共同點
定性上講,三者均為 Data Lake 的資料存儲中間層,其資料管理的功能均是基于一系列的 meta 檔案。meta 檔案的角色類似于資料庫的 catalog/wal,起到 schema 管理、事務管理和資料管理的功能。與資料庫不同的是,這些 meta 檔案是與資料檔案一起存放在存儲引擎中的,使用者可以直接看到。這種做法直接繼承了大資料分析中資料對使用者可見的傳統,但是無形中也增加了資料被不小心破壞的風險。一旦某個使用者不小心删了 meta 目錄,表就被破壞了,想要恢複難度非常大。
Meta 檔案包含有表的 schema 資訊。是以系統可以自己掌握 Schema 的變動,提供 Schema 演化的支援。Meta 檔案也有 transaction log 的功能(需要檔案系統有原子性和一緻性的支援)。所有對表的變更都會生成一份新的 meta 檔案,于是系統就有了 ACID 和多版本的支援,同時可以提供通路曆史的功能。在這些方面,三者是相同的。
下面來談一下三者的不同。
Hudi
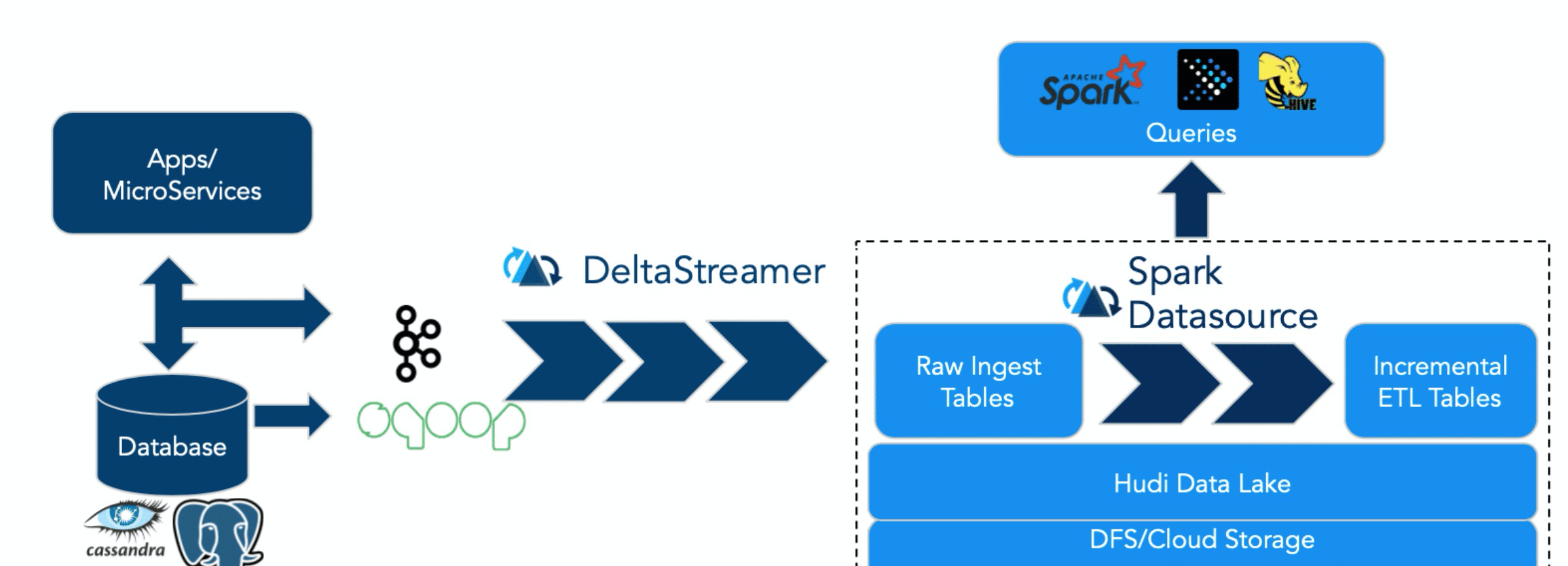
先說 Hudi。Hudi 的設計目标正如其名,Hadoop Upserts Deletes and Incrementals(原為 Hadoop Upserts anD Incrementals),強調了其主要支援 Upserts、Deletes 和 Incremental 資料處理,其主要提供的寫入工具是 Spark HudiDataSource API 和自身提供的 DeltaStreamer,均支援三種資料寫入方式:UPSERT,INSERT 和 BULK_INSERT。其對 Delete 的支援也是通過寫入時指定一定的選項支援的,并不支援純粹的 delete 接口。
其典型用法是将上遊資料通過 Kafka 或者 Sqoop,經由 DeltaStreamer 寫入 Hudi。DeltaStreamer 是一個常駐服務,不斷地從上遊拉取資料,并寫入 hudi。寫入是分批次的,并且可以設定批次之間的排程間隔。預設間隔為 0,類似于 Spark Streaming 的 As-soon-as-possible 政策。随着資料不斷寫入,會有小檔案産生。對于這些小檔案,DeltaStreamer 可以自動地觸發小檔案合并的任務。
在查詢方面,Hudi 支援 Hive、Spark、Presto。
在性能方面,Hudi 設計了
HoodieKey
,一個類似于主鍵的東西。
HoodieKey
有 Min/Max 統計,BloomFilter,用于快速定位 Record 所在的檔案。在具體做 Upserts 時,如果
HoodieKey
不存在于 BloomFilter,則執行插入,否則,确認
HoodieKey
是否真正存在,如果真正存在,則執行 update。這種基于
HoodieKey
+ BloomFilter 的 upserts 方法是比較高效的,否則,需要做全表的 Join 才能實作 upserts。對于查詢性能,一般需求是根據查詢謂詞生成過濾條件下推至 datasource。Hudi 這方面沒怎麼做工作,其性能完全基于引擎自帶的謂詞下推和 partition prune 功能。
Hudi 的另一大特色是支援 Copy On Write 和 Merge On Read。前者在寫入時做資料的 merge,寫入性能略差,但是讀性能更高一些。後者讀的時候做 merge,讀性能查,但是寫入資料會比較及時,因而後者可以提供近實時的資料分析能力。
最後,Hudi 提供了一個名為 run_sync_tool 的腳本同步資料的 schema 到 Hive 表。Hudi 還提供了一個指令行工具用于管理 Hudi 表。
hudi
Iceberg
Iceberg 沒有類似的
HoodieKey
