需要從其他資料中心讀取這些交易資料。當資料的産生和消費不在一個資料中心時,我們稱之為跨資料中心資料依賴(下文簡稱跨中心依賴)。

圖. 阿裡巴巴全球資料中心
MaxCompute上每天運作着數以千萬計的作業,處理EB級别的資料。這些計算和資料分布在全球的資料中心,複雜的業務依賴關系産生了大量的跨中心依賴。相比于資料中心内的網絡,跨資料中心網絡(尤其是跨域的網絡)是非常昂貴的,同時具有帶寬小、延遲高、穩定性低的特點。比如網絡延遲,資料中心内部網絡的網絡延遲一般在100微秒以下,而跨地域的網絡延遲則高達數十毫秒,相差百倍以上。是以,如何高效地将跨中心依賴轉化為資料中心内部的資料依賴,減少跨資料中心網絡帶寬消耗,進而降低成本、提高系統效率,對MaxCompute這樣超大規模計算平台而言,具有極其重要的意義。
圖. MaxCompute平台資料及依賴增長趨勢
為了解決這個問題,我們在資料中心上增加了一層排程層,用于在資料中心之間排程資料和計算。這層排程獨立于資料中心内部的排程,目的是實作跨地域次元上存儲備援--計算均衡--長傳帶寬--性能最優之間的最佳平衡。這層排程層包括跨資料中心資料緩存、業務整體排布、作業粒度排程。
首先是對通路頻次高的資料進行跨資料中心緩存,在緩存空間有限的限制下,選擇合适的資料進行換入換出。不同于其他緩存系統,MaxCompute的資料(分區)以表的形式組織在一起,每張表每天産生一個或多個分區,作業通路資料也有一些特殊規律,比如一般通路的是連續分區、生成時間越新的分區通路機率越大。
其次是業務的整體排布政策。資料和計算以業務為機關組織在一起(MaxCompute中稱之為project),每個project被配置設定在一個資料中心,包括資料存儲和計算作業。如果将project看做一個整體,可以根據作業對資料的依賴關系計算出project之間的互相依賴關系。如果能将有互相資料依賴的project放在一個資料中心,就可以減少跨中心依賴。但project間的依賴往往複雜且不斷變化,很難有一勞永逸的排布政策,并且project排布需要對project進行整體遷移,周期較長,且需要消耗大量的帶寬。
最後,當project之間的互相依賴集中在極少數幾個作業上,并且作業的輸入資料量遠大于輸出資料量時,比起資料緩存和project整體遷移,更好的辦法是将這些作業排程到資料所在的資料中心,再将作業的輸出遠端寫回原資料中心,即作業粒度排程。如何在作業運作之前就預測到作業的輸入輸出資料量和資源消耗,另一方面當作業排程到remote資料中心後,如何保證作業運作不會變慢,不影響使用者體驗,這都是作業粒度排程要解決的問題。
本質上,資料緩存、業務排布、作業粒度排程三者都在解同一個問題,即在跨地域多資料中心系統中減少跨中心依賴量、優化作業的data locality、減少網絡帶寬消耗。
1.2.1 跨資料中心資料緩存政策
我們首次提出了跨地域、跨資料中心資料緩存這一概念,通過叢集的存儲換叢集間帶寬,在有限的備援存儲下,找到存儲和帶寬最佳的tradeoff。通過深入的分析MaxCompute的作業、資料的特點,我們設計了一種高效的算法,根據作業曆史的workload、資料的大小和分布,自動進行緩存的換入換出。
我們研究了多種資料緩存算法,并對其進行了對比試驗,下圖展示了不同緩存政策的收益,橫軸是備援存儲空間,縱軸是帶寬消耗。從圖中可以看出,随着備援存儲的增加,帶寬成本不斷下降,但收益比逐漸降低,我們最終采用的k-probe算法在存儲和帶寬間實作了很好的平衡。
1.2.2 以project為粒度的多叢集業務排布算法
随着上層業務的不斷發展,業務的資源需求和資料需求也在不斷變化。比如一個叢集的跨中心依賴增長迅速,無法完全通過資料緩存來轉化為本地讀取,這就會造成大量的跨資料中心流量。是以我們需要定期對業務的排布進行分析,根據業務對計算資源、資料資源的需求情況,以及叢集、機房的規劃,通過業務的遷移來降低跨中心依賴以及均衡各叢集壓力。
下圖展示了某個時刻業務遷移的收益分析:左圖橫軸為遷移的project數量,縱軸為帶寬減少比例,可以看出大約移動60個project就可以減少約30%的帶寬消耗。右圖統計了不同排布下(遷移0個、20個、50個project)的最優帶寬消耗,橫軸為備援存儲,縱軸為帶寬。
1.2.3 跨資料中心計算排程機制
我們打破了計算資源按照資料中心進行規劃的限制,理論上允許作業跑在任何一個資料中心。我們将排程粒度拆解到作業粒度,根據每個作業的資料需求、資源需求,為其找到一個最合适的資料中心。在對作業進行排程之前需要知道這個作業的輸入和輸出,目前我們有兩種方式獲得這一資訊,對于周期性作業,通過對作業曆史運作資料進行分析推測出作業的輸入輸出;對于偶發的作業,我們發現其産生較大跨域流量時,動态的将其排程到資料所在的資料中心上運作。另外,排程計算還要考慮作業對計算資源的需求,防止作業全部排程到熱點資料所在的資料中心,造成任務堆積。
