InfluxDB應該是目前最專業的時序資料庫,但是InfluxDB Cluster的代碼在0.11版本之後就宣布閉源,作為商業軟體。InfluxDB越來越受歡迎,目前很多公司都是基于其搭建自己的時序資料叢集。最近阿裡雲推出InfluxDB®,是一個基于開源版InfluxDB的商業化時序資料庫,還在研發分布式高可用版本 : 5分鐘了解阿裡時序時空資料庫 , 阿裡雲的自研InfluxDB叢集方案剖析
。
這裡我們基于InfluxDB Cluster v0.11的實作,并結合目前正火的開源HTAP資料庫TiDB,通過對比了解InfluxDB Cluster的解決方案。因為TiDB的分布式方案社群很成熟,很容易獲得專業資料,但是InfluxDB Cluster在其閉源後社群相關資料幾乎沒有更新。
TiKV分布式存儲
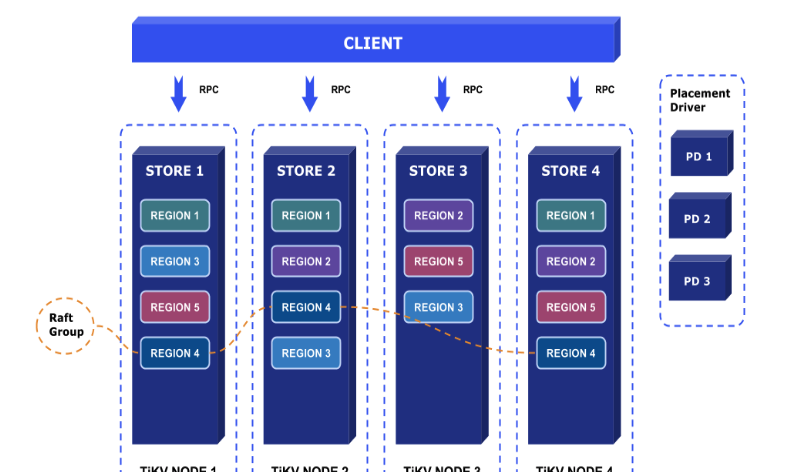
TiKV的資料存儲原理細節建議參考
PingCAP的官方博文。這裡做一個總結:
- TiKV的sharding政策是range sharding,把不同區間的key分到不同的region,當region的資料量超過門檻值時,會發生分裂成為2個region。
- region作為資料存儲的機關,會在叢集中做3副本,3個副本通過raft保證資料複制的一緻性。底層資料存儲使用的是RocksDB,單個TiKV node裡面會起2個RocksDB執行個體,一個用于存儲資料,它會包含多個region,通過在key中加入region ID作為字首來區分,另一個存儲raft log。
- Placement driver在raft的上層,存儲region的路由表,作為索引加速資料定位。
- 再上一層基于MVCC實作單個TiKV node内部的事務。
- 然後就是基于2PC算法實作TiKV 叢集上的分布式事務。
InfluxDB Cluster
在0.11版本中,InfluxDB Cluster架構已經基本完善,其将整體分為2個叢集,一個是真正存儲資料的data cluster,另一個是存儲資料叢集元資訊的meta server。以下涉及的基礎概念和邏輯,可參考本人前面的博文
InfluxDB的存儲引擎演化過程 用TiKV存儲時序資料與InfluxDB對比。InfluxDB Cluster實作原理參考:
- InfluxDB Doc
- InfluxDB Clustering Design – neither strictly CP or AP
- Simplifying InfluxDB: Shards and Retention Policies
下面是基于我的了解,畫的InfluxDB Cluster架構圖:

上圖中上層是InfluxDB中資料邏輯層次結構,下層是真正的實體叢集,存儲資料。
- Retention policy就是前面博文多次提到的InfluxDB的資料過期管理政策,它與database關聯。為database建立retention policy:
CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
DURATION
: 資料儲存期限。比如30d,24h。
REPLICATION
: 見下文。
SHARD DURATION
- 同一retention policy的資料會根據time range進行sharding,把資料分到不同的shard group,每個shard group所包含的時間區間由第1條中的
SHARD DURATION
- 前面的博文提到,根據time range進行sharding會把最新的的資料寫到同一個shard group,造成寫入熱點。InfluxDB通過hash sharding來解決這個問題,每個shard group會包含多個shard,資料通過對
SeriesKey
- Shard是InfluxDB中資料的基本組織形式,每個shard是一個完整的TSM存儲引擎,包含獨立的WAL和資料存儲檔案。每一個shard會被放在多個資料節點上,以保證資料的安全和可用。這裡的副本數可以通過1中的
REPLICATION
同一個shard在不同節點中的多個副本基于Gossip協定實作資料一緻性,這是一個去中心化的一緻性協定。
上圖是meta cluster架構圖。InfluxDB的中繼資料節點存儲了所有的資料庫資訊,包括資料叢集中的邏輯層次,所有retention policy,shard group時間區間配置設定以及shard的hash設定。也就是說中繼資料叢集的作用就是根據資料資訊定位到該資料會存儲在哪個shard。然後再到shard中讀/寫資料。
與TiKV對比
InfluxDB Cluster整體架構與TiKV的存儲相比,meta cluster類似于TiKV的placement driver,用作叢集元資訊的存儲。meta cluster存儲的資訊更全面,其實是資料庫的管理資訊都在裡面。
上層的分布式思想都是一樣的,都是使用range sharding的思想。TiKV直接通過資料條目的key的區間來做sharding,對于資料更新很友好。而InfluxDB則是基于point的時間區間段進行sharding,這便于過期資料清除。InfluxDB還通過
SeriesKey
進行第二次sharding,解決資料寫入熱點問題。
InfluxDB中的shard與TiKV中的region是等價的,都是資料存儲的單元。存在以下不同點:
- 每個TiKV節點隻起一個RocketsDB執行個體用作資料存儲,其包含了節點中所有region。而InfluxDB中,每個shard是一個獨立的TSM,等價于一個獨立的RocketsDB執行個體。
- TiKV中每個region的多個副本之間是使用raft協定,達到強一緻性。InfluxBD的shard副本之間則是使用gossip協定達到最終一緻。
- TiKV的region會在條目太多的時候進行分裂,這跟InfluxDB的hash sharding到不同的shard類似,目的都是為了防止出現熱點。
是以,從資料存儲角度來說,對于分布式CAP理論,TiKV更偏向于CP系統,因為它完全相容傳統RDBMS,支援事務是必備的。而InfluxDB Cluster主要目标是提供高可用,是一個偏向于AP系統。這是因為面向前面的博文中所說的時序資料的特征,讓高頻率資料能夠及時寫入,而不支援事務。但是,meta cluster則是一個CP系統,保證資料庫資訊的完全一緻,這也是為下層資料存儲服務的。