設計,其不強調主鍵。上文已經說到,沒有主鍵,做 update/delete/merge 等操作就要通過 Join 來實作,而 Join 需要有一個 類似 SQL 的執行引擎。Iceberg 并不綁定某個引擎,也沒有自己的引擎,是以 Iceberg 并不支援 update/delete/merge。如果使用者需要 update 資料,最好的方法就是找出哪些 partition 需要更新,然後通過 overwrite 的方式重寫資料。Iceberg 官網提供的 quickstart 以及 Spark 的接口均隻是提到了使用 Spark dataframe API 向 Iceberg 寫資料的方式,沒有提及别的資料攝入方法。至于使用 Spark Streaming 寫入,代碼中是實作了相應的
StreamWriteSupport
,應該是支援流式寫入,但是貌似官網并未明确提及這一點。支援流式寫入意味着有小檔案問題,對于怎麼合并小檔案,官網也未提及。我懷疑對于流式寫入和小檔案合并,可能 Iceberg 還沒有很好的生産 ready,因而沒有提及(純屬個人猜測)。
在查詢方面,Iceberg 支援 Spark、Presto。
Iceberg 在查詢性能方面做了大量的工作。值得一提的是它的 hidden partition 功能。Hidden partition 意思是說,對于使用者輸入的資料,使用者可以選取其中某些列做适當的變換(Transform)形成一個新的列作為 partition 列。這個 partition 列僅僅為了将資料進行分區,并不直接展現在表的 schema 中。例如,使用者有 timestamp 列,那麼可以通過 hour(timestamp) 生成一個 timestamp_hour 的新分區列。timestamp_hour 對使用者不可見,僅僅用于組織資料。Partition 列有 partition 列的統計,如該 partition 包含的資料範圍。當使用者查詢時,可以根據 partition 的統計資訊做 partition prune。
除了 hidden partition,Iceberg 也對普通的 column 列做了資訊收集。這些統計資訊非常全,包括列的 size,列的 value count,null value count,以及列的最大最小值等等。這些資訊都可以用來在查詢時過濾資料。
Iceberg 提供了建表的 API,使用者可以使用該 API 指定表明、schema、partition 資訊等,然後在 Hive catalog 中完成建表。
Delta
我們最後來說 Delta。Delta 的定位是流批一體的 Data Lake 存儲層,支援 update/delete/merge。由于出自 Databricks,spark 的所有資料寫入方式,包括基于 dataframe 的批式、流式,以及 SQL 的 Insert、Insert Overwrite 等都是支援的(開源的 SQL 寫暫不支援,EMR 做了支援)。與 Iceberg 類似,Delta 不強調主鍵,是以其 update/delete/merge 的實作均是基于 spark 的 join 功能。在資料寫入方面,Delta 與 Spark 是強綁定的,這一點 Hudi 是不同的:Hudi 的資料寫入不綁定 Spark(可以用 Spark,也可以使用 Hudi 自己的寫入工具寫入)。
在查詢方面,開源 Delta 目前支援 Spark 與 Presto,但是,Spark 是不可或缺的,因為 delta log 的處理需要用到 Spark。這意味着如果要用 Presto 查詢 Delta,查詢時還要跑一個 Spark 作業。更為蛋疼的是,Presto 查詢是基于
SymlinkTextInputFormat