1.3 線上效果
線上三種政策相輔相成,資料緩存主要解決周期類型作業、熱資料的依賴;作業粒度排程主要解決臨時作業、曆史資料的依賴;并周期性地通過業務整體排布進行全局優化,用來降低跨中心依賴。整體來看,通過三種政策的共同作用,降低了約90%的跨地域資料依賴,通過約3%的備援存儲節省了超過80%的跨資料中心帶寬消耗,将跨中心依賴轉化為本地讀取的比例提高至90%。下圖以機房為機關展示了帶寬的收益:
3. 資源排程2.0 - 去中心化的多排程器架構
2019年雙十一,MaxCompute平台産生的資料量已接近EB級别,作業規模達到了千萬,有幾十億的worker跑在幾百萬核的計算單元上,在超大規模(單叢集超過萬台),高并發的場景下,如何快速地給不同的計算任務配置設定資源,實作資源的高速流轉,需要一個聰明的“大腦”,而這就是叢集的資源管理與排程系統(簡稱資源排程系統)。
資源排程系統負責連接配接成千上萬的計算節點,将資料中心海量的異構資源抽象,并提供給上層的分布式應用,像使用一台電腦一樣使用叢集資源,它的核心能力包括規模、性能、穩定性、排程效果、多租戶間的公平性等等。一個成熟的資源排程系統需要在以下五個方面進行權衡,做到“既要又要”,非常具有挑戰性。
13年的5K項目初步證明了伏羲規模化能力,此後資源排程系統不斷演進,并通過MaxCompute平台支撐了阿裡集團的大資料計算資源需求,在核心排程名額上保持着對開源系統的領先性,比如1)萬台規模叢集,排程延時控制在了10微秒級别,worker啟動延時控制在30毫秒;2)支援任意多級租戶的資源動态調節能力(支援十萬級别的租戶);3)極緻穩定,排程服務全年99.99%的可靠性,并做到服務秒級故障恢複。
2.1 單排程器的局限性
2.1.1 線上的規模與壓力
大資料計算的場景與需求正在快速增長(下圖是過去幾年MaxComputer平台計算和資料的增長趨勢)。單叢集早已突破萬台規模,急需提供十萬台規模的能力。
圖. MaxCompute 2015 ~ 2018線上作業情況
但規模的增長将帶來複雜度的極速上升,機器規模擴大一倍,資源請求并發度也會翻一番。在保持既有性能、穩定性、排程效果等核心能力不下降的前提下,可以通過對排程器持續性能優化來擴充叢集規模(這也是伏羲資源排程1.0方向),但受限于單機的實體限制,這種優化總會存在天花闆,是以需要從架構上優化來徹底規模和性能的可擴充性問題。
2.1.2 排程需求的多樣性
伏羲支援了各種各樣的大資料計算引擎,除了離線計算(SQL、MR),還包括實時計算、圖計算,以及近幾年迅速發展面向人工智能領域的機器學習引擎。
圖. 資源排程器的架構類型
場景的不同對資源排程的需求也不相同,比如,SQL類型的作業通常體積小、運作時間短,對資源比對的要求低,但對排程延時要求高,而機器學習的作業一般體積大、運作時間長,排程結果的好壞可能對運作時間産生直接影響,是以也能容忍通過較長的排程延時換取更優的排程結果。資源排程需求這種多樣性,決定了單一排程器很難做到“面面俱到”,需要各個場景能定制各自的排程政策,并進行獨立優化。
2.1.3 灰階釋出與工程效率
資源排程系統是分布式系統中最複雜最重要的的子產品之一,需要有嚴苛的生産釋出流程來保證其線上穩定運作。單一的排程器對開發人員要求高,出問題之後影響範圍大,測試釋出周期長,嚴重影響了排程政策疊代的效率,在快速改進各種場景排程效果的過程中,這些弊端逐漸顯現,是以急需從架構上改進,讓資源排程具備線上的灰階能力,進而幅提升工程效率。
2.2 去中心化的多排程器架構
為了解決上述規模和擴充性問題,更好地滿足多種場景的排程需求,同時從架構上支援灰階能力,伏羲資源排程2.0在1.0的基礎上對排程架構做了大規模的重構,引入了去中心化的多排程器架構。
圖. 資源排程的架構類型
我們将系統中最核心的資源管理和資源排程邏輯進行了拆分解耦,使兩者同時具備了多partition的可擴充能力(如下圖所示),其中:
• 資源排程器(Scheduler):負責核心的機器資源和作業資源需求比對的排程邏輯,可以橫向擴充。
• 資源管理和仲裁服務(ResourceManagerService,簡稱RMS):負責機器資源和狀态管理,對各個Scheduler的排程結果進行仲裁,可以橫向擴充。
• 排程協調服務(Coordinator):管理資源排程系統的配置資訊,Meta資訊,以及對機器資源、Scheduler、RMS的可用性和服務角色間的可見性做仲裁。不可橫向擴充,但有秒級多機主備切換能力。
• 排程資訊收集監控服務(FuxiEye):統計叢集中每台機的運作狀态資訊,給Scheduler提供排程決策支援,可以橫向擴充。
• 使用者接口服務(ApiServer):為資源排程系統提供外部調用的總入口,會根據Coordinator提供的Meta資訊将使用者請求路由到資源排程系統具體的某一個服務上,可以橫向擴充。
