作者:58沈劍
問題抽象:
(1)使用者會員系統;
(2)使用者會有分數流水,每個月要做一次分數統計,對不同分數等級的會員做不同業務處理;
資料假設:
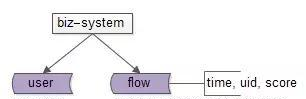
(1)假設使用者在100w級别;
(2)假設使用者日均1條流水,也就是說日增流水資料量在100W級别,月新增流水在3kW級别,3個月流水資料量在億級别;
常見解決方案:
用一個定時任務,每個月的第一天計算一次。
//(1)查詢出所有使用者
uids[] = select uid from t_user;
//(2)周遊每個使用者
foreach $uid in uids[]{
//(3)查詢使用者3個月内分數流水
scores[]= select score from t_flow
where uid=$uid and time=[3個月内];
//(4)周遊分數流水
foreach $score in scores[]{
//(5)計算總分數
sum+= $score;
}
//(6)根據分數做業務處理
switch(sum)
更新降級,發優惠券,發獎勵;
}
一個月執行一次的定時任務,會存在什麼問題?
計算量很大,處理的資料量很大,耗時很久,按照水友的說法,需要1-2天。
畫外音:外層循環100W級别使用者;内層循環9kW級别流水;業務處理需要10幾次資料庫互動。
可不可以多線程并行處理?
可以,每個使用者的流水處理不耦合。
改為多線程并行處理,例如按照使用者拆分,會存在什麼問題?
每個線程都要通路資料庫做業務處理,資料庫有可能扛不住。
這類問題的優化方向是:
(1)同一份資料,減少重複計算次數;
(2)分攤CPU計算時間,盡量分散處理,而不是集中處理;
(3)減少單次計算資料量;
如何減少同一份資料,重複計算次數?

如上圖,假設每一個方格是1個月的分數流水資料(約3kW)。
3月底計算時,要查詢并計算1月,2月,3月三個月的9kW資料;
4月底計算時,要查詢并計算2月,3月,4月三個月的9kW資料;
…
會發現,2月和3月的資料(粉色部分),被重複查詢和計算了多次。
畫外音:該業務,每個月的資料會被計算3次。
新增月積分流水彙總表,每次隻計算當月增量:
flow_month_sum(month, uid, flow_sum)
(1)每到月底,隻計算當月分數,資料量減少到1/3,耗時也減少到1/3;
(2)同時,把前2個月流水加和,就能得到最近3個月總分數(這個動作幾乎不花時間);
畫外音:該表的數量級和使用者表資料量一緻,100w級别。
這樣一來,每條分數流水隻會被計算一次。
如何分攤CPU計算時間,減少單次計算資料量呢?
業務需求是一個月重新計算一次分數,但一個月集中計算,資料量太大,耗時太久,可以将計算分攤到每天。
如上圖,月積分流水彙總表,更新為,日積分流水彙總表。
把每月1次集中計算,分攤為30次分散計算,每次計算資料量減少到1/30,就隻需要花幾十分鐘處理了。
甚至,每一個小時計算一次,每次計算資料量又能減少到1/24,每次就隻需要花幾分鐘處理了。
雖然時間縮短了,但畢竟是定時任務,能不能實時計算分數流水呢?
每天隻新增100w分數流水,完全可以實時累加計算“日積分流水彙總”。
使用DTS(或者canal)增加一個分數流水表的監聽,當使用者的分數變化時,實時進行日分數流水累加,将1小時一次的定時任務計算,均勻分攤到“每時每刻”,每天新增100w流水,資料庫寫壓力每秒鐘10多次,完全扛得住。
畫外音:如果不能使用DTS/canal,可以使用MQ。
總結,對于這類一次性集中處理大量資料的定時任務,優化思路是:
(2)分攤CPU計算時間,盡量分散處理(甚至可以實時),而不是集中處理;
希望大家有所啟示,思路比結論重要。
最後
歡迎大家一起交流,喜歡文章記得點個贊喲,感謝支援!