。在查詢之前,要運作 Spark 作業生成這麼個 Symlink 檔案。如果表資料是實時更新的,意味着每次在查詢之前先要跑一個 SparkSQL,再跑 Presto。這樣的話為何不都在 SparkSQL 裡搞定呢?這是一個非常蛋疼的設計。為此,EMR 在這方面做了改進,支援了 DeltaInputFormat,使用者可以直接使用 Presto 查詢 Delta 資料,而不必事先啟動一個 Spark 任務。
在查詢性能方面,開源的 Delta 幾乎沒有任何優化。Iceberg 的 hidden partition 且不說,普通的 column 的統計資訊也沒有。Databricks 對他們引以為傲的 Data Skipping 技術做了保留。不得不說這對于推廣 Delta 來說不是件好事。EMR 團隊在這方面正在做一些工作,希望能彌補這方面能力的缺失。
Delta 在資料 merge 方面性能不如 Hudi,在查詢方面性能不如 Iceberg,是不是意味着 Delta 一無是處了呢?其實不然。Delta 的一大優點就是與 Spark 的整合能力(雖然目前仍不是很完善,但 Spark-3.0 之後會好很多),尤其是其流批一體的設計,配合 multi-hop 的 data pipeline,可以支援分析、Machine learning、CDC 等多種場景。使用靈活、場景支援完善是它相比 Hudi 和 Iceberg 的最大優點。另外,Delta 号稱是 Lambda 架構、Kappa 架構的改進版,無需關心流批,無需關心架構。這一點上 Hudi 和 Iceberg 是力所不及的。
delta

總結
通過上面的分析能夠看到,三個引擎的初衷場景并不完全相同,Hudi 為了 incremental 的 upserts,Iceberg 定位于高性能的分析與可靠的資料管理,Delta 定位于流批一體的資料處理。這種場景的不同也造成了三者在設計上的差别。尤其是 Hudi,其設計與另外兩個相比差别更為明顯。随着時間的發展,三者都在不斷補齊自己缺失的能力,可能在将來會彼此趨同,互相侵入對方的領地。當然也有可能各自關注自己專長的場景,築起自己的優勢壁壘,是以最終誰赢誰輸還是未知之數。
下表從多個次元對三者進行了總結,需要注意的是此表所列的能力僅代表至 2019 年底。
| Incremental Ingestion | Spark | ||
| ACID updates | HDFS, S3 (Databricks), OSS | HDFS | HDFS, S3 |
| Upserts/Delete/Merge/Update | Delete/Merge/Update | Upserts/Delete | No |
| Streaming sink | Yes | Yes(not ready?) | |
| Streaming source | |||
| FileFormats | Parquet | Avro,Parquet | Parquet, ORC |
| Data Skipping | File-Level Max-Min stats + Z-Ordering (Databricks) | File-Level Max-Min stats + Bloom Filter | File-Level Max-Min Filtering |
| Concurrency control | Optimistic | ||
| Data Validation | Yes (Databricks) | ||
| Merge on read | |||
| Schema Evolution | |||
| File I/O Cache | |||
| Cleanup | Manual | Automatic | |
| Compaction |
注:限于本人水準,文中内容可能有誤,也歡迎讀者批評指正!