圖. 伏羲多排程器新架構
2.3 上線資料
以下是10w規模叢集/10萬作業并發場景排程器核心名額(5個Scheduler、5個RMS,單RMS負責2w台機器,單Scheduler并發處理2w個作業)。通過資料可以看到,叢集10w台機器的排程使用率超過了99%,關鍵排程名額,單Scheduler向RMS commit的slot的平均數目達到了1w slot/s。
在保持原有單排程器各項核心名額穩定不變的基礎上,去中心化的多排程器架構實作了機器規模和應用并發度的雙向擴充,徹底解決了叢集的可擴充性問題。
目前資源排程的新架構已全面上線,各項名額持續穩定。在多排程器架構基礎上,我們把機器學習場景排程政策進行了分離,通過獨立的排程器來進行持續的優化。同時通過測試專用的排程器,我們也讓資源排程具備了灰階能力,排程政策的開發和上線周期顯著縮短。
4. 計算排程2.0 - 從靜态到動态
分布式作業的執行與單機作業的最大差別,在于資料的處理需要拆分到不同的計算節點上,“分而治之”的執行。這個“分”,包括資料的切分,聚合以及對應的不同邏輯運作階段的區分,也包括在邏輯運作階段間資料的shuffle傳輸。每個分布式作業的中心管理點,也就是application master (AM)。這個管理節點也經常被稱為DAG (Directional Acyclic Graph, 有向無環圖) 元件,是因為其最重要的責任,就是負責協調分布式系統中的作業執行流程,包括計算節點的排程以及資料流(shuffle)。
對于作業的邏輯階段和各個計算節點的管理, 以及shuffle政策的選擇/執行,是一個分布式作業能夠正确完成重要前提。這一特點,無論是傳統的MR作業,分布式SQL作業,還是分布式的機器學習/深度學習作業,都是一脈相承的,為了幫助更好的了解計算排程(DAG和Shuffle)在大資料平台中的位置,我們可以通過MaxCompute分布式SQL的執行過程做為例子來了解:
在這麼一個簡單的例子中,使用者有一張訂單表order_data,存儲了海量的交易資訊,使用者想所有查詢花費超過1000的交易訂單按照userid聚合後,每個使用者的花費之和是多少。于是送出了如下SQL query:
INSERT OVERWRITE TABLE result
SELECT userid, SUM(spend)
FROM order_data
WHERE spend > 1000
GROUP BY userid; 這個SQL經過編譯優化之後生成了優化執行計劃,送出到fuxi管理的分布式叢集中執行。我們可以看到,這個簡單的SQL經過編譯優化,被轉換成一個具有M->R兩個邏輯節點的DAG圖,也就是傳統上經典的MR類型作業。而這個圖在送出給fuxi系統後,根據每個邏輯節點需要的并發度,資料傳輸邊上的shuffle方式,排程時間等等資訊,就被物化成右邊的實體執行圖。實體圖上的每個節點都代表了一個具體的執行執行個體,執行個體中包含了具體處理資料的算子,特别的作為一個典型的分布式作業,其中包含了資料交換的算子shuffle——負責依賴外部存儲和網絡交換節點間的資料。一個完整的計算排程,包含了上圖中的DAG的排程執行以及資料shuffle的過程。
阿裡計算平台的fuxi計算排程,經過十年的發展和不斷疊代,成為了作為阿裡集團内部以及阿裡雲上大資料計算的重要基礎設施。今天計算排程同時服務了以MaxCompute SQL和PAI為代表的多種計算引擎,在近10萬台機器上日均運作着千萬界别的分布式DAG作業,每天處理EB數量級的資料。一方面随着業務規模和需要處理的資料量的爆發,這個系統需要服務的分布式作業規模也在不斷增長;另一方面,業務邏輯以及資料來源的多樣性,計算排程在阿裡已經很早就跨越了不同規模上的可用/夠用的前中期階段,2.0上我們開始探索更加前沿的智能化執行階段。
在雲上和阿裡集團的大資料實踐中,我們發現對于計算排程需要同時具備超大規模和智能化的需求,以此為基本訴求我們開了Fuxi計算排程2.0的研發。下面就為大家從DAG排程和資料shuffle兩個方面分别介紹計算排程2.0的工作。
4.1 Fuxi DAG 2.0--動态、靈活的分布式計算生态
4.1.1 DAG排程的挑戰
傳統的分布式作業DAG,一般是在作業送出前靜态指定的,這種指定方式,使得作業的運作沒有太多動态調整的空間。放在DAG的邏輯圖與實體圖的背景中來說,這要求分布式系統在運作作業前,必須事先了解作業邏輯和處理資料各種特性,并能夠準确回答作業運作過程,各個節點和連接配接邊的實體特性問題,然而在現實情況中,許多和運作過程中資料特性相關的問題,都隻有個在執行過程中才能被最準确的獲得。靜态的DAG執行,可能導緻選中的是非最優的執行計劃,進而導緻各種運作時的效率低下,甚至作業失敗。這裡我們可以用一個分布式SQL中很常見的例子來說明:
SELECT a.spend, a.userid, b.age
FROM (
SELECT spend, userid
FROM order_data
WHERE spend > 1000
) a
JOIN (
SELECT userid, age
FROM user
WHERE age > 60
) b
ON a.userid = b.userid; 上面是一個簡單的join的例子,目的是擷取60歲以上使用者花費大于1000的詳細資訊,由于年紀和花費在兩張表中,是以此時需要做一次join。一般來說join有兩種實作方式:
一是Sorted Merge Join(如下圖左側的所示):也就是對于a和b兩個子句執行後的資料按照join key(userid)進行分區,然後在下遊節點按照相同的key進行Merge Join操作,實作Merge Join需要對兩張表都要做shuffle操作——也就是進行一次資料狡猾,特别的如果有資料傾斜(例如某個userid對應的交易記錄特别多),這時候MergeJoin過程就會出現長尾,影響執行效率;
二是實作方式是Map join(Hash join)的方式(如下圖右側所示):上述sql中如果60歲以上的使用者資訊較少,資料可以放到一個計算節點的記憶體中,那對于這個超小表可以不做shuffle,而是直接将其全量資料broadcast到每個處理大表的分布式計算節點上,大表不用進行shuffle操作,通過在記憶體中直接建立hash表,完成join操作,由此可見map join優化能大量減少 (大表) shuffle同時避免資料傾斜,能夠提升作業性能。但是如果選擇了map join的優化,執行過程中發現小表資料量超過了記憶體限制(大于60歲的使用者很多),這個時候query執行就會由于oom而失敗,隻能重新執行。
但是在實際執行過程中,具體資料量的大小,需要在上遊節點完成後才能被感覺,是以在送出作業前很難準确的判斷是否可以采用Map join優化,從上圖可以看出在Map Join和Sorted Merge Join上DAG圖是兩種結構,是以這需要DAG排程在執行過程中具有足夠的動态性,能夠動态的修改DAG圖來達到執行效率的最優。我們在阿裡集團和雲上海量業務的實踐中發現,類似map join優化的這樣的例子是很普遍的,從這些例子可以看出,随着大資料平台優化的深入進行,對于DAG系統的動态性要求越來越高。
由于業界大部分DAG排程架構都在邏輯圖和實體圖之間沒有清晰的分層,缺少執行過程中的動态性,無法滿足多種計算模式的需求。例如spark社群很早提出了運作時調整Join政策的需求(Join: Determine the join strategy (broadcast join or shuffle join) at runtime),但是目前仍然沒有解決。
除此上述使用者體感明顯的場景之外,随着MaxCompute計算引擎本身更新換代和優化器能力的增強,以及PAI平台的新功能演進,上層的計算引擎自身能力在不斷的增強。對于DAG元件在作業管理,DAG執行等方面的動态性,靈活性等方面的需求也日益強烈。在這樣的一個大的背景下,為了支撐計算平台下個10年的發展,伏羲團隊啟動了DAG 2.0的項目,在更好的支撐上層計算需求。
4.1.2 DAG2.0 動态靈活統一的執行架構
DAG2.0通過邏輯圖和實體圖的清晰分層,可擴充的狀态機管理,插件式的系統管理,以及基于事件驅動的排程政策等基座設計,實作了對計算平台上多種計算模式的統一管理,并更好的提供了作業執行過程中在不同層面上的動态調整能力。作業執行的動态性和統一DAG執行架構是DAG2.0的兩個主要特色:
作業執行的動态性
如前所訴,分布式作業執行的許多實體特性相關的問題,在作業運作前是無法被感覺的。例如一個分布式作業在運作前,能夠獲得的隻有原始輸入的一些基本特性(資料量等), 對于一個較深的DAG執行而言,這也就意味着隻有根節點的實體計劃(并發度選擇等) 可能相對合理,而下遊的節點和邊的實體特性隻能通過一些特定的規則來猜測。這就帶來了執行過程中的不确定性,是以,要求一個好的分布式作業執行系統,需要能夠根據中間運作結果的特點,來進行執行過程中的動态調整。
而DAG/AM作為分布式作業唯一的中心節點和排程管控節點,是唯一有能力收集并聚合相關資料資訊,并基于這些資料特性來做作業執行的動态調整。這包括簡單的實體執行圖調整(比如動态的并發度調整),也包括複雜一點的調整比如對shuffle方式和資料編排方式重組。除此以外,資料的不同特點也會帶來邏輯執行圖調整的需求:對于邏輯圖的動态調整,在分布式作業進行中是一個全新的方向,也是我們在DAG 2.0裡面探索的新式解決方案。
