一、實驗目的:
在DataWorks業務流程開發過程。一個業務流程通常是由很多個資料同步、資料開發節點組成的。這很多個業務節點的上下遊節點的連接配接通過執行順序先後進行連接配接,系統自動就行上下遊解析。這裡主要用于測試在一個業務流程過程中根據業務需求進行節點連接配接之後自動解析上下遊是否會發生錯誤。
二、實驗步驟:
1、建立一個業務流程
2、建立一個start節點
3、建立五個資料同步節點
4、建立五個資料開發節點
5、根據業務需求進行節點上下文連線,如下圖所示:
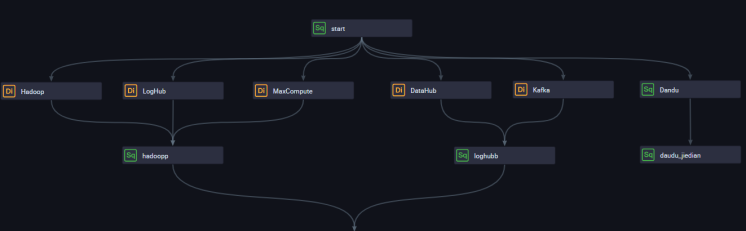
6、配置start節點的上遊為工作空間根節點,點選送出
7、檢查每個節點的上下遊節點通過連接配接之後自動解析的結果和業務需求是否一緻。
業務需求:
(1)start節點:
工作空間根節點--->start節點--->LogHub(資料同步)、MaxCompute(資料同步)、Hadoop(資料同步)、DataHub(資料同步)、Kafka(資料同步)、Dandu(資料開發)

(2)Hadoop(資料同步)
start--->Hadoop(資料同步)--->hadoopp(資料開發)
(3)LogHub(資料同步)
start--->LogHub(資料同步)--->hadoopp(資料開發)
(4)MaxCompute(資料同步)
start--->MaxCompute(資料同步)--->hadoopp(資料開發)
(5)DataHub(資料同步)
start--->DataHub(資料同步)--->loghubb(資料開發)
(6)Kafka(資料同步)
start--->Kafka(資料同步)--->loghubb(資料開發)
(7)Dandu(資料開發)
start--->Dandu(資料開發)--->dandu_jiedian(資料開發)
(8)hadoopp(資料開發)
Hadoop(資料同步)、LogHub(資料同步)、MaxCompute(資料同步)--->hadoopp(資料開發)--->huiju_jiedian(資料開發)
(9)loghubb(資料開發)
DataHub(資料同步)、Kafka(資料同步)--->loghubb(資料開發)--->huiju_jiedian(資料開發)
(10)dandu_jiedian(資料開發)
Dandu(資料開發)--->dandu_jiedian(資料開發)
(11)huiju_jiedian(資料開發)
loghubb(資料開發)、hadoopp(資料開發)--->huiju_jiedian(資料開發)
三、實驗結果:
檢測自動解析節點上下文依賴和業務需求的依賴關系是一緻的。
四、實驗總結:
在排程系統中,每一個工作空間中預設會建立一個projectname_root節點作為根節點。如果本節點沒有上遊節點,可以直接依賴根節點。
依賴屬性中配置節點的上遊依賴,表示即使目前節點的執行個體已經到定時時間,也必須等待上遊節點的執行個體運作完畢,才會觸發運作。
點選連結加入 MaxCompute開發者社群2群
https://h5.dingtalk.com/invite-page/index.html?bizSource=____source____&corpId=dingb682fb31ec15e09f35c2f4657eb6378f&inviterUid=E3F28CD2308408A8&encodeDeptId=0054DC2B53AFE745或掃碼加入