還是以map join優化作為例子,由于map join與預設join方式(sorted merge join)對應的其實是兩種不同優化器執行計劃,在DAG層面,對應的是兩種不同的邏輯圖。DAG2.0的動态邏輯圖能力很好的支援了這種運作過程中根據中間資料特性的動态優化,而通過與上層引擎優化器的深度合作,在2.0上實作了業界首創的conditional join方案。如同下圖展示,在對于join使用的算法無法被事先确定的時候,分布式排程執行架構可以允許優化送出一個conditional DAG,這樣的DAG同時包括使用兩種不同join的方式對應的不同執行計劃支路。在實際執行時,AM根據上遊産出資料量,動态選擇一條支路執行(plan A or plan B)。這樣子的動态邏輯圖執行流程,能夠保證每次作業運作時,根據實際産生的中間資料特性,選擇最優的執行計劃。在這個例子中,
- 當M1輸出的資料量較小時,允許其輸出被全量載入下遊單個計算節點的記憶體,DAG就會選擇優化的map join(plan A),來避免額外的shuffle和排序。
- 當M1輸出的資料量大到一定程度,已經不屬于map join的适用範圍,DAG就可以自動選擇走merge join,來保證作業的成功執行。
除了map join這個典型場景外,借助DAG2.0的動态排程能力,MaxCompute在解決其他使用者痛點上也做了很多探索,并取得了不錯的效果。例如智能動态并發度調整:在執行過程中依據分區資料統計調整,動态調整并發度;自動合并小分區,避免不必要的資源使用,節約使用者資源使用;切分大分區,避免不必要的長尾出現等等。
統一的AM/DAG執行架構
除了動态性在SQL執行中帶來的重大性能提升外,DAG 2.0抽象分層的點,邊,圖架構上,也使其能通過對點和邊上不同實體特性的描述,對接不同的計算模式。業界各種分布式資料處理引擎,包括SPARK, FLINK, HIVE, SCOPE, TENSORFLOW等等,其分布式執行架構的本源都可以歸結于Dryad提出的DAG模型。我們認為對于圖的抽象分層描述,将允許在同一個DAG系統中,對于離線/實時/流/漸進計算等多種模型都可以有一個好的描述。
如果我們對分布式SQL進行細分的話,可以看見業界對于不同場景上的優化經常走在兩個極端:要麼優化throughput (大規模,相對高延時),要麼優化latency(中小資料量,迅速完成)。前者以Hive為典型代表,後者則以Spark以及各種分布式MPP解決方案為代表。而在阿裡分布式系統的發展過程中,曆史上同樣出現了兩種對比較為顯著的執行方式:SQL線離線(batch)作業與準實時(interactive)作業。這兩種模式的資源管理和作業執行,過去是搭建在兩套完全分開的代碼實作上的。這除了導緻兩套代碼和功能無法複用以外,兩種計算模式的非黑即白,使得彼此在資源使用率和執行性能之間無法tradeoff。而在DAG 2.0模型上,通過對點/邊實體特性的映射,實作了這兩種計算模式比較自然的融合和統一。離線作業和準實時作業在邏輯節點和邏輯邊上映射不同的實體特性後,都能得到準确的描述:
- 離線作業:每個節點按需去申請資源,一個邏輯節點代表一個排程機關;節點間連接配接邊上傳輸的資料,通過落盤的方式來保證可靠性;
- 準實時作業:整個作業的所有節點都統一在一個排程機關内進行gang scheduling;節點間連接配接邊上通過網絡/記憶體直連傳輸資料,并利用資料pipeline來追求最優的性能。
在此統一離線作業與準實時作業的到一套架構的基礎上,這種統一的描述方式,使得探索離線作業高資源使用率,以及準實時作業的高性能之間的tradeoff成為可能:當排程機關可以自由調整,就可以實作一種全新的混合的計算模式,我們稱之為Bubble執行模式。
這種混合Bubble模式,使得DAG的使用者,也就是上層計算引擎的開發者(比如MaxCompute的優化器),能夠結合執行計劃的特點,以及引擎終端使用者對資源使用和性能的敏感度,來靈活選擇在執行計劃中切出Bubble子圖。在Bubble内部充分利用網絡直連和計算節點預熱等方式提升性能,沒有切入Bubble的節點則依然通過傳統離線作業模式運作。在統一的新模型之上,計算引擎和執行架構可以在兩個極端之間,根據具體需要,選擇不同的平衡點。
4.1.3 效果
DAG2.0的動态性使得很多執行優化可以運作時決定,使得實際執行的效果更優。例如,在阿裡内部的作業中,動态的conditional join相比靜态的執行計劃,整體獲得了将近3X的性能提升。
混合Bubble執行模式平衡了離線作業高資源使用率以及準實時作業的高性能,這在1TB TPCH測試集上有顯著的展現,
- Bubble相對離線作業:在多使用20%資源的情況下,Bubble模式性能提升将近一倍;
- Bubble相對準實時模式:在節省了2.6X資源情況下, Bubble性能僅下降15%;
4.2 Fuxi Shuffle 2.0 - 磁盤記憶體網絡的最佳使用
4.2.1 背景
大資料計算作業中,節點間的資料傳遞稱為shuffle, 主流分布式計算系統都提供了資料shuffle服務的子系統。如前述DAG計算模型中,task間的上下遊資料傳輸就是典型的shuffle過程。
在資料密集型作業中,shuffle階段的時間和資源使用占比非常高,有其他大資料公司研究顯示,在大資料計算平台上Shuffle階段均是在所有作業的資源使用中占比超過50%. 根據統計在MaxCompute生産中shuffle占作業運作時間和資源消耗的30-70%,是以優化shuffle流程不但可以提升作業執行效率,而且可以整體上降低資源使用,節約成本,提升MaxCompute在雲計算市場的競争優勢。
從shuffle媒體來看,最廣泛使用的shuffle方式是基于磁盤檔案的shuffle. 這種模式這種方式簡單,直接,通常隻依賴于底層的分布式檔案系統,适用于所有類型作業。而在典型的常駐記憶體的實時/準實時計算中,通常使用網絡直連shuffle的方式追求極緻性能。Fuxi Shuffle在1.0版本中将這兩種shuffle模式進行了極緻優化,保障了日常和高峰時期作業的高效穩定運作。
挑戰
我們先以使用最廣泛的,基于磁盤檔案系統的離線作業shuffle為例。
通常每個mapper生成一個磁盤檔案,包含了這個mapper寫給下遊所有reducer的資料。而一個reducer要從所有mapper所寫的檔案中,讀取到屬于自己的那一小塊。右側則是一個系統中典型規模的MR作業,當每個mapper處理256MB資料,而下遊reducer有10000個時,平均每個reducer讀取來自每個mapper的資料量就是25.6KB, 在機械硬碟HDD為媒體的存儲系統中,屬于典型的讀碎片現象,因為假設我們的磁盤iops能達到1000, 對應的throughput也隻有25MB/s, 嚴重影響性能和磁盤壓力。
【基于檔案系統shuffle的示意圖 / 一個20000*10000的MR作業的碎片讀】
分布式作業中并發度的提升往往是加速作業運作的最重要手段之一。但處理同樣的資料量,并發度越高意味着上述碎片讀現象越嚴重。通常情況下選擇忍受一定的碎片IO現象而在叢集規模允許的情況下提升并發度,還是更有利于作業的性能。是以碎片IO現象線上上普遍存在,磁盤也處于較高的壓力水位。
一個線上的例子是,某些主流叢集單次讀請求size為50-100KB, Disk util名額長期維持在90%的警戒線上。這些限制了對作業規模的進一步追求。
我們不禁考慮,作業并發度和磁盤效率真的不能兼得嗎?
4.2.2 Fuxi的答案:Fuxi Shuffle 2.0
引入Shuffle Service - 高效管理shuffle資源
為了針對性地解決上述碎片讀問題及其引發的一連串負面效應,我們全新打造了基于shuffle service的shuffle模式。Shuffle service的最基本工作方式是,在叢集每台機器部署一個shuffle
agent節點,用來歸集寫給同一reducer的shuffle資料。如下圖
可以看到,mapper生成shuffle資料的過程變為mapper将shuffle資料通過網絡傳輸給每個reducer對應的shuffle agent, 而shuffle agent歸集一個reducer來自所有mapper的資料,并追加到shuffle磁盤檔案中,兩個過程是流水線并行化起來的。
Shuffle agent的歸集功能将reducer的input資料從碎片變為了連續資料檔案,對HDD媒體相當友好。由此,整個shuffle過程中對磁盤的讀寫均為連續通路。從标準的TPCH等測試中可以看到不同場景下性能可取得百分之幾十到幾倍的提升,且大幅降低磁盤壓力、提升CPU等資源使用率。
Shuffle Service的容錯機制
Shuffle service的歸集思想在公司内外都有不同的工作展現類似的思想,但都限于“跑分”和小範圍使用。因為這種模式對于各環節的錯誤天生處理困難。
以shuffle agent檔案丢失/損壞是大資料作業的常見問題為例,傳統的檔案系統shuffle可以直接定位到出錯的資料檔案來自哪個mapper,隻要重跑這個mapper即可恢複。但在前述shuffle service流程中,由于shuffle agent輸出的shuffle這個檔案包含了來自所有mapper的shuffle資料,損壞檔案的重新生成需要以重跑所有mapper為代價。如果這種機制應用于所有線上作業,顯然是不可接受的。
我們設計了資料雙副本機制解決了這個問題,使得大多數通常情況下reducer可以讀取到高效的agent生成的資料,而當少數agent資料丢失的情況,可以讀取備份資料,備份資料的重新生成隻依賴特定的上遊mapper.
具體來說,mapper産生的每份shuffle資料除了發送給對于shuffle agent外,也會按照與傳統檔案系統shuffle資料類似的格式,在本地寫一個備份。按前面所述,這份資料寫的代價較小但讀取的性能不佳,但由于僅在shuffle agent那個副本出錯時才會讀到備份資料,是以對作業整體性能影響很小,也不會引起叢集級别的磁盤壓力升高。
有效的容錯機制使得shuffle service相對于檔案系統shuffle,在提供更好的作業性能的同時,因shuffle資料出錯的task重試比例降低了一個數量級,給線上全面投入使用打好了穩定性基礎。
線上生産環境的極緻性能穩定性
在前述基礎功能之上,Fuxi線上的shuffle系統應用了更多功能和優化,在性能、成本、穩定性等友善取得了進一步的提升。舉例如下。
1. 流控和負載均衡
前面的資料歸集模型中,shuffle agent作為新角色銜接了mapper的資料發送與資料落盤。分布式叢集中磁盤、網絡等問題可能影響這條鍊路上的資料傳輸,節點本身的壓力也可能影響shuffle agent的工作狀态。當因叢集熱點等原因使得shuffle agent負載過重時,我們提供了必要的流控措施緩解網絡和磁盤的壓力;和模型中一個reducer有一個shuffle agent收集資料不同,我們使用了多個shuffle agent承擔同樣的工作,當發生資料傾斜時,這個方式可以有效地将壓力分散到多個節點上。從線上表現看,這些措施消除了絕大多數的shuffle期間擁塞流控和叢集負載不均現象。
2. 故障shuffle
agent的切換
各種軟硬體故障導緻shuffle agent對某個reducer的資料工作不正常時,後續資料可以實時切換到其他正常shuffle agent. 這樣,就會有更多的資料可以從shuffle agent側讀到,而減少低效的備份副本通路。
3. Shuffle agent資料的回追
很多時候發生shuffle
agent切換時(如機器下線),原shuffle agent生成的資料可能已經丢失或通路不到。在後續資料發送到新的shuffle agent同時,Fuxi還會将丢失的部分資料從備份副本中load起來并同樣發送給新的shuffle agent, 使得後續reducer所有的資料都可以讀取自shuffle agent側,極大地提升了容錯情況下的作業性能。
4. 新shuffle模式的探索
前述資料歸集模型及全面擴充優化,線上上叢集中機關資源處理的資料量提升了約20%, 而因出錯重試的發生頻率降至原來檔案系統shuffle的5%左右。但這就是最高效的shuffle方式了嗎?
我們在生産環境對部分作業應用了一種新的shuffle模型,這種模型中mapper的發送端和reducer的接收端都通過一個agent節點來中轉shuffle流量。線上已經有部分作業使用此種方式并在性能上得到了進一步的提升。
記憶體資料shuffle
離線大資料作業可能承擔了主要的計算資料量,但流行的大資料計算系統中有非常多的場景是通過實時/準實時方式運作的,作業全程的資料流動發生在網絡和記憶體,進而在有限的作業規模下取得極緻的運作性能,如大家熟悉的Spark, Flink等系統。
Fuxi DAG也提供了實時/準實時作業運作環境,傳統的shuffle方式是通過網絡直連,也能收到明顯優于離線shuffle的性能。這種方式下,要求作業中所有節點都要排程起來才能開始運作,限制了作業的規模。而實際上多數場景計算邏輯生成shuffle資料的速度不足以填滿shuffle帶寬,運作中的計算節點等待資料的現象明顯,性能提升付出了資源浪費的代價。
我們将shuffle service應用到記憶體存儲中,以替換network傳輸的shuffle方式。一方面,這種模式解耦了上下遊排程,整個作業不再需要全部節點同時拉起;另一方面通過精确預測資料的讀寫速度并适時排程下遊節點,可以取得與network傳輸shuffle相當的作業性能,而資源消耗降低50%以上。這種shuffle方式還使得DAG系統中多種運作時調整DAG的能力可以應用到實時/準實時作業中。
4.2.3 收益
Fuxi Shuffle 2.0全面上線生産叢集,處理同樣資料量的作業資源比原來節省15%,僅shuffle方式的變化就使得磁盤壓力降低23%,作業運作中發生錯誤重試的比例降至原來的5%。
【線上典型叢集的性能與穩定性提升示意圖(不同組資料表示不同叢集)】
對使用記憶體shuffle的準實時作業,我們在TPCH等标準測試集中與網絡shuffle性能相當,資源使用隻有原來的30%左右,且支援了更大的作業規模,和DAG 2.0系統更多的動态排程功能應用至準實時作業。
5. 單機排程
大量分布式作業彙集到一台機器上,如何将單機有限的各種資源合理配置設定給每個作業使用,進而達到作業運作品質、資源使用率、作業穩定性的多重保障,是單機排程要解決的任務。
典型的網際網路公司業務一般區分為離線業務與線上業務兩種類型。在阿裡巴巴,我們也同樣有線上業務如淘寶、天貓、釘釘、Blink等,這類業務的特點是對響應延遲特别敏感,一旦服務抖動将會出現添加購物車失敗、下單失敗、浏覽卡頓、釘釘消息發送失敗等各種異常情況,嚴重影響使用者體驗,同時為了應對在618、雙11等各種大促的情況,需要提前準備大量的機器。由于以上種種原因,日常狀态這些機器的資源使用率不足10%,産生資源浪費的情況。與此同時,阿裡的離線業務又是另外一幅風景,MaxCompute計算平台承擔了阿裡所有大資料離線計算業務類型,各個叢集資源使用率常态超負載運作,資料量和計算量每年都在保持高速增長。
一方面是線上業務資源使用率不足,另一方面是離線計算長期超負載運作,那麼能否将線上業務與離線計算進行混合部署,提升資源使用率同時大幅降低成本,實作共赢。
5.1 三大挑戰
-
如何保障線上服務品質
線上叢集的平均CPU使用率隻有10%左右,混部的目标就是将剩餘的資源提供給MaxCompute進行離線計算使用,進而達到節約成本的目的。那麼,如何能夠保障資源使用率提升的同時又能夠保護線上服務不受影響呢?
-
如何保障離線穩定
當資源發生沖突時,第一反應往往是保護線上,犧牲離線。畢竟登不上淘寶天貓下不了單可是大故障。可是,離線如果無限制的犧牲下去,服務品質将會出現大幅度下降。試想,我在dataworks上跑個SQL,之前一分鐘就出結果,現在十幾分鐘甚至一個小時都跑不出來,大資料分析的同學估計也受不了了。
-
如何衡量資源品質
電商業務通過富容器的方式內建多種容器粒度的分析手段,但是前文描述過離線作業的特點,如何能夠精準的對離線作業資源使用進行資源畫像分析,如果能夠評估資源受幹擾的程度,混部叢集的穩定性等問題,是對我們的又一個必須要解決的挑戰
5.2 資源隔離分級管理
單機的實體資源總是有限的,按照資源特性可以大體劃分為可伸縮資源與不可伸縮資源兩大類。CPU、Net、IO等屬于可伸縮資源,Memory屬于不可伸縮資源,不同類型的資源有不同層次的資源隔離方案。另一方面,通用叢集中作業類型種類繁多,不同作業類型對資源的訴求是不同的。這裡包括線上、離線兩個大類的資源訴求,同時也包含了各自内部不同層次的優先級二次劃分需求,十分複雜。
基于此,Fuxi2.0提出了一套基于資源優先級的資源劃分邏輯,在資源使用率、多層次資源保障複雜需求尋找到了解決方案。
下面我們将針對CPU分級管理進行深入描述,其他次元資源管理政策我們将在今後的文章中進行深入介紹。
CPU分級管理
通過精細的組合多種核心政策,将CPU區分為高、中、低三類優先級
隔離政策如下圖所示
基于不同類型的資源對應不同的優先級作業
5.3 資源畫像
Fuxi作為資源排程子產品,對資源使用情況的精準畫像是衡量資源配置設定,調查/分析/解決解決資源問題的關鍵。針對線上作業的資源情況,集團和業界都有較多的解決方案。這類通用的資源采集角色存在以下無法解決的問題無法應用于離線作業資源畫像的資料采集階段
1. 采集時間精度過低。大部分資訊是分鐘級别,而MaxCompute作業大部分運作時間在秒級。
2. 無法定位MaxCompute資訊。MaxCompute是基于Cgroup資源隔離,是以以上工具無法針對作業進行針對性采集
3. 采集名額不足。有大量新核心新增的微觀名額需要進行收集,過去是不支援的
為此,我們提出了FuxiSensor的資源畫像方案,架構如上圖所示,同時利用SLS進行資料的收集和分析。在叢集、Job作業、機器、worker等不同層次和粒度實作了資源資訊的畫像,實作了秒級的資料采集精度。在混部及MaxCompute的實踐中,成為資源問題監控、報警、穩定性資料分析、作業異常診斷、資源監控狀況的統一入口,成為混部成功的關鍵名額。
5.4 線上效果
日常資源使用率由10%提升到40%以上
線上抖動小于5%
5.5 單機排程小結
為了解決三大挑戰,通過完善的各次元優先級隔離政策,将線上提升到高優先級資源次元,我們保障了線上的服務品質穩定;通過離線内部優先級區分及各種管理政策,實作了離線品質的穩定性保障;通過細粒度資源畫像資訊,實作了資源使用的評估與分析,最終實作了混部在阿裡的大規模推廣與應用,進而大量提升了叢集資源使用率,為離線計算節省了大量成本。
6. 展望
從2009到2019年曆經十年的錘煉,伏羲系統仍然在不斷的演化,滿足不斷湧現的業務新需求,引領分布式排程技術的發展。接下來,我們會從以下幾個方面繼續創新:
-- 資源排程FuxiMaster将基于機器學習,實作智能化排程政策和動态精細的資源管理模式,進一步提高叢集資源使用率,提供更強大靈活的分布式叢集資源管理服務。
-- 新一代DAG2.0繼續利用動态性精耕細作,優化各種不同類型的作業;與SQL深入合作,解決線上痛點,推動SQL引擎深度優化,提升性能的同時也讓SQL作業運作更加智能化;探索機器學習場景的DAG排程,改善訓練作業的效率,提升GPU使用率。
-- 資料Shuffle2.0則一方面優化shuffle流程,追求性能、成本、穩定性的極緻,另一方面與DAG 2.0深入結合,提升更多場景;同時探索新的軟硬體架構帶來的新的想象空間。
-- 智能化的精細單機資源管控,基于資源畫像資訊通過對曆史資料分析産生未來趨勢預測,通過多種資源管控手段進行精準的資源控制,實作資源使用率和不同層次服務品質的完美均衡。
最後,我們熱忱歡迎集團各個團隊一起交流探讨,共同打造世界一流的分布式排程系統!
MaxCompute産品官網
https://www.aliyun.com/product/odps更多阿裡巴巴大資料計算技術交流,歡迎掃碼加入“MaxCompute開發者社群”釘釘群。